AWS Big Data Blog
Improved speed and scalability in Amazon Redshift
Since Amazon Redshift launched in 2012, its focus has always been on providing you with the best possible performance, at scale, and at the lowest possible cost. For most organizations across the globe, the amount of data going into their data warehouse is growing exponentially, and the number of people who want insights from that data increases daily. Because of this, Amazon Redshift is continually innovating to handle this growing volume of data and demand for insights.
Amazon Redshift delivers fast performance, at scale, for the most demanding workloads. Getting there was not easy, and it takes consistent investment across a variety of technical focus areas to make this happen. This post breaks down what it takes to build the world’s fastest cloud data warehouse.
Redshift’s performance investments are based on a broad spectrum of needs and uses the extensive fleet telemetry data from tens of thousands of customers to guide development work. Your needs may vary based on a variety of factors, including the size of your data warehouse, the number of concurrent users, the skillset of those users, and workload characteristics such as frequency of usage and query latency requirements.
Based on this, Amazon Redshift has performance investments anchored in four key areas:
- Out-of-the-box performance – Amazon Redshift is over twice as fast out-of-the-box than it was 6 months ago, and keeps getting faster without any additional manual optimization and tuning
- Automatic optimizations – Amazon Redshift is self-learning, self-optimizing, and constantly adapts to your actual workload to deliver the best possible performance
- Scalability – Amazon Redshift can boost throughput to be 35 times greater to support increases in concurrent users and scales linearly for a wide range of workloads
- Price-performance – Amazon Redshift provides predictable performance at significantly lower total cost than other data warehouse solutions by optimizing resource utilization
Out-of-the-box performance
Amazon Redshift has always enabled you to manually tune workload performance based on statically partitioning memory and specifying the number of concurrent queries. Amazon Redshift also uses advanced machine learning (ML) algorithms to tune configuration settings automatically for optimal data warehouse performance.
These algorithms are extremely effective because they are trained with real-world telemetry data generated from processing over two exabytes of data a day. Additionally, because Amazon Redshift has more customers than any other cloud data warehouse, the telemetry data makes the configuration recommendations from the ML algorithms even more accurate.
In addition, Amazon Redshift Advisor guides optimization by recommending sort keys, distribution keys, and more. However, if you want to override the learning, self-tuning behavior of Amazon Redshift, you still have fine-grained control.
The out-of-the-box performance of Amazon Redshift is continually improving. In November 2019, our Cloud Data Warehouse benchmark[1] showed that the out-of-the-box performance of Amazon Redshift was twice as fast as 6 months ago. This ongoing improvement in performance is the culmination of many technical innovations. This post presents three improvements that have had the most impact.
Improved compression
Amazon Redshift uses AZ64, a novel compression encoding, which delivers high compression ratios and significantly improved query performance. With AZ64, you no longer need to make the trade-off between storage size and performance. AZ64 compresses data, on average, 35% more than the popular, high-performance LZO algorithm, and processes the data 40% faster. AZ64 achieves this by efficiently compressing small groups of data values and uses CPU vector instructions and single instruction, multiple data (SIMD) for parallel processing of AZ64-encoded columns. To benefit from this, you simply select the data type for each column, and Amazon Redshift chooses the compression encoding method. Five months after launch, the AZ64 encoding has become the fourth most popular encoding option in Amazon Redshift with millions of columns.
Efficient large-scale join operations
When complex queries join large tables, massive amounts of data transfers over the network for the join processing on the Amazon Redshift compute nodes. This used to create network bottlenecks that impacted query performance.
Amazon Redshift now uses distributed bloom filters to enable high-performance joins for such workloads. Distributed bloom filters efficiently filter rows at the source that do not match the join relation, which greatly reduces the amount of data transferred over the network. Across the fleet, we see millions of selective bloom filters deployed each day, with some of them filtering more than one billion rows. This removes the network from being the bottleneck and improves overall query performance. Amazon Redshift automatically determines what queries are suitable for this optimization and adapts the optimization at runtime. In addition, Amazon Redshift uses CPU cache-optimized processing to make query execution more efficient for large-scale joins and aggregations. Together, these features improve performance for over 70% of the queries that Amazon Redshift processes daily.
Enhanced query planning
Query planning determines the quickest way to process a given query by evaluating costs associated with various query plans. Costs include many factors, for example, the number of I/O operations required, amount of disk buffer space, time to read from disk, parallelism for the query, and tables statistics such as number of rows and number of distinct values of a column being fresh and relevant.
The Amazon Redshift query planner factors in the capabilities of modern hardware, including the network stack, to take full advantage of the performance that the hardware offers. Its statistic collection process is automated, and it computes statistics by using algorithms like HyperLogLog (HLL), which improves the quality of statistics and therefore enables the cost-based planner to make better choices.
Automatic optimizations
Amazon Redshift uses ML techniques and advanced graph algorithms to continuously improve performance. Different workloads have different data access patterns, and Amazon Redshift observes the workload to learn and adapt. It automatically adjusts data layout, distribution keys, and query plans to provide optimal performance for a given workload.
The automatic optimizations in Amazon Redshift make intelligent decisions, such as how to distribute data across nodes, which datasets are frequently queried together and should be co-located, how to sort data, and how many parallel and concurrent queries should run on the system based on the complexity of the query. Amazon Redshift automatically adjusts these configurations to optimize throughput and performance as you use the data warehouse. To make sure these optimizations do not interrupt your workload, Amazon Redshift runs them incrementally and only during the periods when clusters have low utilization.
For maintenance operations, Amazon Redshift reduces the amount of compute resources required by operating only on frequently accessed tables and portions within those tables. Amazon Redshift prioritizes which portions of the table to operate on by analyzing query patterns. When relevant, it provides prescriptive guidance through recommendations in Amazon Redshift Advisor. You can then evaluate and apply those recommendations as needed.
AWS also constantly evaluates and assesses how effective its ML-based self-learning systems are in delivering fast query performance when compared to traditional methods such as expert human tuning.
Amazon Redshift has been adding automatic optimizations for years. The following timeline shows some of the automatic optimizations delivered over the last 12 months.
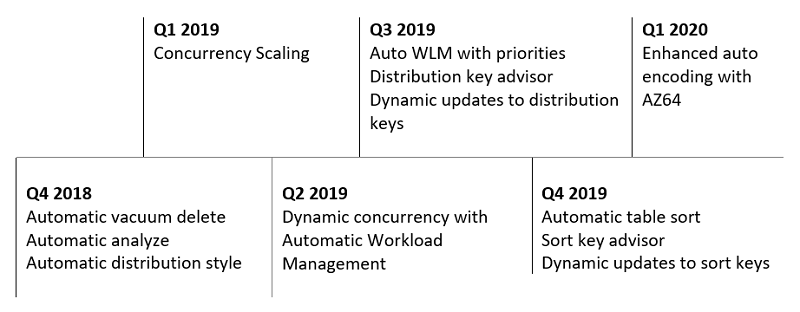
For more information about specific optimizations, see the following posts about
automatic VACUUM DELETE, automatic ANALYZE, distribution key recommendations, sort key recommendations, automatic table sort, and automatic distribution style.
Scalability
Amazon Redshift can boost throughput by more than 35 times to support increases in concurrent users, and scales linearly for simple and mixed workloads.
Scaling to support a growing number of users
As the number of users accessing the data warehouse grows, you should not experience delays in your query responses. Most of the time, your workloads are not predictable and can vary throughout the day. Traditional data warehouses are typically provisioned for peak usage to avoid delays and missed SLAs, and you end up paying for resources that you are not fully using.
Concurrency Scaling in Amazon Redshift allows the data warehouse to handle spikes in workloads while maintaining consistent SLAs by elastically scaling the underlying resources as needed. Amazon Redshift continuously monitors the designated workload. If the queries start to get backlogged because of bursts of user activity, Amazon Redshift automatically adds transient cluster capacity and routes the requests to these new clusters. This transient capacity is available in a few seconds, so your queries continue to be served with low latency. Amazon Redshift removes the additional transient capacity automatically when activity reduces on the cluster.
You can choose if you want to elastically scale for certain workloads and by how much with a simple one-step configuration. Every 24 hours that the Amazon Redshift main cluster is in use, you accrue a 1-hour credit. This makes concurrency scaling free for more than 97% of use cases.
With the ability to automatically add and remove additional capacity, Amazon Redshift data warehouses can improve overall throughput by over 35 times. This post demonstrates how far you can dynamically allocate more compute power to satisfy the demands of concurrent users with the following experiment. First, take a baseline measurement using the Cloud Data Warehouse benchmark and five concurrent users. You can then enable Concurrency Scaling and add more and more users with each iteration. As soon as Amazon Redshift detects queuing, it allocates additional scaling clusters automatically. Ultimately, this experiment ran over 200 concurrent queries on Amazon Redshift and generated more than 35 times greater throughput. This many concurrently executing queries represents a concurrent user population of several thousand. This demonstrates how you can support virtually unlimited concurrent users on your Amazon Redshift data warehouses.
The scaling for concurrent users is also linear. You get consistent increases in performance with every extra dollar spent on the Concurrency Scaling clusters. This helps to keep data warehouse costs predictable as business needs grow. With Concurrency Scaling, AWS can perform benchmark tests with tens of thousands of queries per hour, with hundreds of queries running concurrently and providing linear scale. This represents a real-world workload in enterprises with thousands of concurrent users connecting to the data warehouse.
Scaling while running multiple mixed workloads
As data warehouses grow over time, the number and complexity of the workloads that run on the data warehouse also increase. For example, if you migrate from an on-premises data warehouse to Amazon Redshift, you might first run traditional analytics workloads, and eventually bring more operational and real-time data into the cluster to build new use cases and applications. To scale any data warehouse effectively, you must be able to prioritize and manage multiple types of workloads concurrently. Automatic workload management (WLM) and query priorities are two recent capabilities added to Amazon Redshift that enable you to do just that.
Automatic WLM makes sure that you use cluster resources efficiently, even with dynamic and unpredictable workloads. With automatic WLM, Amazon Redshift uses ML to classify incoming queries based on their memory and processing requirements and routes them to appropriate internal queues to start executing in parallel. Amazon Redshift dynamically adjusts the number of queries to execute in parallel to optimize overall throughput and performance. When queries that require large amounts of resources are in the system (for example, hash joins between large tables), the concurrency is lower. When you submit lighter queries (such as inserts, deletes, or simple aggregations), concurrency is higher. There is a feedback loop to continuously monitor system utilization and regulate admission into the cluster.
However, not all queries may be equally important to you; the performance of one workload or set of users might be more important than others. Query priorities in Amazon Redshift address this. You can give higher-priority workloads preferential treatment, including more resources during busy times, for consistent query performance. Amazon Redshift workload management uses intelligent algorithms to make sure that lower-priority queries continue to make progress and don’t stall.
You can combine Amazon Redshift Concurrency Scaling and automatic WLM with query priorities to solve complex data warehouse use cases. For example, the following table summarizes an Amazon Redshift configuration that effectively mixes ETL with analytics workloads.
| WLM queue | Queue priority | Concurrency Scaling | Notes |
| ETL | High | Off | When ETL runs, it gets the highest priority |
| BI queries | Normal | On | When BI workload suddenly increases, Concurrency Scaling adds capacity to maintain user SLAs |
| One-time or exploratory queries | Low | Off | Cluster offers analytic access for casual users and data scientists when resources are available |
For this use case, and many more, you can maintain SLAs, achieve efficiencies with your cluster utilization, and get sufficient flexibility to invest according to business priorities.
Price performance
You can measure price performance by calculating both the total cost of the computing service consumed and the total amount of computing work performed. Maximum performance for minimum cost gives you the best price performance.
As your data warehouses grow, Amazon Redshift gets more efficient. It moderates cost increases and keeps costs predictable, even as your needs grow. This sets Amazon Redshift apart from others in the market that increase in price much more as the number of users grows.
The investments in automatic optimizations, out-of-the-box performance, and scale all contribute to the unbeatable price performance that Amazon Redshift offers. When you compare typical customer quotes and investments, you find that Amazon Redshift costs 50% –75% less than other cloud data warehouses.
Measuring performance
AWS measures performance, throughput, and price-performance on a nightly basis. AWS also runs larger and more comprehensive benchmarks regularly to make sure the tests extend beyond your current needs. For benchmark results to be useful, they need to be well defined and easily reproducible. AWS uses the Cloud DW benchmark based on current TPC-DS and TPC-H benchmarks without any query or data modifications and compliant with TPC rules and requirements.
It’s important that anyone can reproduce these benchmarks; you can download the benchmark codes and scripts from GitHub and the accompanying dataset from a public Amazon S3 bucket.
Summary
Amazon Redshift is self-learning, self-optimizing, and consistently uses telemetry of the actual workload to deliver the best possible performance. Amazon Redshift is more than twice as fast out-of-the-box than it was 6 months ago, and keeps getting faster without any manual optimization and tuning. Amazon Redshift can boost throughput by more than 35 times to support increases in concurrent users and scales linearly for simple and mixed workloads.
In addition to software improvements, AWS continues to build data warehouses on the best hardware available. The new RA3 node type with managed storage features high bandwidth networking and sizable high-performance SSDs as local caches. RA3 nodes use your workload patterns and advanced data management techniques, such as automatic fine-grained data eviction and intelligent data pre-fetching, to deliver the performance of local SSD while scaling storage automatically to Amazon S3. The hardware-based performance improvements in preview with AQUA (Advanced Query Accelerator) bring even more dramatic performance improvements and drive costs down with a new distributed and hardware accelerated cache.
These performance improvements are the cumulative result of years of strategic and sustained product investment and technical innovation across multiple areas such as automatic optimizations, out-of-the-box performance, and scalability. Additionally, price-performance remains a priority so you receive the best value.
Each dataset and workload has unique characteristics, and a proof of concept is the best way to understand how Amazon Redshift performs in your unique situation. When running your own proof of concept, it’s important that you focus on the right metrics—query throughput (number of queries per hour) and price-performance for your workload.
[1]
You can make a data-driven decision by requesting assistance with a proof of concept or working with a system integration and consulting partner. It’s also important to consider not only how a data warehouse performs with your current needs, but also its future performance with increasingly complex workloads, datasets, and users.
To stay up-to-date with the latest developments in Amazon Redshift, subscribe to the What’s New in Amazon Redshift RSS feed.
———
[1] The TPC Benchmark, TPC-DS and TPC-H are trademarks of the Transaction Processing Performance Council www.tpc.org
About the Authors
 Naresh Chainani is a Senior Software Development Manager at Amazon Redshift where he leads Query Processing, Query Performance, Distributed Systems and Workload Management with a strong team. Naresh is passionate about building high-performance databases to enable customers to gain timely insights and make critical business decisions. In his spare time, Naresh enjoys reading and playing tennis.
Naresh Chainani is a Senior Software Development Manager at Amazon Redshift where he leads Query Processing, Query Performance, Distributed Systems and Workload Management with a strong team. Naresh is passionate about building high-performance databases to enable customers to gain timely insights and make critical business decisions. In his spare time, Naresh enjoys reading and playing tennis.
 Berni Schiefer is a Senior Development Manager for EMEA at Amazon Web Services, leading the Amazon Redshift development team in Berlin, Germany. The Berlin team focuses on Redshift Performance and Scalability, SQL Query Compilation, Spatial Data support, and Redshift Spectrum. Previously, Berni was an IBM Fellow working in the area of Private Cloud, Db2, Db2 Warehouse, BigSQL, with a focus on SQL-based engines, query optimization and performance.
Berni Schiefer is a Senior Development Manager for EMEA at Amazon Web Services, leading the Amazon Redshift development team in Berlin, Germany. The Berlin team focuses on Redshift Performance and Scalability, SQL Query Compilation, Spatial Data support, and Redshift Spectrum. Previously, Berni was an IBM Fellow working in the area of Private Cloud, Db2, Db2 Warehouse, BigSQL, with a focus on SQL-based engines, query optimization and performance.
 Neeraja Rentachintala is a seasoned Product Management and GTM leader at Amazon Web Services, bringing over 20 years of experience in Product Vision, Strategy and Leadership roles in industry-leading data products and platforms. During her career, she delivered products in Analytics, Big data, Databases, Data and Application Integration, AI/ML serving Fortune 500 enterprise and ventures including MapR (acquired by HPE), Microsoft, Oracle, Informatica and Expedia.com. Currently Neeraja is a Principal Product Manager with Amazon Web Services building Amazon Redshift – the world’s most popular, highest performance and most scalable cloud data warehouse. Neeraja earned a Bachelor of Technology in Electronics and Communication Engineering from the National Institute of Technology in India and various business program certifications from the University of Washington, MIT Sloan School of Management and Stanford University.
Neeraja Rentachintala is a seasoned Product Management and GTM leader at Amazon Web Services, bringing over 20 years of experience in Product Vision, Strategy and Leadership roles in industry-leading data products and platforms. During her career, she delivered products in Analytics, Big data, Databases, Data and Application Integration, AI/ML serving Fortune 500 enterprise and ventures including MapR (acquired by HPE), Microsoft, Oracle, Informatica and Expedia.com. Currently Neeraja is a Principal Product Manager with Amazon Web Services building Amazon Redshift – the world’s most popular, highest performance and most scalable cloud data warehouse. Neeraja earned a Bachelor of Technology in Electronics and Communication Engineering from the National Institute of Technology in India and various business program certifications from the University of Washington, MIT Sloan School of Management and Stanford University.