AWS Big Data Blog
Ingest streaming data to Apache Hudi tables using AWS Glue and Apache Hudi DeltaStreamer
In today’s world with technology modernization, the need for near-real-time streaming use cases has increased exponentially. Many customers are continuously consuming data from different sources, including databases, applications, IoT devices, and sensors. Organizations may need to ingest that streaming data into data lakes built on Amazon Simple Storage Service (Amazon S3). You may also need to achieve analytics and machine learning (ML) use cases in near-real time. To ensure consistent results in those near-real-time streaming use cases, incremental data ingestion and atomicity, consistency, isolation, and durability (ACID) properties on data lakes have been a common ask.
To address such use cases, one approach is to use Apache Hudi and its DeltaStreamer utility. Apache Hudi is an open-source data management framework designed for data lakes. It simplifies incremental data processing by enabling ACID transactions and record-level inserts, updates, and deletes of streaming ingestion on data lakes built on top of Amazon S3. Hudi is integrated with well-known open-source big data analytics frameworks, such as Apache Spark, Apache Hive, Presto, and Trino, as well as with various AWS analytics services like AWS Glue, Amazon EMR, Amazon Athena, and Amazon Redshift. The DeltaStreamer utility provides an easy way to ingest streaming data from sources like Apache Kafka into your data lake.
This post describes how to run the DeltaStreamer utility on AWS Glue to read streaming data from Amazon Managed Streaming for Apache Kafka (Amazon MSK) and ingest the data into S3 data lakes. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. With AWS Glue, you can create Spark, Spark Streaming, and Python shell jobs to extract, transform, and load (ETL) data. You can create AWS Glue Spark streaming ETL jobs using either Scala or PySpark that run continuously, consuming data from Amazon MSK, Apache Kafka, and Amazon Kinesis Data Streams and writing it to your target.
Solution overview
To demonstrate the DeltaStreamer utility, we use fictional product data that represents product inventory including product name, category, quantity, and last updated timestamp. Let’s assume we stream the data from data sources to an MSK topic. Now we want to ingest this data coming from the MSK topic into Amazon S3 so that we can run Athena queries to analyze business trends in near-real time.
The following diagram provides the overall architecture of the solution described in this post.
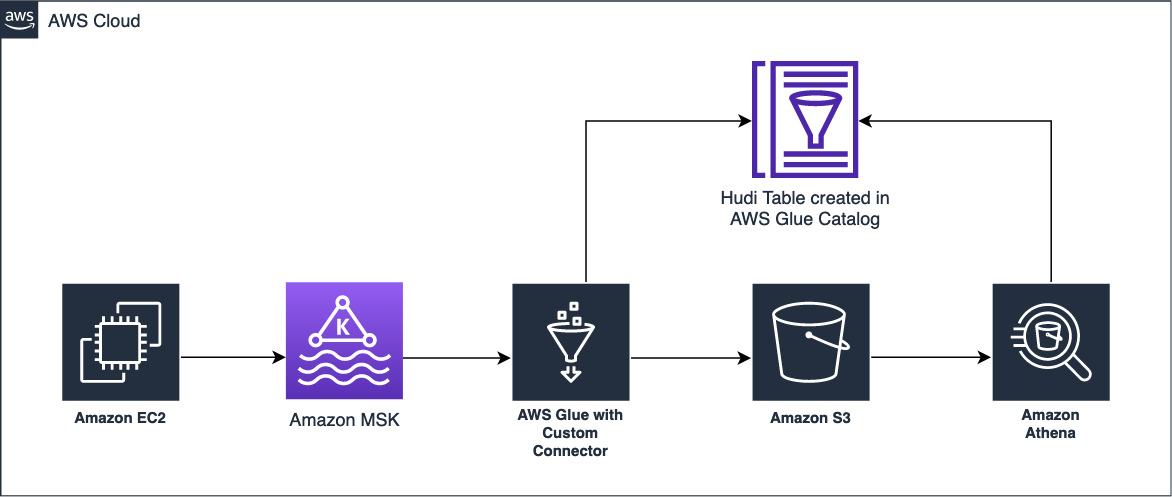
To simulate application traffic, we use Amazon Elastic Compute Cloud (Amazon EC2) to send sample data to an MSK topic. Amazon MSK is a fully managed service that makes it easy to build and run applications that use Apache Kakfa to process streaming data. To consume the streaming data from Amazon MSK, we set up an AWS Glue streaming ETL job that uses the Apache Hudi Connector 0.10.1 for AWS Glue 3.0, with the DeltaStreamer utility to write the ingested data to Amazon S3. The Apache Hudi Connector 0.9.0 for AWS Glue 3.0 also supports the DeltaStreamer utility.
As the data is being ingested, the AWS Glue streaming job writes the data into the Amazon S3 base path. The data in Amazon S3 is cataloged using the AWS Glue Data Catalog. We then use Athena, which is an interactive query service, to query and analyze the data using standard SQL.
Prerequisites
We use an AWS CloudFormation template to provision some resources for our solution. The template requires you to select an EC2 key pair. This key is configured on an EC2 instance that lives in the public subnet. We use this EC2 instance to ingest data to the MSK cluster running in a private subnet. Make sure you have a key in the AWS Region where you deploy the template. If you don’t have one, you can create a new key pair.
Create the Apache Hudi connection
To add the Apache Hudi Connector for AWS Glue, complete the following steps:
- On the AWS Glue Studio console, choose Connectors.
- Choose Go to AWS Marketplace.
- Search for and choose Apache Hudi Connector for AWS Glue.
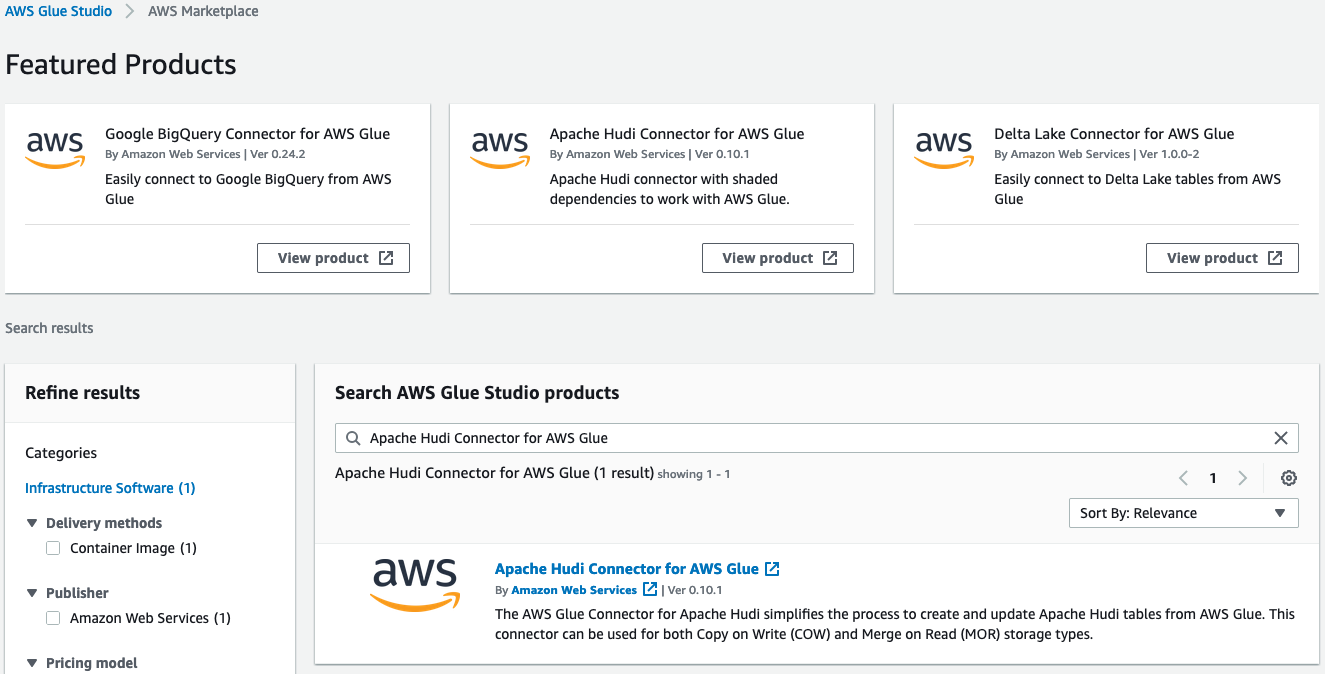
- Choose Continue to Subscribe.

- Review the terms and conditions, then choose Accept Terms.

After you accept the terms, it takes some time to process the request.
 When the subscription is complete, you see the Effective date populated next to the product.
When the subscription is complete, you see the Effective date populated next to the product. - Choose Continue to Configuration.

- For Fulfillment option, choose Glue 3.0.
- For Software version, choose 0.10.1.
- Choose Continue to Launch.
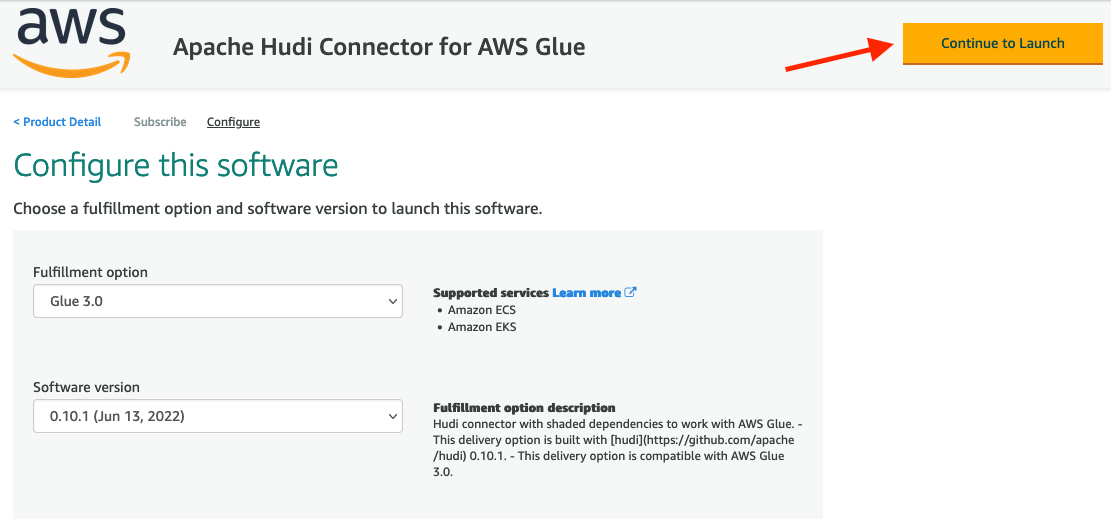
- Choose Usage instructions, and then choose Activate the Glue connector from AWS Glue Studio.

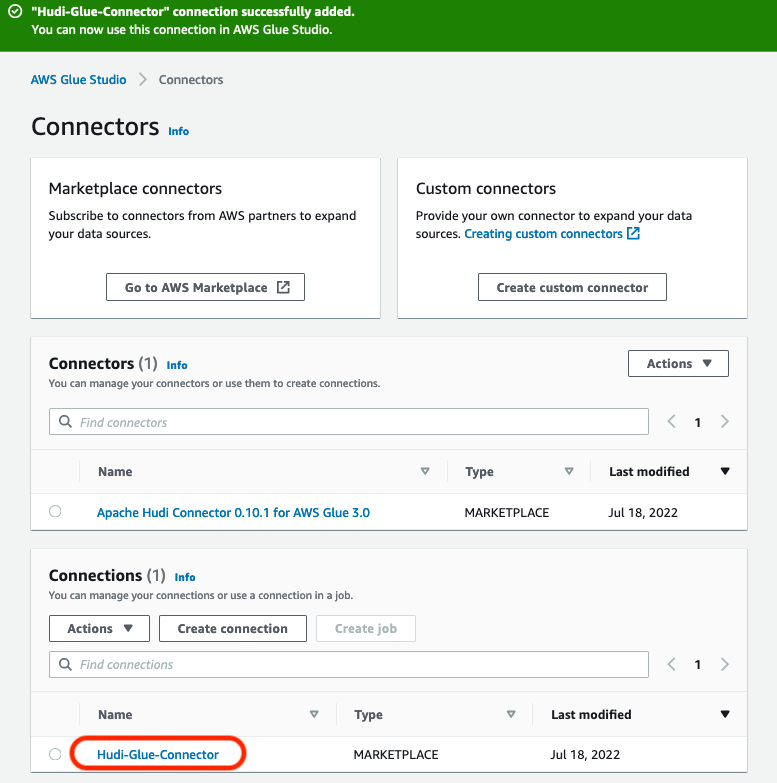
You’re redirected to AWS Glue Studio. - For Name, enter
Hudi-Glue-Connector. - Choose Create connection and activate connector.

A message appears that the connection was successfully created. Verify that the connection is visible on the AWS Glue Studio console.
Launch the CloudFormation stack
For this post, we provide a CloudFormation template to create the following resources:
- VPC, subnets, security groups, and VPC endpoints
- AWS Identity and Access Management (IAM) roles and policies with required permissions
- An EC2 instance running in a public subnet within the VPC with Kafka 2.12 installed and with the source data initial load and source data incremental load JSON files
- An Amazon MSK server running in a private subnet within the VPC
- An AWS Glue Streaming DeltaStreamer job to consume the incoming data from the Kafka topic and write it to Amazon S3
- Two S3 buckets: one of the buckets stores code and config files, and other is the target for the AWS Glue streaming DeltaStreamer job
To create the resources, complete the following steps:
- Choose Launch Stack:

- For Stack name, enter
hudi-deltastreamer-glue-blog. - For ClientIPCIDR, enter the IP address of your client that you use to connect to the EC2 instance.
- For HudiConnectionName, enter the AWS Glue connection you created earlier (
Hudi-Glue-Connector). - For KeyName, choose the name of the EC2 key pair that you created as a prerequisite.
- For VpcCIDR, leave as is.
- Choose Next.
- Choose Next.
- On the Review page, select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
- Choose Create stack.
After the CloudFormation template is complete and the resources are created, the Outputs tab shows the following information:
- HudiDeltastreamerGlueJob – The AWS Glue streaming job name
- MSKCluster – The MSK cluster ARN
- PublicIPOfEC2InstanceForTunnel – The public IP of the EC2 instance for tunnel
- TargetS3Bucket – The S3 bucket name

Create a topic in the MSK cluster
Next, SSH to Amazon EC2 using the key pair you created and run the following commands:
- SSH to the EC2 instance as ec2-user:
You can get the KeyName value on the Parameters tab and the public IP of the EC2 instance for tunnel on the Outputs tab of the CloudFormation stack.
- For the next command, retrieve the bootstrap server endpoint of the MSK cluster by navigating to
msk-source-clusteron the Amazon MSK console and choosing View client information.

- Run the following command to create the topic in the MSK cluster
hudi-deltastream-demo: - Ingest the initial data from the
deltastreamer_initial_load.jsonfile into the Kafka topic:
The following is the schema of a record ingested into the Kafka topic:
The schema uses the following parameters:
- id – The product ID
- category – The product category
- ts – The timestamp when the record was inserted or last updated
- name – The product name
- quantity – The available quantity of the product in the inventory
The following code gives an example of a record:
Start the AWS Glue streaming job
To start the AWS Glue streaming job, complete the following steps:
- On the AWS Glue Studio console, find the job with the value for
HudiDeltastreamerGlueJob. - Choose the job to review the script and job details.
- On the Job details tab, replace the value of the
--KAFKA_BOOTSTRAP_SERVERSkey with the Amazon MSK bootstrap server’s private endpoint.

- Choose Save to save the job settings.
- Choose Run to start the job.

When the AWS Glue streaming job runs, the records from the MSK topic are consumed and written to the target S3 bucket created by AWS CloudFormation. To find the bucket name, check the stack’s Outputs tab for the TargetS3Bucket key value.

The data in Amazon S3 is stored in Parquet file format. In this example, the data written to Amazon S3 isn’t partitioned, but you can enable partitioning by specifying hoodie.datasource.write.partitionpath.field=<column_name> as the partition field and setting hoodie.datasource.write.hive_style_partitioning to True in the Hudi configuration property in the AWS Glue job script.
In this post, we write the data to a non-partitioned table, so we set the following two Hudi configurations:
hoodie.datasource.hive_sync.partition_extractor_class is set to org.apache.hudi.hive.NonPartitionedExtractorhoodie.datasource.write.keygenerator.class is set to org.apache.hudi.keygen.NonpartitionedKeyGenerator
DeltaStreamer options and configuration
DeltaStreamer has multiple options available; the following are the options set in the AWS Glue streaming job used in this post:
- continuous – DeltaStreamer runs in continuous mode running source-fetch.
- enable-hive-sync – Enables table sync to the Apache Hive Metastore.
- schemaprovider-class – Defines the class for the schema provider to attach schemas to the input and target table data.
- source-class – Defines the source class to read data and has many built-in options.
- source-ordering-field – The field used to break ties between records with the same key in input data. Defaults to ts (the Unix timestamp of record).
- target-base-path – Defines the path for the target Hudi table.
- table-type – Indicates the Hudi storage type to use. In this post, it’s set to
COPY_ON_WRITE.
The following are some of the important DeltaStreamer configuration properties set in the AWS Glue streaming job:
The configuration contains the following details:
- hoodie.deltastreamer.schemaprovider.source.schema.file – The schema of the source record
- hoodie.deltastreamer.schemaprovider.target.schema.file – The schema for the target record.
- hoodie.deltastreamer.source.kafka.topic – The source MSK topic name
- bootstap.servers – The Amazon MSK bootstrap server’s private endpoint
- auto.offset.reset – The consumer’s behavior when there is no committed position or when an offset is out of range
Hudi configuration
The following are some of the important Hudi configuration options, which enable us to achieve in-place updates for the generated schema:
- hoodie.datasource.write.recordkey.field – The record key field. This is the unique identifier of a record in Hudi.
- hoodie.datasource.write.precombine.field – When two records have the same record key value, Apache Hudi picks the one with the largest value for the pre-combined field.
- hoodie.datasource.write.operation – The operation on the Hudi dataset. Possible values include UPSERT, INSERT, and BULK_INSERT.
AWS Glue Data Catalog table
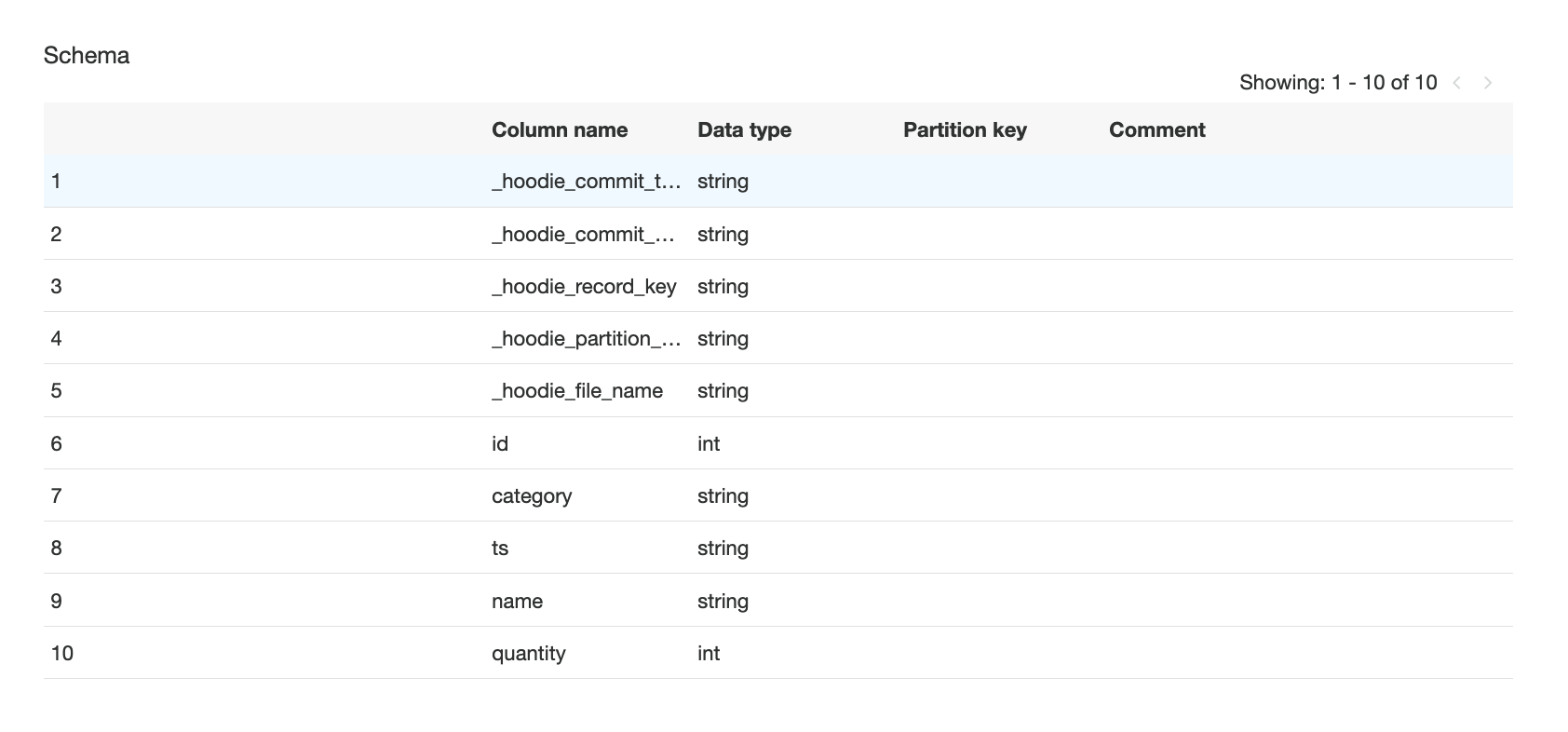
The AWS Glue job creates a Hudi table in the Data Catalog mapped to the Hudi dataset on Amazon S3. Because the hoodie.datasource.hive_sync.table configuration parameter is set to product_table, the table is visible under the default database in the Data Catalog.
The following screenshot shows the Hudi table column names in the Data Catalog.
Query the data using Athena
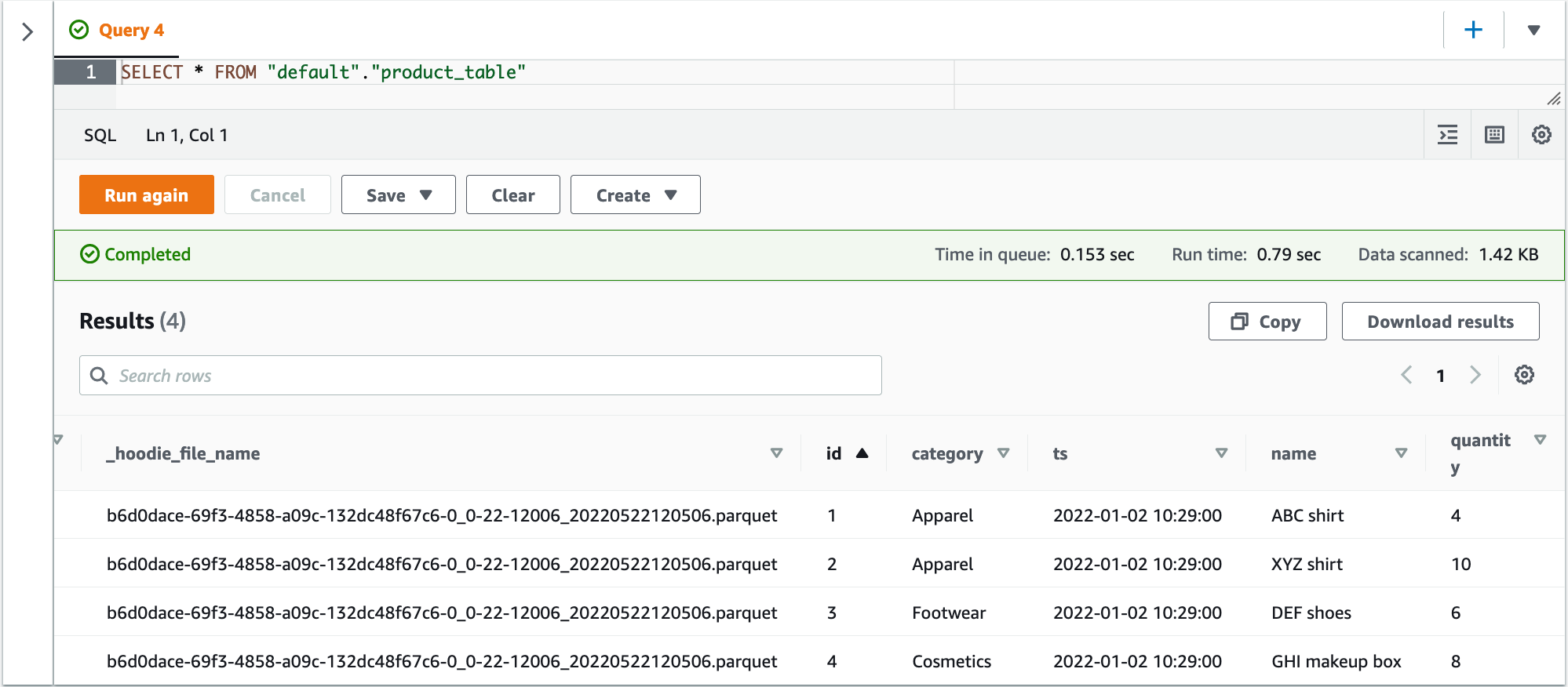
With the Hudi datasets available in Amazon S3, you can query the data using Athena. Let’s use the following query:
The following screenshot shows the query output. The table product_table has four records from the initial ingestion: two records for the category Apparel, one for Cosmetics, and one for Footwear.
Load incremental data into the Kafka topic
Now suppose that the store sold some quantity of apparel and footwear and added a new product to its inventory, as shown in the following code. The store sold two items of product ID 1 (Apparel) and one item of product ID 3 (Footwear). The store also added the Cosmetics category, with product ID 5.
Let’s ingest the incremental data from the deltastreamer_incr_load.json file to the Kafka topic and query the data from Athena:
Within a few seconds, you should see a new Parquet file created in the target S3 bucket under the product_table prefix. The following is the screenshot from Athena after the incremental data ingestion showing the latest updates.

Additional considerations
There are some hard-coded Hudi options in the AWS Glue Streaming job scripts. These options are set for the sample table that we created for this post, so update the options based on your workload.
Clean up
To avoid any incurring future charges, delete the CloudFormation stack, which deletes all the underlying resources created by this post, except for the product_table table created in the default database. Manually delete the product_table table under the default database from the Data Catalog.
Conclusion
In this post, we illustrated how you can add the Apache Hudi Connector for AWS Glue and perform streaming ingestion into an S3 data lake using Apache Hudi DeltaStreamer with AWS Glue. You can use the Apache Hudi Connector for AWS Glue to create a serverless streaming pipeline using AWS Glue streaming jobs with the DeltaStreamer utility to ingest data from Kafka. We demonstrated this by reading the latest updated data using Athena in near-real time.
As always, AWS welcomes feedback. If you have any comments or questions on this post, please share them in the comments.
About the authors
 Vishal Pathak is a Data Lab Solutions Architect at AWS. Vishal works with customers on their use cases, architects solutions to solve their business problems, and helps them build scalable prototypes. Prior to his journey in AWS, Vishal helped customers implement business intelligence, data warehouse, and data lake projects in the US and Australia.
Vishal Pathak is a Data Lab Solutions Architect at AWS. Vishal works with customers on their use cases, architects solutions to solve their business problems, and helps them build scalable prototypes. Prior to his journey in AWS, Vishal helped customers implement business intelligence, data warehouse, and data lake projects in the US and Australia.
 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He enjoys learning different use cases from customers and sharing knowledge about big data technologies with the wider community.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He enjoys learning different use cases from customers and sharing knowledge about big data technologies with the wider community.
 Anand Prakash is a Senior Solutions Architect at AWS Data Lab. Anand focuses on helping customers design and build AI/ML, data analytics, and database solutions to accelerate their path to production.
Anand Prakash is a Senior Solutions Architect at AWS Data Lab. Anand focuses on helping customers design and build AI/ML, data analytics, and database solutions to accelerate their path to production.