AWS Big Data Blog
Integrate Etleap with Amazon Redshift Streaming Ingestion (preview) to make data available in seconds
Amazon Redshift is a fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using SQL and your extract, transform, and load (ETL), business intelligence (BI), and reporting tools. Tens of thousands of customers use Amazon Redshift to process exabytes of data per day and power analytics workloads.
Etleap is an AWS Advanced Technology Partner with the AWS Data & Analytics Competency and Amazon Redshift Service Ready designation. Etleap ETL removes the headaches experienced building data pipelines. A cloud-native platform that seamlessly integrates with AWS infrastructure, Etleap ETL consolidates data without the need for coding. Automated issue detection pinpoints problems so data teams can stay focused on business initiatives, not data pipelines.
In this post, we show how Etleap customers are integrating with the new streaming ingestion feature in Amazon Redshift (currently in limited preview) to load data directly from Amazon Kinesis Data Streams. This reduces load times from minutes to seconds and helps you gain faster data insights.
Amazon Redshift streaming ingestion with Kinesis Data Streams
Traditionally, you had to use Amazon Kinesis Data Firehose to land your stream into Amazon Simple Storage Service (Amazon S3) files and then employ a COPY command to move the data into Amazon Redshift. This method incurs latencies in the order of minutes.
Now, the native streaming ingestion feature in Amazon Redshift lets you ingest data directly from Kinesis Data Streams. The new feature enables you to ingest hundreds of megabytes of data per second and query it at exceptionally low latency—in many cases only 10 seconds after entering the data stream.
Configure Amazon Redshift streaming ingestion with SQL queries
Amazon Redshift streaming ingestion uses SQL to connect with one or more Kinesis data streams simultaneously. In this section, we walk through the steps to configure streaming ingestion.
Create an external schema
We begin by creating an external schema referencing Kinesis using syntax adapted from Redshift’s support for Federated Queries:
This external schema command creates an object inside Amazon Redshift that acts as a proxy to Kinesis Data Streams. Specifically, to the collection of data streams that are accessible via the AWS Identity and Access Management (IAM) role. You can use either the default Amazon Redshift cluster IAM role or a specified IAM role that has been attached to the cluster previously.
Create a materialized view
You can use Amazon Redshift materialized views to materialize a point-in-time view of a Kinesis data stream, as accumulated up to the time it is queried. The following command creates a materialized view over a stream from the previously defined schema:
Note the use of the dot syntax to pick out the particular stream desired. The attributes of the stream include a timestamp field, partition key, sequence number, and a VARBYTE data payload.
Although the previous materialized view definition simply performs a SELECT *, more sophisticated processing is possible, for instance, applying filtering conditions or shredding JSON data into columns. To demonstrate, consider the following Kinesis data stream with JSON payloads:
To demonstrate this, write a materialized view that shreds the JSON into columns, focusing only on the entered shop action:
On the Amazon Redshift leader node, the view definition is parsed and analyzed. On success, it is added to the system catalogs. No further communication with Kinesis Data Streams occurs until the initial refresh.
Refresh the materialized view
The following command pulls data from Kinesis Data Streams into Amazon Redshift:
You can initiate it manually (via the SQL preceding command) or automatically via a scheduled query. In either case, it uses the IAM role associated with the stream. Each refresh is incremental and massively parallel, storing its progress in each Kinesis shard in the system catalogs so as to be ready for the next round of refresh.
With this process, you can now query near-real-time data from your Kinesis data stream through Amazon Redshift.
Use Amazon Redshift streaming ingestion with Etleap
Etleap pulls data from databases, applications, file stores, and event streams, and transforms it before loading it into an AWS data repository. Data ingestion pipelines typically process batches every 5–60 minutes, so when you query your data in Amazon Redshift, it’s at least 5 minutes out of date. For many use cases, such as ad hoc queries and BI reporting, this latency time is acceptable.
But what about when your team demands more up-to-date data? An example is operational dashboards, where you need to track KPIs in near-real time. Amazon Redshift load times are bottlenecked by COPY commands that move data from Amazon S3 into Amazon Redshift, as mentioned earlier.
This is where streaming ingestion comes in: by staging the data in Kinesis Data Streams rather than Amazon S3, Etleap can reduce data latency in Amazon Redshift to less than 10 seconds. To preview this feature, we ingest data from SQL databases such as MySQL and Postgres that support change data capture (CDC). The data flow is shown in the following diagram.
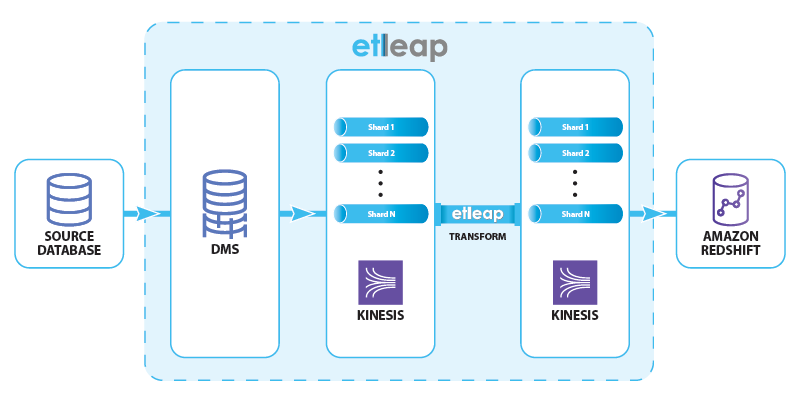
Etleap manages the end-to-end data flow through AWS Database Migration Service (AWS DMS) and Kinesis Data Streams, and creates and schedules Amazon Redshift queries, providing up-to-date data.
AWS DMS consumes the replication logs from the source, and produces insert, update, and delete events. These events are written to a Kinesis data stream that has multiple shards in order to handle the event load. Etleap transforms these events according to user-specified rules, and writes them to another data stream. Finally, a sequence of Amazon Redshift commands load data from the stream into a destination table. This procedure takes less than 10 seconds in real-world scenarios.
Configure Amazon Redshift streaming ingestion with Etleap
Previously, we explored how data in Kinesis Data Streams can be accessed in Amazon Redshift using SQL queries. In this section, we see how Etleap uses the streaming ingestion feature to mirror a table from MySQL into Amazon Redshift, and the end-to-end latency we can achieve.
Etleap customers that are part of the Streaming Ingestion Preview Program can ingest data into Amazon Redshift directly from an Etleap-managed Kinesis data stream. All pipelines from a CDC-enabled source automatically use this feature.

The destination table in Amazon Redshift is Type 1, a mirror of the table in the source database.
For example, say you want to mirror a MySQL table in Amazon Redshift. The table represents the online shopping carts that users have open. In this case, low latency is critical so that the platform marketing strategists can instantly identify abandoned carts and high demand items.
The cart table has the following structure:
Changes from the source table are captured using AWS DMS and then sent to Etleap via a Kinesis data stream. Etleap transforms these records and writes them to another data stream using the following structure:
The structure encodes the row that was modified or inserted, as well as the operation type (represented by the op column), which can have three values: I (insert), U (update) or D (delete).
This information is then materialized in Amazon Redshift from the data stream:
In the materialized view, we expose the following columns:
PartitionKeyrepresents an Etleap sequence number, to ensure that updates are processed in the correct order.- We shred the primary keys of the table (
idin the preceding example) from the payload, using them as a distribution key to improve the update performance. - The
Datacolumn is parsed out into a SUPER type from the JSON object in the stream. This is shredded into the corresponding columns in the cart table when the data is inserted.
With this staging materialized view, Etleap then updates the destination table (cart) that has the following schema:
To update the table, Etleap runs the following queries, selecting only the changed rows from the staging materialized view, and applies them to the cart table:
We run the following sequence of queries:
- Refresh the
cart_stagingmaterialized view to get new records from thecartstream. - Delete all records from the
carttable that were updated or deleted since the last time we ran the update sequence. - Insert all the updated and newly inserted records from the
cart_stagingmaterialized view into thecarttable. - Update the
_etleap_sibookkeeping table with the current position. Etleap uses this table to optimize the query in the staging materialized view.
This update sequence runs continuously to minimize end-to-end latency. To measure performance, we simulated the change stream from a database table that has up to 100,000 inserts, updates, and deletes. We tested target table sizes of up to 1.28 billion rows. Testing was done on a 2-node ra3.xlplus Amazon Redshift cluster and a Kinesis data stream with 32 shards.
The following figure shows how long the update sequence takes on average over 5 runs in different scenarios. Even in the busiest scenario (100,000 changes to a 1.28 billion row table), the sequence takes just over 10 seconds to run. In our experiment, the refresh time was independent of the delta size, and took 3.7 seconds with a standard deviation of 0.4 seconds.
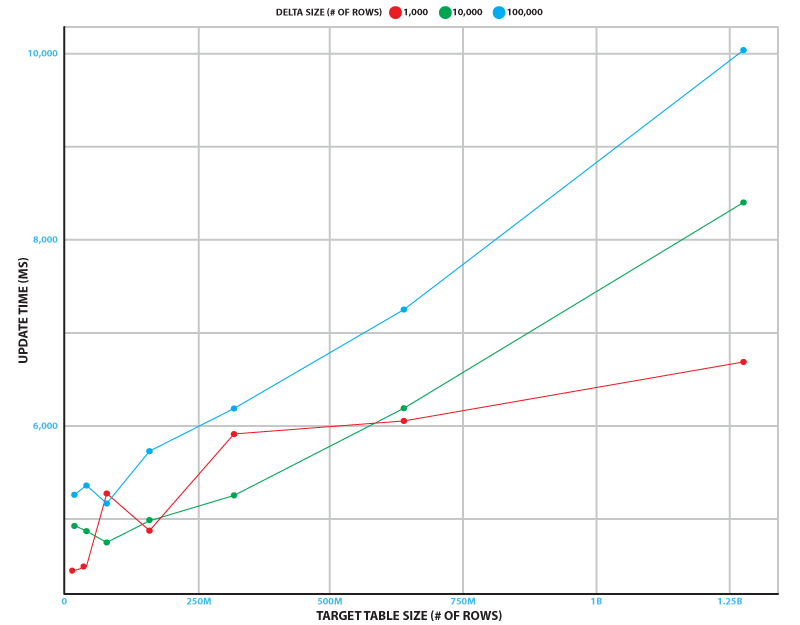
This shows that the update process can keep up with source database tables that have 1 billion rows and 10,000 inserts, updates, and deletes per second.
Summary
In this post, you learned about the native streaming ingestion feature in Amazon Redshift and how it achieves latency in seconds, while ingesting data from Kinesis Data Streams into Amazon Redshift. You also learned about the architecture of Amazon Redshift with the streaming ingestion feature enabled, how to configure it using SQL commands, and use the capability in Etleap.
To learn more about Etleap, take a look at the Etleap ETL on AWS Quick Start, or visit their listing on AWS Marketplace.
About the Authors
 Caius Brindescu is an engineer at Etleap with over 3 years of experience in developing ETL software. In addition to development work, he helps customers make the most out of Etleap and Amazon Redshift. He holds a PhD from Oregon State University and one AWS certification (Big Data – Specialty).
Caius Brindescu is an engineer at Etleap with over 3 years of experience in developing ETL software. In addition to development work, he helps customers make the most out of Etleap and Amazon Redshift. He holds a PhD from Oregon State University and one AWS certification (Big Data – Specialty).
 Todd J. Green is a Principal Engineer with AWS Redshift. Before joining Amazon, TJ worked at innovative database startups including LogicBlox and RelationalAI, and was an Assistant Professor of Computer Science at UC Davis. He received his PhD in Computer Science from UPenn. In his career as a researcher, TJ won a number of awards, including the 2017 ACM PODS Test-of-Time Award.
Todd J. Green is a Principal Engineer with AWS Redshift. Before joining Amazon, TJ worked at innovative database startups including LogicBlox and RelationalAI, and was an Assistant Professor of Computer Science at UC Davis. He received his PhD in Computer Science from UPenn. In his career as a researcher, TJ won a number of awards, including the 2017 ACM PODS Test-of-Time Award.
 Maneesh Sharma is a Senior Database Engineer with Amazon Redshift. He works and collaborates with various Amazon Redshift Partners to drive better integration. In his spare time, he likes running, playing ping pong, and exploring new travel destinations.
Maneesh Sharma is a Senior Database Engineer with Amazon Redshift. He works and collaborates with various Amazon Redshift Partners to drive better integration. In his spare time, he likes running, playing ping pong, and exploring new travel destinations.
 Jobin George is a Big Data Solutions Architect with more than a decade of experience designing and implementing large-scale big data and analytics solutions. He provides technical guidance, design advice, and thought leadership to some of the key AWS customers and big data partners.
Jobin George is a Big Data Solutions Architect with more than a decade of experience designing and implementing large-scale big data and analytics solutions. He provides technical guidance, design advice, and thought leadership to some of the key AWS customers and big data partners.