AWS Big Data Blog
Introducing Amazon S3 shuffle in AWS Glue
Nov 2022: Newer version of the product is now available to be used for this post.
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning (ML), and application development. In AWS Glue, you can use Apache Spark, which is an open-source, distributed processing system for your data integration tasks and big data workloads. Apache Spark utilizes in-memory caching and optimized query execution for fast analytic queries against your datasets, which are split into multiple partitions so that you can execute different transformations in parallel.
Shuffling is an important step in a Spark job whenever data is rearranged between partitions. The groupByKey(), reduceByKey(), join(), and distinct() are some examples of wide transformations that can cause a shuffle. During a shuffle, data is written to disk and transferred across the network. As a result, the shuffle operation is often constrained by the available local disk capacity, or data skew, which can cause straggling executors. Spark often throws a No space left on device or MetadataFetchFailedException error when there is not enough disk space left on the executor and there is no recovery.
This post introduces a new Spark shuffle manager available in AWS Glue that disaggregates Spark compute and shuffle storage by utilizing Amazon Simple Storage Service (Amazon S3) to store Spark shuffle and spill files. Using Amazon S3 for Spark shuffle storage lets you run data-intensive workloads much more reliably.
Understanding the shuffle operation in AWS Glue
Spark creates physical plans for running your workflow, called Directed Acyclic Graphs (DAGs). The DAG represents a series of transformations on your dataset, each resulting in a new immutable RDD. All of the transformations in Spark are lazy, in that they are not computed until an action is called to generate results. There are two types of transformations:
- Narrow transformation – Such as
map,filter,union, andmapPartition, where each input partition contributes to only one output partition. - Wide transformation – Such as
join,groupBykey,reduceByKey, andrepartition, where each input partition contributes to many output partitions.
In Spark, a shuffle occurs whenever data is rearranged between partitions. This is required because the wide transformation needs information from other partitions in order to complete its processing. Spark gathers the required data from each partition and combines it into a new partition. During a shuffle phase, all Spark map tasks write shuffle data to a local disk that is then transferred across the network and fetched by Spark reduce tasks. With AWS Glue, workers write shuffle data on local disk volumes attached to the AWS Glue workers.
In addition to shuffle writes, Spark uses local disk to spill data from memory that exceeds the heap space defined by the spark.memory.fraction configuration parameter. Shuffle spill (memory) is the size of the de-serialized form of the data in the memory at the time when the worker spills it. Whereas shuffle spill (disk) is the size of the serialized form of the data on disk after the worker has spilled.

Challenges
Spark uses local disk for storing intermediate shuffle and shuffle spills. This introduces the following key challenges:
- Hitting local storage limits – If you have a Spark job that computes transformations over a large amount of data, and results in either too much spill or shuffle or both, then you might get a failed job with
java.io.IOException: No space left on deviceexception if the underlying storage has filled up. - Co-location of storage with executors – If an executor is lost, then shuffle files are lost as well. This leads to several task and stage retries, as Spark tries to recompute stages in order to recover lost shuffle data. Spark natively provides an external shuffle service that lets it store shuffle data independent to the life of executors. But the shuffle service itself becomes a point of failure and must always be up in order to serve shuffle data. Additionally, shuffles are still stored on local disk, which might run out of space for a large job.
To illustrate one of the preceding scenarios, let’s use the query q80.sql from the standard TPC-DS 3 TB dataset as an example. This query attempts to calculate the total sales, returns, and eventual profit realized during a specific time frame. It involves multiple wide transformations (shuffles) caused by left outer join, group by, and union all. Let’s run the following query with 10 G1.x AWS Glue DPU (data processing unit). For the G.1X worker type, each worker maps to 1 DPU and 1 executor. 10 G1.x workers account for a total of 640GB of disk space. See the following sql query:
The following screenshot shows the AWS Glue job run details from the Apache Spark web UI:
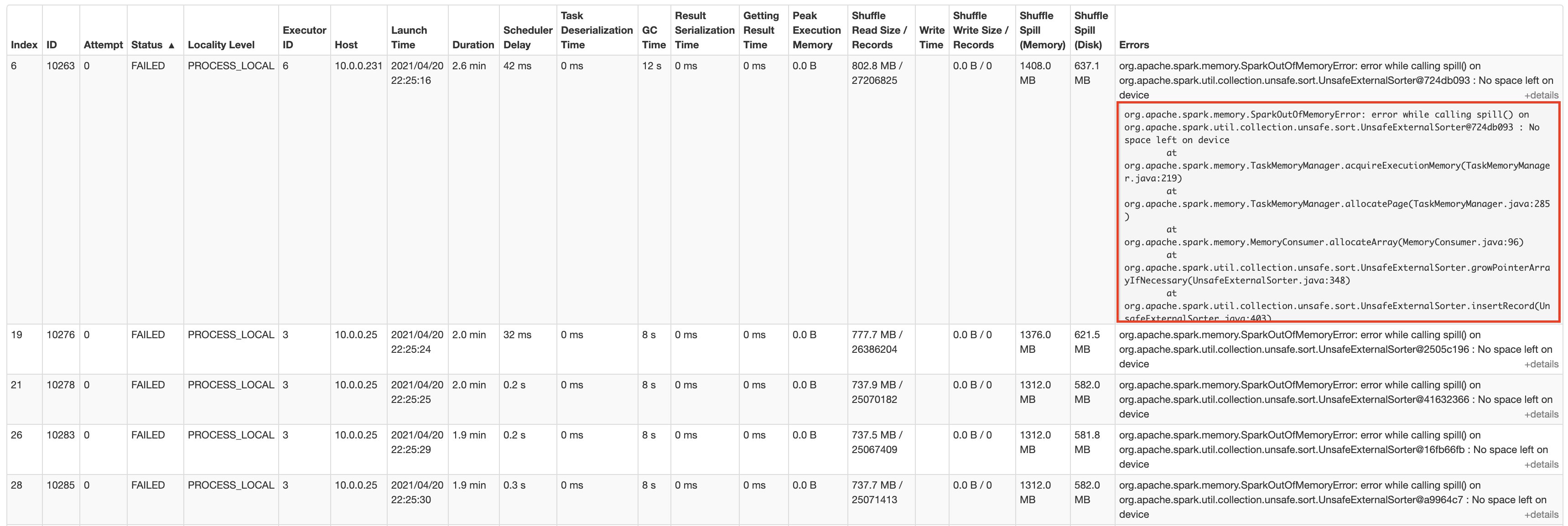
The job runs for about 1 hour and 25 minutes, then we start observing task failures. Spark ends up stopping the stage and canceling the job when the task retries also fail.
The following screenshots show the aggregated metrics for the failed stage, as well as how much data is spilled to disk by individual executors:
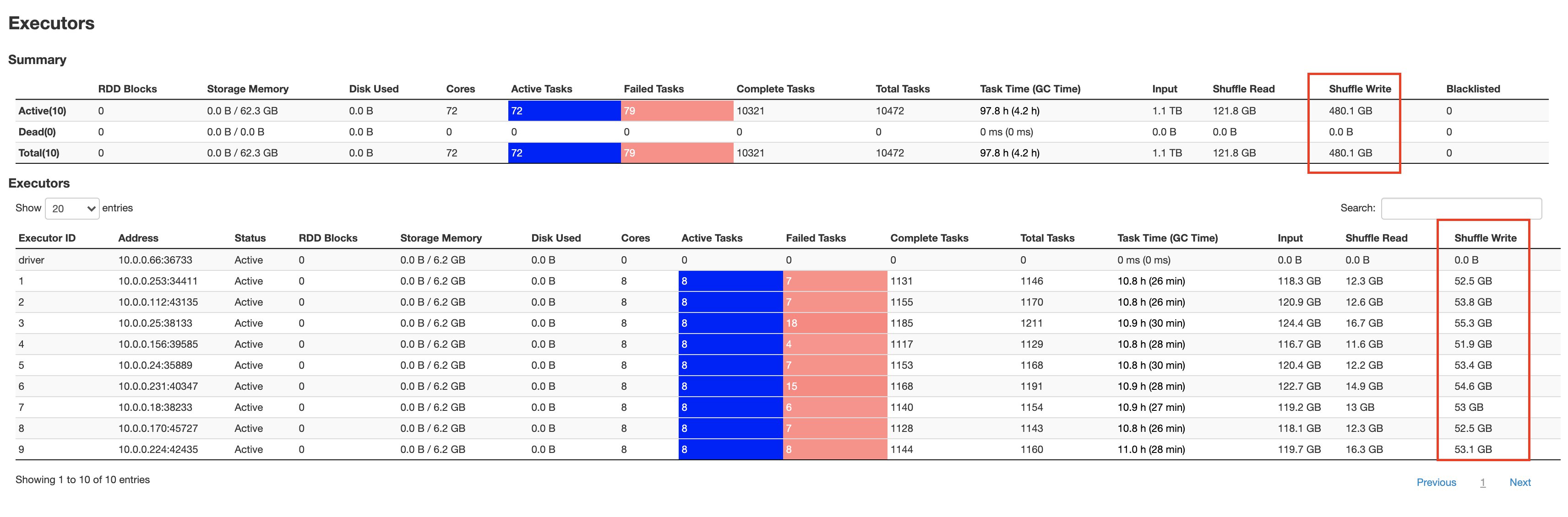
As seen in the Shuffle Write metric from the above Spark UI screenshot, all 10 workers shuffle over 50 GB of data. Further writes aren’t allowed, and tasks start failing with a “No space left on device” error.

The remaining storage is occupied by data that is spilled to disk, as seen in the Shuffle Spill (Disk) metric from the above Spark UI screenshot. This failed job is a classic example of a data-intensive transformation where Spark is both shuffling and spilling to disk when executor memory is filled.
Solution overview
We have various methods for overcoming the disk space error:
- Scale out – Increase the number of workers. This incurs an increase in cost. However, scaling out might not always work, especially if your data is heavily skewed on a few keys. Fixing skewness will require considerable modifications to your Spark application logic.
- Increase shuffle partitions – Increasing the shuffle partitions can sometimes help overcome space errors. However, this might not always work, and therefore is unreliable.
- Disaggregate compute and storage – This approach presents several of the advantages of not only scaling storage for large shuffles, but also adding reliability in the event of node failures because shuffle data is independently stored. Following are few implementations of this disaggregated approach:
- Dedicated intermediate storage cluster – In this approach, you use an additional fleet of shuffle services to serve intermediate shuffle. It has several advantages, such as merging shuffle files and sequential I/O, but it introduces an overhead of fleet maintenance from both operations, as well as a cost standpoint. For examples of this approach, see Cosco: An Efficient Facebook-Scale Shuffle Service and Zeus: Uber’s Highly Scalable and Distributed Shuffle as a Service.
- Serverless storage – AWS Glue implements a different approach in which you utilize Amazon S3, a cost-effective managed and serverless storage, to store intermediate shuffle data. This design does not depend upon a dedicated daemon, such as shuffle service, to preserve shuffle files. This lets you elastically scale your Spark job without the overhead of running, operating, and maintaining additional storage or compute nodes.
With AWS Glue 2.0, you can now use Amazon S3 to store Spark shuffle and spill data. Amazon S3 is an object storage service that offers industry-leading scalability, data availability, security, and performance. This gives complete elasticity to Spark jobs, thereby allowing you to run your most data intensive workloads reliably.
The following diagram illustrates how Spark map tasks write the shuffle and spill files to the given Amazon S3 shuffle bucket. Reducer tasks consider the shuffle blocks as remote blocks and read them from the same shuffle bucket.
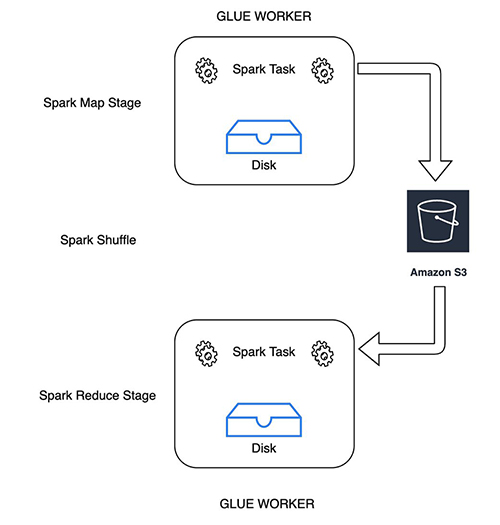
Use Amazon S3 to store shuffle and spill data
The following job parameters enable and tune Spark to use S3 buckets for storing shuffle and spill data. You can also enable at-rest encryption when writing shuffle data to Amazon S3 by using security configuration settings.
| Key | Value | Explanation |
| TRUE | This is the main flag, which tells Spark to use S3 buckets for writing and reading shuffle data. | |
| TRUE | This is an optional flag that lets you offload spill files to S3 buckets, which provides additional resiliency to your Spark job. This is only required for large workloads that spill a lot of data to disk. This flag is disabled by default. | |
This is also optional, and it specifies the S3 bucket where we write the shuffle files. By default, we use TempDir/shuffle-data |
You can also use the AWS Glue Studio console to enable Amazon S3 based shuffle or spill. You can choose the preceding properties from pre-populated options in the Job parameters section.

Results
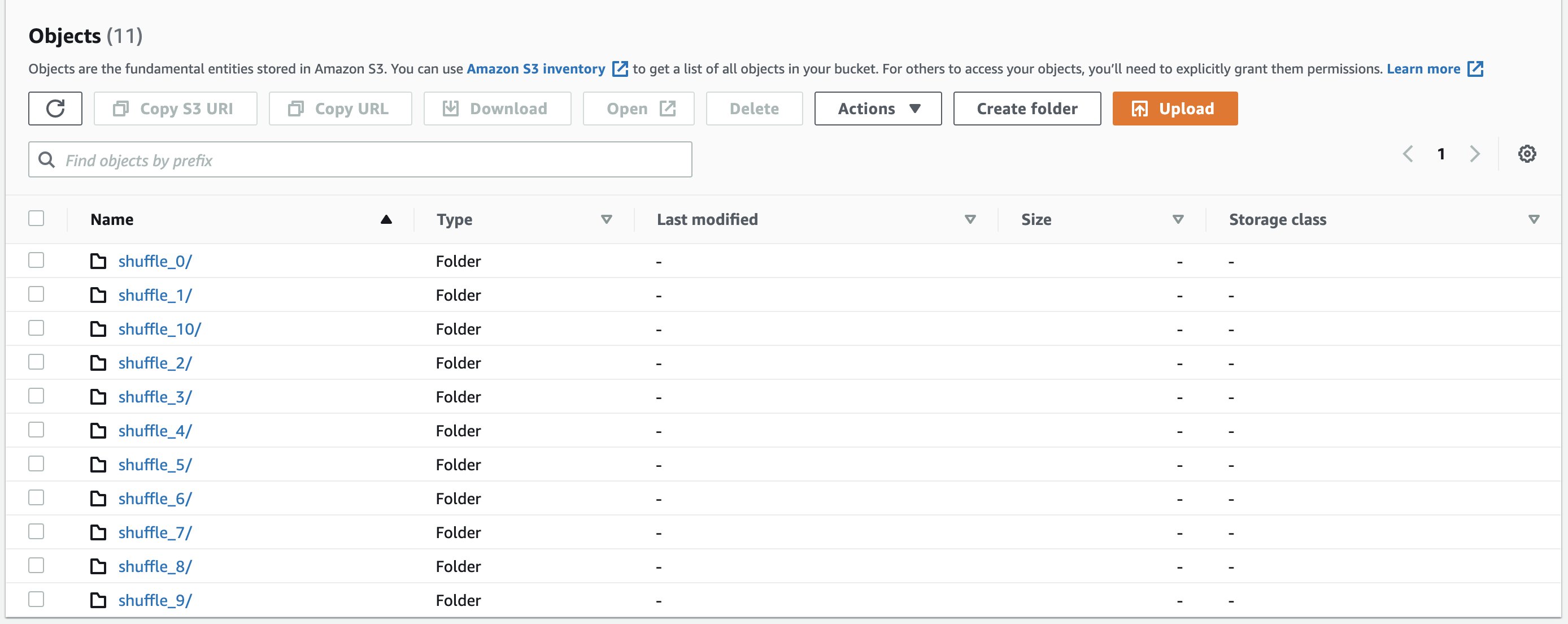
Let’s run the same q80.sql query with Amazon S3 shuffle enabled. We can view the shuffle files stored in the S3 bucket in the following format:
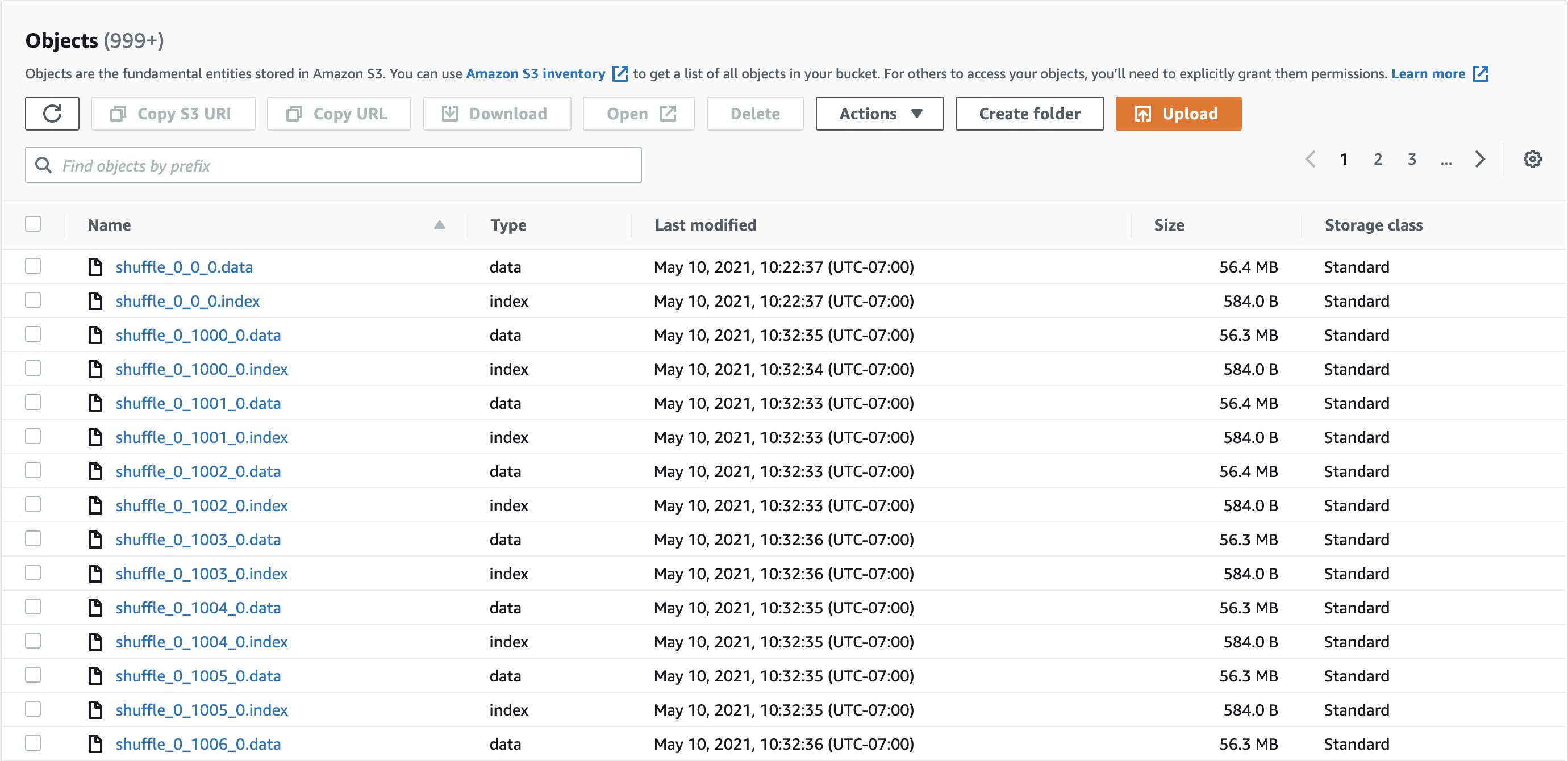
Two kinds of files are created:
- Data – Stores the shuffle output of the current task
- Index – Stores the classification information of the data in the data file by storing partition offsets
The following screenshots shows example shuffle directories and shuffle files:
The following screenshot shows the aggregated metrics from the Spark UI:
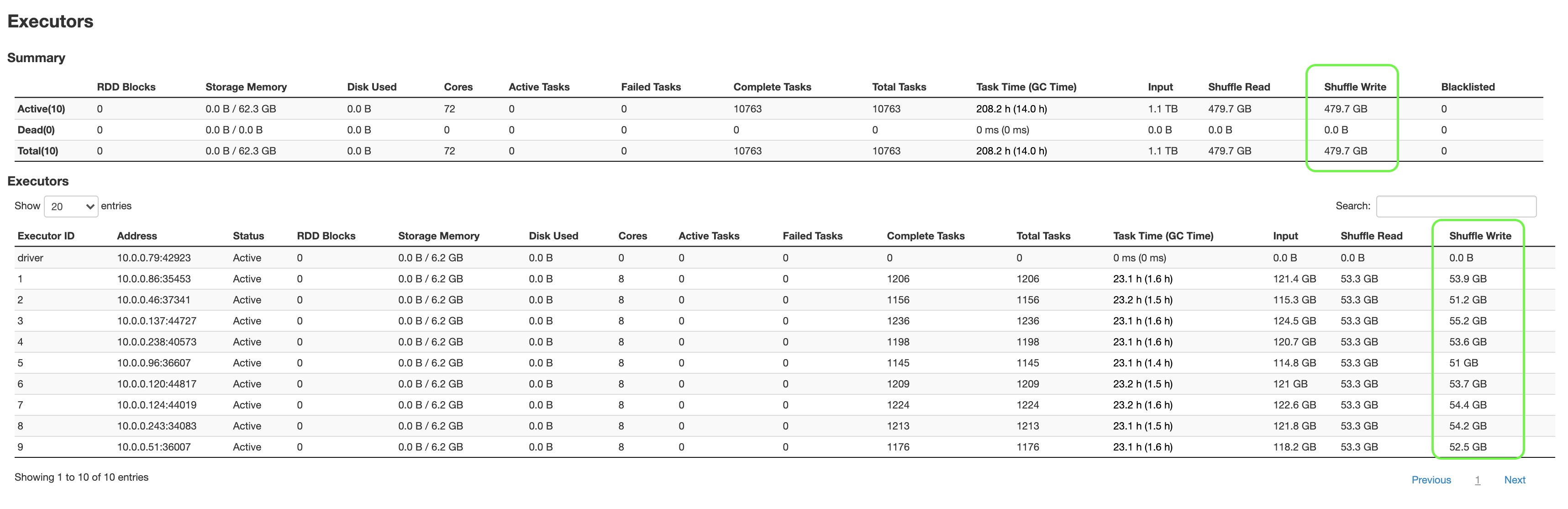
The following are a few key highlights:
q80.sql, which had failed earlier after 1 hour and 25 minutes, and was able to complete only 13 out of 18 stages, finished successfully in about 2 hours and 53 minutes, completing all 18 stages.- We were able to shuffle 479.7 GB of data without worrying about storage limits.
- Additional workers aren’t required to scale storage, which provides substantial cost savings.
Considerations and best practices
Keep in mind the following best practices when considering this solution:
- This feature is recommended when you want to ensure the reliable execution of your data intensive workloads that create a large amount of shuffle or spill data. Writing and reading shuffle files from Amazon S3 is marginally slower when compared to local disk for our experiments with TPC-DS queries. S3 shuffle performance would be impacted by the number and size of shuffle files. For example, S3 could be slower for reads as compared to local storage if you have a large number of small shuffle files or partitions in your Spark application.
- You can use this feature if your job frequently suffers from
No space left on deviceissues. - You can use this feature if your job frequently suffers fetch failure issues (
org.apache.spark.shuffle.MetadataFetchFailedException). - You can use this feature if your data is skewed.
- We recommend setting the S3 bucket lifecycle policies on the shuffle bucket (spark.shuffle.glue.s3ShuffleBucket) in order to clean up old shuffle data.
- At the time of writing this blog, this feature is currently available on AWS Glue 2.0 and Spark 2.4.3.
Conclusion
This post discussed how we can independently scale storage in AWS Glue without adding additional workers. With this feature, you can expect jobs that are processing terabytes of data to run much more reliably. Happy shuffling!
About the Authors
 Anubhav Awasthi is a Big Data Specialist Solutions Architect at AWS. He works with customers to provide architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation.
Anubhav Awasthi is a Big Data Specialist Solutions Architect at AWS. He works with customers to provide architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation.
 Rajendra Gujja is a Software Development Engineer on the AWS Glue team. He is passionate about distributed computing and everything and anything to do with the data.
Rajendra Gujja is a Software Development Engineer on the AWS Glue team. He is passionate about distributed computing and everything and anything to do with the data.
 Mohit Saxena is a Software Engineering Manager on the AWS Glue team. His team works on distributed systems for efficiently managing data lakes on AWS and optimizes Apache Spark for performance and reliability.
Mohit Saxena is a Software Engineering Manager on the AWS Glue team. His team works on distributed systems for efficiently managing data lakes on AWS and optimizes Apache Spark for performance and reliability.