AWS Big Data Blog
Amazon EMR Migration Guide
Businesses worldwide are discovering the power of new big data processing and analytics frameworks like Apache Hadoop and Apache Spark, but they are also discovering some of the challenges of operating these technologies in on-premises data lake environments. They may also have concerns about the future of their current distribution vendor.
To address this, we’ve introduced the Amazon EMR Migration Guide (first published June 2019.) This paper is a comprehensive guide to offer sound technical advice to help customers in planning how to move from on-premises big data deployments to EMR.
Common problems of on-premises big data environments include a lack of agility, excessive costs, and administrative headaches, as IT organizations wrestle with the effort of provisioning resources, handling uneven workloads at large scale, and keeping up with the pace of rapidly changing, community-driven, open-source software innovation. Many big data initiatives suffer from the delay and burden of evaluating, selecting, purchasing, receiving, deploying, integrating, provisioning, patching, maintaining, upgrading, and supporting the underlying hardware and software infrastructure.
A subtler, if equally critical, problem is the way companies’ data center deployments of Apache Hadoop and Apache Spark directly tie together the compute and storage resources in the same servers, creating an inflexible model where they must scale in lock step. This means that almost any on-premises environment pays for high amounts of under-used disk capacity, processing power, or system memory, as each workload has different requirements for these components. Typical workloads run on different types of clusters, at differing frequencies and times of day. These big data workloads should be freed to run whenever and however is most efficient, while still accessing the same shared underlying storage or data lake. See Figure 1. below for an illustration.
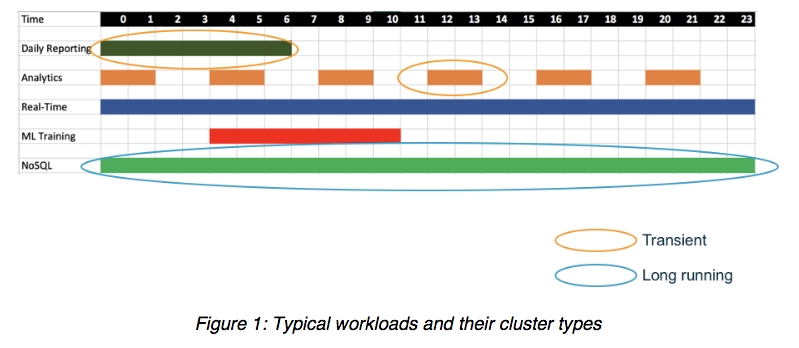
How can smart businesses find success with their big data initiatives? Migrating big data (and machine learning) to the cloud offers many advantages. Cloud infrastructure service providers, such as AWS offer a broad choice of on-demand and elastic compute resources, resilient and inexpensive persistent storage, and managed services that provide up-to-date, familiar environments to develop and operate big data applications. Data engineers, developers, data scientists, and IT personnel can focus their efforts on preparing data and extracting valuable insights.
Services like Amazon EMR, AWS Glue, and Amazon S3 enable you to decouple and scale your compute and storage independently, while providing an integrated, well-managed, highly resilient environment, immediately reducing so many of the problems of on-premises approaches. This approach leads to faster, more agile, easier to use, and more cost-efficient big data and data lake initiatives.
However, the conventional wisdom of traditional on-premises Apache Hadoop and Apache Spark isn’t always the best strategy in cloud-based deployments. A simple lift and shift approach to running cluster nodes in the cloud is conceptually easy but suboptimal in practice. Different design decisions go a long way towards maximizing your gains as you migrate big data to a cloud architecture.
This guide provides the best practices for:
- Migrating data, applications, and catalogs
- Using persistent and transient resources
- Configuring security policies, access controls, and audit logs
- Estimating and minimizing costs, while maximizing value
- Leveraging the AWS Cloud for high availability (HA) and disaster recovery (DR)
- Automating common administrative tasks
Although not intended as a replacement for professional services, this guide covers a wide range of common questions, and scenarios as you migrate your big data and data lake initiatives to the cloud.
When starting your journey for migrating your big data platform to the cloud, you must first decide how to approach migration. One approach is to re-architect your platform to maximize the benefits of the cloud. The other approach is known as lift and shift, is to take your existing architecture and complete a straight migration to the cloud. A final option is a hybrid approach, where you blend a lift and shift with re-architecture. This decision is not straightforward as there are advantages and disadvantages of both approaches.
A lift and shift approach is usually simpler with less ambiguity and risk. Additionally, this approach is better when you are working against tight deadlines, such as when your lease is expiring for a data center. However, the disadvantage to a lift and shift is that it is not always the most cost effective, and the existing architecture may not readily map to a solution in the cloud.
A re-architecture unlocks many advantages, including optimization of costs and efficiencies. With re-architecture, you move to the latest and greatest software, have better integration with native cloud tools, and lower operational burden by leveraging native cloud products and services.
This paper provides advantages and disadvantages of each migration approach from the perspective of the Apache Spark and Hadoop ecosystems. To read the paper, download the Amazon EMR Migration Guide now.
For a more general resource on deciding which approach is ideal for your workflow, see An E-Book of Cloud Best Practices for Your Enterprise, which outlines the best practices for performing migrations to the cloud at a higher level.
About the Author
 Nikki Rouda is the principal product marketing manager for data lakes and big data at AWS. Nikki has spent 20+ years helping enterprises in 40+ countries develop and implement solutions to their analytics and IT infrastructure challenges. Nikki holds an MBA from the University of Cambridge and an ScB in geophysics and math from Brown University.
Nikki Rouda is the principal product marketing manager for data lakes and big data at AWS. Nikki has spent 20+ years helping enterprises in 40+ countries develop and implement solutions to their analytics and IT infrastructure challenges. Nikki holds an MBA from the University of Cambridge and an ScB in geophysics and math from Brown University.