AWS Big Data Blog
Build and optimize a real-time stream processing pipeline with Amazon Kinesis Data Analytics for Apache Flink, Part 1
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more.
In real-time stream processing, it becomes critical to collect, process, and analyze high-velocity real-time data to provide timely insights and react quickly to new information. Streaming data velocity could be unpredictable, and volume could spike based on user demand at a given time of day. Real-time analysis needs to handle the data spike, because any delay in processing streaming data can cause a significant impact on the desired outcome. The value of insights and actions reduces over time, whereas real-time analysis can substantially improve the effectiveness of the analytics application.
A widespread use case is fleet management for vehicles, especially in the autonomous car industry. It’s essential to collect, process, and analyze high-velocity traffic data and react in real time to control and reroute traffic. Real-time stream processing is crucial in many other use cases, such as manufacturing production lines, robotics automation, analyzing high-volume web and application logs, website clickstreams or database event streams, aggregating social media feeds, and tracking financial transactions.
Amazon Kinesis Data Analytics reduces the complexity of building, managing, and integrating Apache Flink applications with other AWS services. Kinesis Data Analytics takes care of everything required to run streaming applications continuously and scales automatically to match your incoming data volume and throughput in a serverless manner.
In this post, you learn the required concepts to implement robust, scalable, and flexible real-time streaming extract, transform, and load (ETL) pipelines with Apache Flink and Kinesis Data Analytics. We demonstrate how to calibrate the Kinesis streaming analytics pipeline to achieve higher performance efficiency and better cost optimization with the right amount of Kinesis Processing Units (KPUs). Estimating the optimal number of KPUs to handle your streaming workload depends on several factors, including the type of stream processing involved. For instance, if you’re performing CPU-intensive statistical calculations, your application might need more CPU or memory. On the other hand, if your application is simply enriching records via external API calls as they flow through, you might be I/O bound. In Part 1 of this series, you learn various parameters such as Parallelism and ParallelismPerKPU for KPU calibration. In Part 2, you learn about applying auto scaling to add the right amount of KPUs based streaming data spike.
For this post, we analyze the telemetry data of a taxi fleet in New York City in real time to optimize fleet operation using Amazon Kinesis Data Analytics for Apache Flink. Kinesis Data Analytics helps process and analyze the data in real time to identify areas currently requesting a high number of taxi rides. The derived insights are visualized on a dashboard for operational teams to inspect.
Architecture
As shown in the following architecture diagram, every taxi in the fleet is capturing information about completed trips. The tracked information includes the pickup and drop-off locations, number of passengers, and generated revenue. This information is ingested into Amazon Kinesis Data Streams as a simple JSON blob. The application reads the timestamp attribute of the stored events and replays them as if they occurred in real time. From there, the data is processed and analyzed by a Flink application, which is deployed to Kinesis Data Analytics for Apache Flink.
The application identifies areas that are currently requesting a high number of taxi rides. The derived insights are finally persisted into Amazon Elasticsearch Service, where they can be accessed and visualized using Kibana.

In this post, you build a fully managed infrastructure that can analyze the data in near-real time—within seconds—while being scalable and highly available. The architecture uses Kinesis Data Streams as a streaming store, Kinesis Data Analytics to run an Apache Flink application in a fully managed environment, and Amazon Elasticsearch Service (Amazon ES) and Kibana for visualization.
Additionally, we discuss basic Apache Flink concepts and common patterns for streaming analytics. We also cover how Kinesis Data Analytics for Apache Flink is different from a self-managed environment and how to effectively operate and monitor streaming architectures. You also calibrate KPUs in Kinesis Data Analytics to improve performance efficiency and cost optimization.
Deploy the real-time streaming and analysis workload
To replicate the real-life scenario, you connect to a preconfigured Amazon Elastic Compute Cloud (Amazon EC2) instance running Linux over SSH. Then you use a Java application to replay a historic set of taxi trips made in NYC stored in objects in Amazon Simple Storage Service (Amazon S3) into the data stream. The Java application is compiled and loaded onto the EC2 instance.
This section uses an AWS CloudFormation template to build a producer client program that sends NYC taxi trip data to our Kinesis data stream. The template creates the following resources:
- An S3 bucket to house the data resources.
- A new Kinesis data stream that we use to stream a dataset of NYC taxi trips.
- Amazon ElasticSearch cluster with Kibana integration for displaying dashboard information.
- A build pipeline and AWS CodeBuild project along with sources for a Flink Kinesis connector application.
- An EC2 instance for running a Flink application to replay data onto the data stream. An Elastic IP is provisioned for the EC2 instance to allow SSH access.
- A Java application hosted on the EC2 instance, which loads data from the EC2 instance.
- A Kinesis data analytics application to continuously monitor and analyze data from the connected data stream and run the Apache Flink 1.11 application.
- The necessary AWS Identity and Access Management (IAM) service roles, security groups, and policies to run and communicate between the resources you create.
- An Amazon CloudWatch alarm when the application falls behind based on the
millisBehindLatestmetric.
To provision these resources, complete the following steps:
- Choose Launch Stack (right click) and open a new tab to run the CloudFormation template. Make sure to choose us-east-1 ( N. Virginia) region.
- Choose Next.

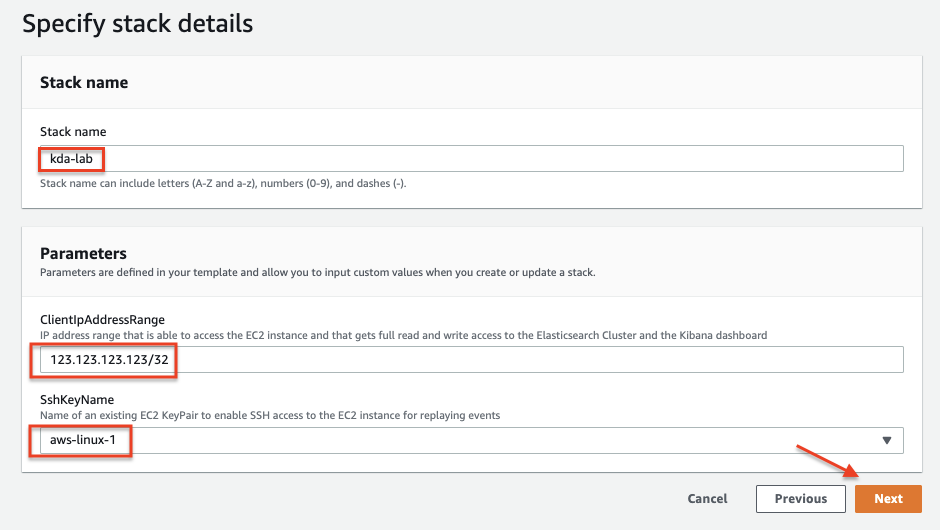
- For Stack name, enter a name.
- For ClientipAddressRange, enter the IP address from which the Kibana dashboard is accessed.
Use https://checkup.amazon.com to find IP and add /32 at the end.
- For SshKeyName¸ enter the SSH key name for the Linux-based EC2 instance you created.
- Choose Next.
- Select I acknowledge that AWS CloudFormation might create IAM resources with custom names and I acknowledge that AWS CloudFormation might require the following capability: CAPABILITY_AUTO_EXPAND.
- Choose Create stack.
- Wait until the CloudFormation template has been successfully created.

Connect to the new EC2 instance and run the producer client program
In this section, we connect to our new EC2 instance and run the producer client program.
- On the AWS CloudFormation console, choose the parent in which the stack was deployed.
- In the Outputs section, locate the AWS Systems Manager Session Manager URL for
KinesisReplayInstance. - Choose the Session Manager URL to connect to the EC2 instance.

- After the connection has been established, start ingesting events into the Kinesis data stream by running the JAR file that was downloaded to the EC2 instance.
The command with pre-populated parameters is available in the Outputs section of the CloudFormation template for ProducerCommand.

You have now successfully created the basic infrastructure and are ingesting data into the data stream.
- On the Kinesis Data Streams console, go to your data stream.
- On the Monitoring tab, locate the Incoming Data – Sum
You may need to wait 2–3 minutes and use the refresh button for the monitoring charts to see the metrics.

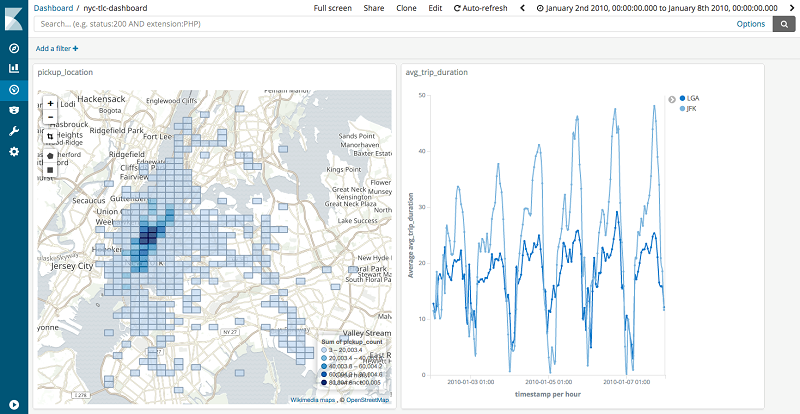
Visualize the data
To visualize the data, navigate to the Kibana dashboard. The dashboard URL is in the Outputs section of the CloudFormation stack for KibanaDashboard. You can inspect the preloaded dashboard or even create your visualizations. If no data shows up, choose the clock icon and change the timeframe to January 2010 – December 2011.
AWS CloudFormation automatically grants access to the IP address provided during stack creation. However, if you encounter access issues in the Kibana dashboard, modify your Amazon ES domain’s access policy and change your local IP address on the Amazon ES console.
To change your IP address, find and choose the Amazon ES domain that you provisioned. On the Actions menu, choose Modify access policy.
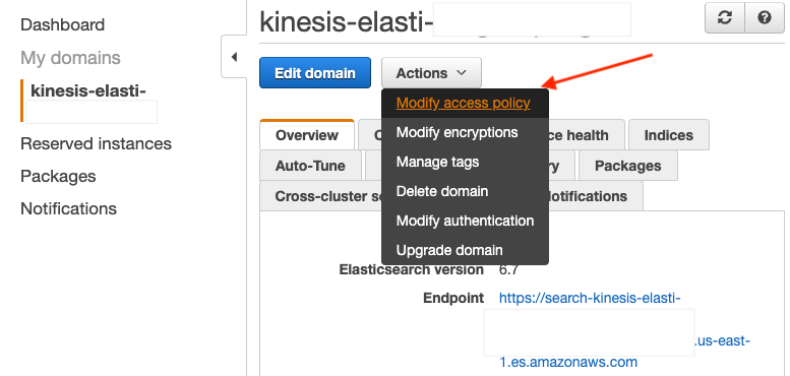
Replace the IP address (for example, 123.123.123.123) with your local IP. If you don’t know your local IP, use http://checkip.amazonaws.com.

Scale the Kinesis data stream to adapt to a spiky data stream
Now that the Kinesis Data Analytics for Apache Flink application is running and sending results to Amazon ES, we can look at operational aspects, such as monitoring and scaling. When you closely inspect the output of the producer application, you can observe that it’s experiencing write provisioned throughput that has exceeded exceptions and it can’t send data fast enough. If the resources of the Apache Flink application aren’t adapted accordingly, particularly for a spiky data stream, the application may fall substantially behind. It may then generate results that are no longer relevant because they’re already too old when the overloaded application can eventually produce them.
The Kinesis data stream was deliberately under-provisioned so that the Kinesis Replay Java application is completely saturating the data stream. When you closely inspect the output of the Java application, you can notice that the replay lag is continuously increasing. This means that the producer can’t ingest events as quickly as required according to the specified speedup parameter.
In this section, we scale the Kinesis data stream to accommodate the throughput generated by the Java application ingesting events into the data stream. We then observe how the Kinesis Data Analytics for Apache Flink application automatically scales to adapt to the increased throughput.
- On the Kinesis Data Streams console, navigate to the stream you created.
- In the Shards section, choose Edit.
- Double the throughput of the Kinesis stream by changing the number of open shards to 16.
- Choose Save changes to confirm the changes.

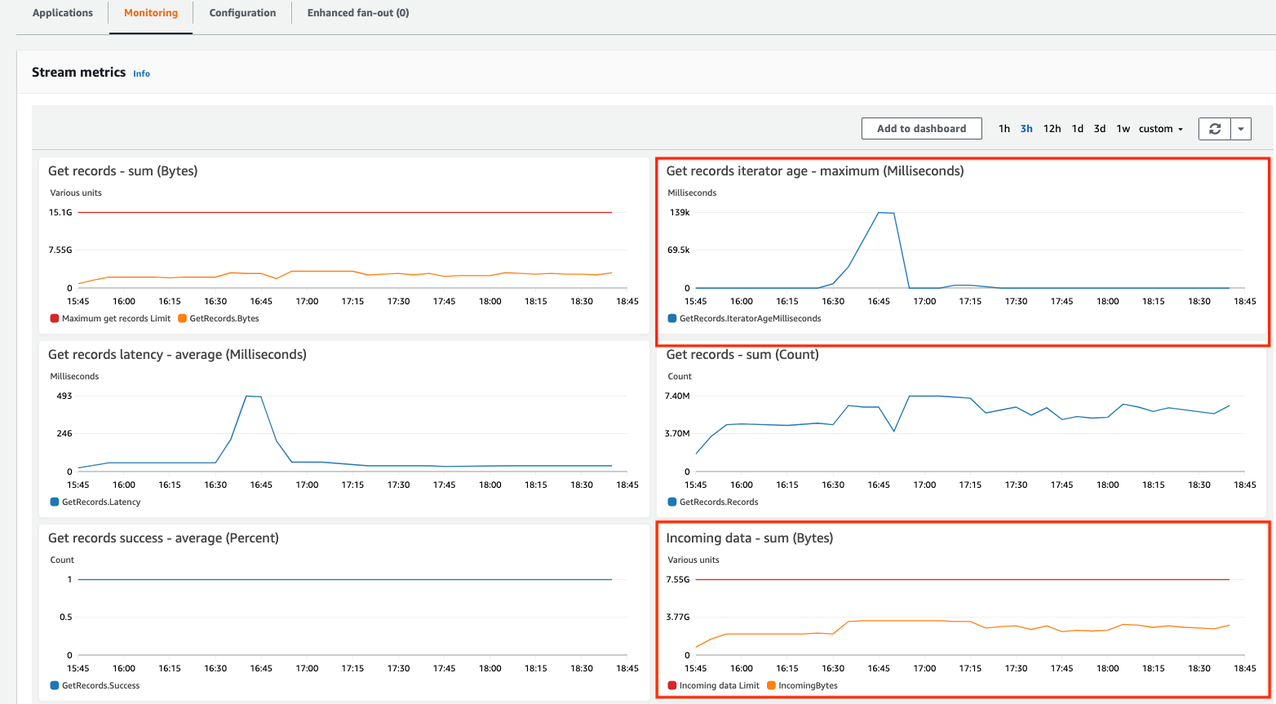
- While the service doubles the number of shards and therefore the throughput of the stream, examine the metrics of the data stream on the Monitoring
After few minutes, you should notice the effect of the scaling operation as the throughput of the stream substantially increases.
While we have scaled Kinesis Data Steams manually, Kinesis Scaling Utility is designed to give you the ability to auto-scale Amazon Kinesis Streams in the same way that you scale EC2 Auto Scaling groups – up or down by a count or as a percentage of the total fleet. You can simply scale to an exact number of Shards. In Part 2, you will learn more about auto-scaling Kinesis Data Streams based on incoming data stream.
Calibrate KPUs
Currently, Kinesis Data Analytics scales your application solely based on the underlying CPU usage. However, because not all applications are CPU bound, depending on your needs, you may want to use a different mechanism for sizing your application. In this section, we demonstrate how you can use the millisBehindLatest metric (available when consuming data from a Kinesis data stream) to responsively size your Kinesis data analytics application.
Kinesis Data Analytics provisions capacity in the form of Amazon Kinesis Processing Units (KPUs). One KPU provides you with 1 vCPU and 4 GB memory. The default limit for KPUs for your application is 32. You can also request an increase to this limit in AWS Service Limits.
We recommend that you test your application with production loads to get an accurate estimate of the number of KPUs required for your application. KPUs usage can vary considerably based on your data volume and velocity, code complexity, integrations, and more. This is especially true when using the Apache Flink runtime in Kinesis Data Analytics.
You can configure the parallel run of tasks and allocate resources for Kinesis Data Analytics for Apache Flink to implement scaling. We use the following properties:
- Parallelism – Use this property to set the default Apache Flink application parallelism. All operators, sources, and sinks run with this parallelism unless overridden in the application code. The default is 1, and the default maximum is 256.
- ParallelismPerKPU – Use this property to set the number of parallel tasks that can be scheduled per the of your application. The default is 1, and the maximum is 8. For applications that have blocking operations (for example, I/O), a higher value of
ParallelismPerKPUleads to full utilization of KPU resources.
Kinesis Data Analytics calculates the KPUs needed to run your application as Parallelism/ParallelismPerKPU.
The following example request for the CreateApplication action sets parallelism when you create an application.
For more examples and instructions for using request blocks with API actions, see Kinesis Data Analytics API Example Code.
The following example request for the UpdateApplication action sets parallelism for an existing application:
Scale the Kinesis Data Analytics for Apache Flink application
Because you increased the throughput of the Kinesis data stream by doubling the number of shards, more events are sent into the stream. However, as a direct result, more events need to be processed. Now the Kinesis data analytics application becomes overloaded and can no longer keep up with the increased number of incoming events. You can observe this through the millisBehindLatest metric, which is published to CloudWatch.
Kinesis Data Analytics natively supports auto scaling. After few minutes, you can see the effect of the auto scaling activities in the metrics. The millisBehindLatest metric starts to decrease until it reaches zero when the processing has caught up with the tip of the Kinesis data stream.
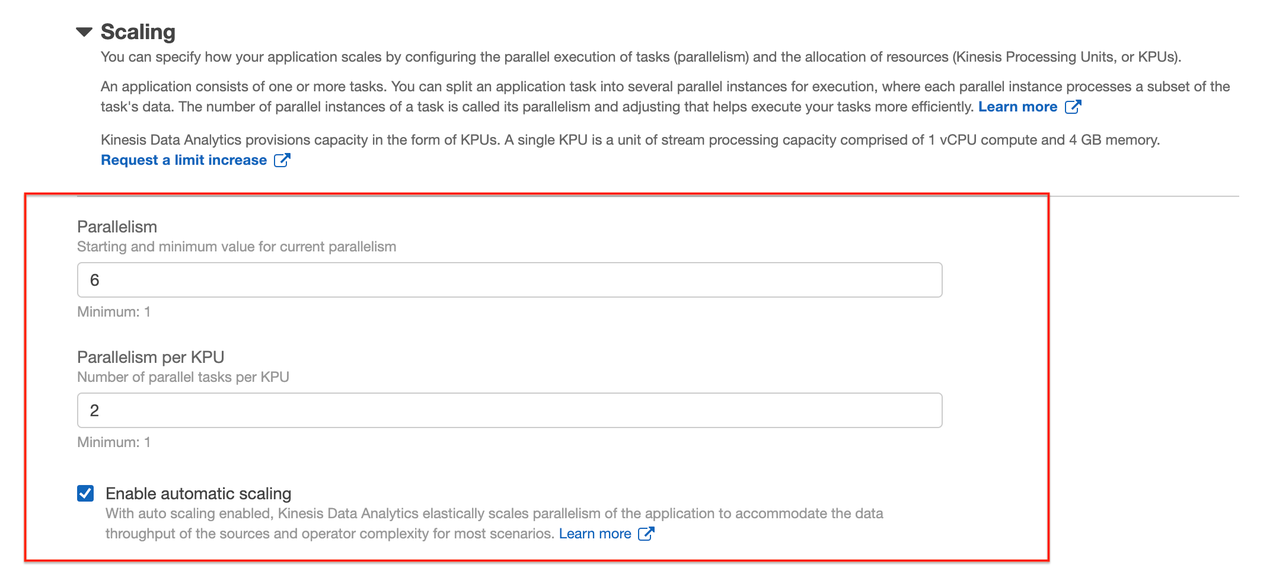
You can calibrate the scaling operation based on your application needs by adjusting the KPU.
- On the Kinesis Data Analytics console, navigate to your application.
- Under Scaling, choose Configure.
- Adjust Parallelism to
6and Parallelism per KPU to2. - Choose Update.
The other method that you can apply to improve throughput is the AsyncIO function. You can make AsyncIO calls asynchronously to improve throughput while other requests are in progress. The two essential parameters when defining an AsyncFunction are Capacity (how many requests are in-flight concurrently per parallel sub-task) and Timeout (the timeout duration of an individual request to the external data source). It helps if you allocate enough capacity to account for the throughput, but not more than the external data source can handle. For example, application with a parallelism of 5 and a capacity of 10 sends 50 concurrent requests to your external data source. You can learn more about using the AsyncIO function with Kinesis Data Analytics for Apache Flink on the GitHub repo.
Conclusion
In this post, you built a reliable, scalable, and highly available streaming application based on Apache Flink and Kinesis Data Analytics. You also scaled the different components while ingesting and analyzing thousands of events per second in near-real time. The solution utilizes managed services without having to provision and configure underlying infrastructure. The post also discussed what it takes to auto scale your application based on metrics such as CPU utilization and millisBehindLatest. The sources of the AWS CloudFormation templates used in this post are available from GitHub for your reference.
You now know how to build a real-time streaming application using Kinesis Data Analytics on AWS. You can also calibrate KPUs based on your application needs and volume of data. Check out Part 2 of this post to explore advanced monitoring techniques and auto scale your real-time streaming application, adapting with streaming data.
About the Author
 Amit Chowdhury is a Partner Solutions Architect in the Global System Integrator (GSI) team at Amazon Web Services. He helps AWS GSI partners migrate customer workloads to AWS, and provides guidance to build, design, and architect scalable, highly available, and secure solutions on AWS by applying AWS recommended best practices. He enjoys spending time with his family, outdoor adventures and traveling.
Amit Chowdhury is a Partner Solutions Architect in the Global System Integrator (GSI) team at Amazon Web Services. He helps AWS GSI partners migrate customer workloads to AWS, and provides guidance to build, design, and architect scalable, highly available, and secure solutions on AWS by applying AWS recommended best practices. He enjoys spending time with his family, outdoor adventures and traveling.
 Saurabh Shrivastava is a solutions architect leader and analytics specialist working with global systems integrators. He works with AWS Partners and customers to provide them with architectural guidance for building scalable architecture in hybrid and AWS environments. He enjoys spending time with his family outdoors and traveling to new destinations to discover new cultures.
Saurabh Shrivastava is a solutions architect leader and analytics specialist working with global systems integrators. He works with AWS Partners and customers to provide them with architectural guidance for building scalable architecture in hybrid and AWS environments. He enjoys spending time with his family outdoors and traveling to new destinations to discover new cultures.