AWS Big Data Blog
Build and optimize real-time stream processing pipeline with Amazon Kinesis Data Analytics for Apache Flink, Part 2
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more.
In Part 1 of this series, you learned how to calibrate Amazon Kinesis Data Streams stream and Apache Flink application deployed in Amazon Kinesis Data Analytics for tuning Kinesis Processing Units (KPUs) to achieve higher performance. Although the collection, processing, and analysis of spiky data stream in real time is crucial, reacting to the spiky data is equally important in many real-life situations as derived insights diminish with time.
In order to build a highly responsive scalable streaming application, we need to auto-scale both Kinesis Data Streams and Kinesis Data Analytics application based on incoming data streams. Refer this blog to know how to easily monitor and automatically scale your Apache Flink application with Amazon Kinesis Data Analytics. Use Kinesis Scaling Utility, which is designed to give you the ability to scale Amazon Kinesis Streams in the same way that you scale EC2 Auto Scaling groups – up or down by a count or as a percentage of the total fleet. You can simply scale to an exact number of Shards.
In this post, we dive deep into important metrics to generate meaningful insights about the health and performance of the Amazon Kinesis Data Analytics for Apache Flink application. We will also walk you through steps to build a fully automated, scalable, and highly available pipeline to handle streaming data scaling in and out for both the Kinesis data stream (based on incoming records) and Kinesis data analytics application (by calibrating KPUs and parallelism). You use AWS Managed Services to reduce operational overhead compared to the manual approach of scaling the streaming application. Because this is a continuation of the previous post, make sure to walk through Part 1 as a prerequisite before deploying the automated pipeline code in this post.
Deploy the advanced monitoring and scaling architecture
This section uses an AWS CloudFormation template to build an advanced monitoring dashboard to capture vital metrics data. You also create an advanced scaling environment to auto scale the Kinesis data stream and Kinesis data analytics application, which scales both services in and out depending on the volume of spiky data. Furthermore, we use managed services for better operational efficiency. The template builds the following architecture.

The CloudFormation template includes the following components:
- An advanced Amazon CloudWatch dashboard
- Two CloudWatch alarms for scaling your Kinesis Data Analytics for Apache Flink application
- Two CloudWatch alarms for scaling your Kinesis Data Streams
- Accompanying auto scaling policy actions in these alarms
- An Amazon API Gateway endpoint for triggering AWS Lambda
- A Lambda function responsible for handling the scale-in and scale-out functions
These components work in tandem to monitor the metrics configured in the CloudWatch alarm and respond to metrics accordingly.
To provision your resources, complete the following steps:
- Choose Launch Stack (right-click) to open a new tab to run the CloudFormation template. Make sure to choose us-east-1 (N. Virginia) region.
- Choose Next.
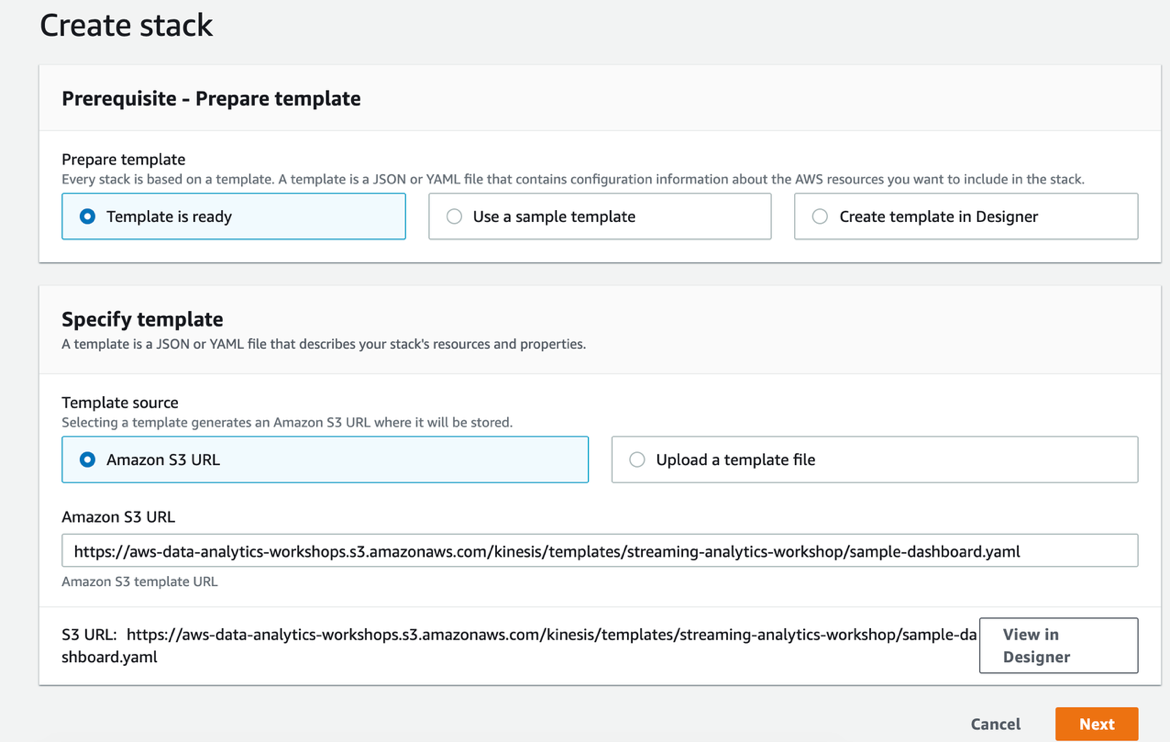
- For FlinkApplicationName, enter the name of your application.
- For KinesisStreamName, enter the name of your data stream.
- Make sure ShardCount is same as the current shard count of Kinesis Data Streams created in Part 1.
This information is available on the Outputs tab of the CloudFormation stack detailed in Part 1.
- Choose Next.

- Follow the remaining instructions and choose Create stack.
This dashboard should take a few minutes to launch.
- When the stack is complete, go to the Outputs tab of the stack on the AWS CloudFormation console and choose the dashboard link.
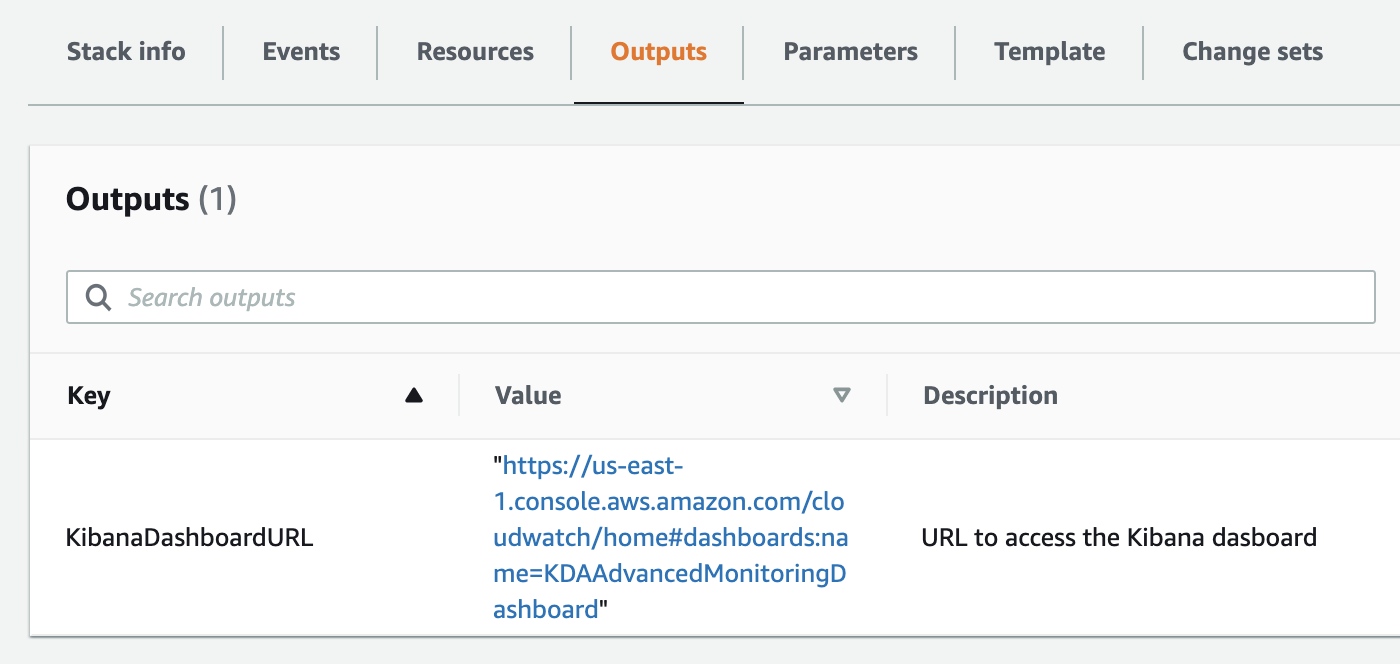 Metrics deep dive
Metrics deep dive
There are many critical operational metrics to measure when assessing the performance of a running Apache Flink application. This section looks at the essential CloudWatch metrics for Kinesis Data Analytics for Apache Flink applications, what they mean, and what appropriate alarms might be vital indicators for each. Let’s dive into how to monitor your application.
First, let’s look at the running application using our CloudWatch dashboard and point out potential issues with a given Apache Flink application indicated by our CloudWatch metrics.
The Application Health section of this dashboard can help identify fundamental issues with your application that are causing it to be inoperable. Let’s start with the first two cells: Uptime and Downtime. In an ideal state, this is precisely how your application should look—uptime measures the cumulative time in milliseconds that the application has been running without interruption, and downtime measures the time elapsed during an outage.

In an ideal state, your lastCheckpointSize and lastCheckpointDuration metrics should remain relatively stable over time. If you observe an increasing checkpoint size, this can indicate a state not being cleared within your application or a memory leak. Similarly, a longer and unexpected spike in checkpoint duration can cause backpressure of your application. Monitor these metrics for stability over time.
The resource utilization metrics section gives a glimpse into the resource usage of the running Flink application. In a healthy application, try to keep this metric under 75% usage. This is also the same metric that Kinesis Data Analytics for Apache Flink uses to auto scale your application if you have auto scaling enabled. Also, it’s normal to see CPU spikes during application startup or restart. HeapMemoryUtilization measures the memory taken up by the application, on-heap state, and any other operations that may take up memory space.
Let’s now evaluate our Flink application progress. Incoming and outgoing records per second are measured on an application level in this image. You can also measure them on a task or subtask level for finer granularity and visibility into the operators of your application. The ideal state for these depends on the use case, but if it’s a straight read, process, and write action without filtering the records, you can expect to see an equal amount of records in and out per second. If a deviation occurs on either end of these metrics, it’s a good indicator of where the bottleneck is. If numRecordsInPerSecond is lower, the source might be configured to read in less data, or it could be indicative of backpressure on the sink causing a slowdown. If numRecordsOutPerSecond is lower, it could be identifying a slow operator process in the middle of your application.
Next, let’s look at InputandOutputWatermark and EventTimeLatency. The watermarks indicate the eventTime with which data is arriving into the data stream. A large difference between these two values could indicate significantly late-arriving data into the stream. Your stream should handle this according to your use case, and EventTimeLatency measures the total latency, or OutputWatermark and InputWatermark, of the streaming workload.
The LateRecordsDropped metric measures the number of records dropped due to arriving late. If this number is spiking, there is an issue with data arriving late to the Flink application.

Now let’s dive into Kinesis source and sink metrics. The millisBehindLatest metric shows the time the consumer is behind the head of the stream, which is a good indicator of how far behind the consumer’s current time is. You can measure this metric on an application or a parallelism level—a value of 0 shows that the application is completely caught up with processing records. This is ideal; a higher value means that the application is falling behind. It could indicate that the consumer isn’t tuned to read records efficiently, backpressure, or some slowness in processing. Scale the application accordingly.
The RetriesPerRecord, UserRecordsPending, and BufferingTime metrics come from the Kinesis Producer Library (KPL), and in this case, is referring to our terminal script, which is writing to the Kinesis data stream. All applications that use the KPL report this metric, and it’s important to monitor in case of frequent retries or timeouts. The other metrics can grow exceedingly large if the data stream is under-provisioned.

Advanced scaling
Let’s dive deep into how to scale your Kinesis data analytics application based on the previously discussed metrics. The only way to scale a Kinesis data analytics application automatically is to use the built-in auto scale feature. This feature monitors your application’s CPU usage over time, and if it remains at 75% or above for 15 minutes, it increases your application’s overall parallelism. You experience some downtime during this scale-up, and an application developer should take this into account when using the auto scaling feature. It’s an excellent and helpful feature of Kinesis Data Analytics for Apache Flink. However, some applications need to scale based on other factors, not just CPU usage. In this section, we look at an external way to scale your application based on IncomingRecords or millisBehindLatest metrics on the source Kinesis data stream.
To add the functionality of scaling based on other metrics, we utilize Application Auto Scaling to specify our scaling policy and other attributes, such as cooldown periods. We can also take advantage of any auto scaling types—step scaling, target tracking scaling, and schedule-based scaling. The CloudFormation template we launched already created the necessary resources covering step scaling. For a more detailed list, view the Resources tab on the AWS CloudFormation console or view the designer before launching.
Currently, the settings are tuned to the max throughput per KPU, which is ideal for a production workload. Let’s tune this setting down to a lower value to more quickly see results.
- On the CloudWatch console, choose Alarms in the navigation pane.
- Choose the alarm
KDAScaleOutAlam.

The alarm has been preconfigured for you in CloudWatch to listen for specific metrics breaching a threshold. Optionally, you can adjust the alarm to trigger scale-out or scale-in events as needed.
- On the Actions menu, choose Edit.

- In the Conditions section, adjust the threshold value as needed.
- Choose Update alarm.
You can also use the speedup value in the ProducerCommand found in the outputs of the CloudFormation stack from Part 1 to increase and decrease data volume per second, replicating real-life scenarios of spiky data. Observe the CloudWatch alarms changing states between OK and In alarm. When in alarm, it triggers auto scaling of the Kinesis data stream scaling in or out many shards. Alarms also scale KPUs allocated to the Kinesis data analytics application.
- Navigate back to your Kinesis data analytics application.
- On the Details tab, see in the Scaling section if this alarm has impacted the parallelism.

- Alternatively, stop the producer in the terminal.
Turning off the producer should show an inverse effect, causing the application to trigger the KDAScaleInAlarm, and the application parallelism should scale back down in a few minutes.
- On the Configuration tab of your data stream, observe the scaling operation of allocated shards.
You can open the Apache Flink dashboard from your Kinesis data analytics application, analyze the application performance, and troubleshoot by looking at Flink job-level insights, Flink task-level insights, Flink exceptions, and checkpoints. You can also calibrate your application by looking at the Flink dashboard metrics, which gives you additional granularity out of the box, and using the metrics for debugging purposes.
Conclusion
In this post, you built a reliable, scalable, and highly available advanced scaling mechanism for streaming applications based on Kinesis Data Analytics for Apache Flink and Kinesis Data Streams. The post also discussed how to auto scale your applications based on a metric other than CPU utilization and explored ways to extend observability of the application with advanced monitoring and error handling. This solution was largely enabled by using managed services, so you didn’t need to spend time provisioning and configuring the underlying infrastructure. The sources of the AWS CloudFormation templates used in this post are available from GitHub for your reference.
You should now have a good understanding of how to build, monitor and auto scale a real-time streaming application using Amazon Kinesis. You can also calibrate various components based on your application needs and volume of data by applying advanced monitoring and scaling techniques.
About the Authors
 Amit Chowdhury is a Partner Solutions Architect in the Global System Integrator (GSI) team at Amazon Web Services. He helps AWS GSI partners migrate customer workloads to the AWS Cloud, and provides guidance to build, design, and architect scalable, highly available, and secure solutions on AWS by applying AWS recommended best practices. He enjoys spending time with his family, outdoor adventures and traveling.
Amit Chowdhury is a Partner Solutions Architect in the Global System Integrator (GSI) team at Amazon Web Services. He helps AWS GSI partners migrate customer workloads to the AWS Cloud, and provides guidance to build, design, and architect scalable, highly available, and secure solutions on AWS by applying AWS recommended best practices. He enjoys spending time with his family, outdoor adventures and traveling.
 Saurabh Shrivastava is a solutions architect leader and analytics specialist working with global systems integrators. He works with AWS Partners and customers to provide them with architectural guidance for building scalable architecture in hybrid and AWS environments. He enjoys spending time with his family outdoors and traveling to new destinations to discover new cultures.
Saurabh Shrivastava is a solutions architect leader and analytics specialist working with global systems integrators. He works with AWS Partners and customers to provide them with architectural guidance for building scalable architecture in hybrid and AWS environments. He enjoys spending time with his family outdoors and traveling to new destinations to discover new cultures.