AWS Compute Blog

Author: James Beswick
James Beswick leads the Serverless Developer Advocacy team at AWS. He works with AWS's developer customers to understand how serverless technologies can drastically change the way they think about building and running applications at massive scale with minimal administration overhead. Visit https://serverlessland.com for more serverless content.

Combining Amazon AppFlow with AWS Step Functions to maximize application integration benefits
This blog post explores how to integrate Amazon AppFlow and AWS Glue using Step Functions to automate your business requirements. You can use AWS Lambda to simplify the configuration phase and reduce state transitions or create complex checks, filters, or even data cleansing and preparation.

Optimizing your AWS Lambda costs – Part 2
Cost optimization is an important part of creating well-architected solutions and this is no different when using serverless. This blog series explores some best practice techniques to help reduce your Lambda bill.

Optimizing your AWS Lambda costs – Part 1
This blog post explains how Lambda pricing works and how right-sizing applications and tuning them for performance efficiency offers a more cost-efficient utilization model. The results can also reduce latency, creating a better experience for your end users.

Testing Amazon EventBridge events using AWS Step Functions
This blog post outlines how to use Step Functions, Lambda, SQS, DynamoDB, and S3 to create a workflow that automates the testing of EventBridge events. With this example, you can send events to the EventBridge Event Tester endpoint to verify that event delivery is successful or identify the root cause for event delivery failures.

Node.js 16.x runtime now available in AWS Lambda
This post is written by Dan Fox, Principal Specialist Solutions Architect, Serverless. You can now develop AWS Lambda functions using the Node.js 16 runtime. This version is in active LTS status and considered ready for general use. To use this new version, specify a runtime parameter value of nodejs16.x when creating or updating functions or by using the appropriate […]

Handling Lambda functions idempotency with AWS Lambda Powertools
Idempotency is a critical piece of serverless architectures and can be difficult to implement. If not done correctly, it can lead to inconsistent data and other issues. This post shows how you can use Lambda Powertools to make Lambda functions idempotent and ensure that critical transactions are handled only once.
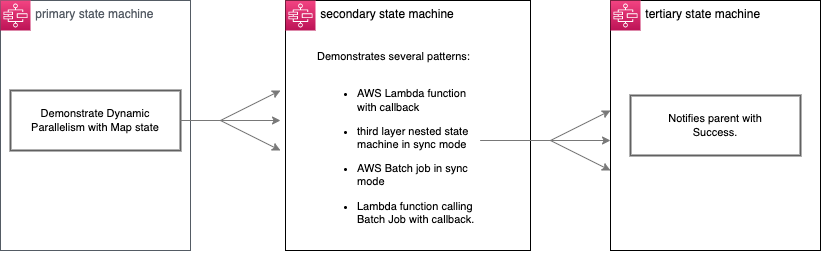
Orchestrating high performance computing with AWS Step Functions and AWS Batch
This blog post describes several challenges common to orchestrating HPC workloads. I describe how Step Functions with AWS Batch can solve many of these challenges. I provide a project that contains several sample patterns and show how to deploy and test this in your account.

Introducing global endpoints for Amazon EventBridge
This blog shows how to create an EventBridge global endpoint to improve the availability and reliability of event ingestion of event-driven applications. This example shows how to use the PutEvents in the Python AWS SDK to publish events to a global endpoint.
ICYMI: Serverless Q1 2022
Welcome to the 17th edition of the AWS Serverless ICYMI (in case you missed it) quarterly recap. Every quarter, we share all the most recent product launches, feature enhancements, blog posts, webinars, Twitch live streams, and other interesting things that you might have missed! In case you missed our last ICYMI, check out what happened […]

Using AWS Step Functions and Amazon DynamoDB for business rules orchestration
In this post, you learned how to leverage an orchestration framework using Step Functions, Lambda, DynamoDB, and API Gateway to build an API backed by an open-source Drools rules engine, running on a container. Try this solution for your cloud native business rules orchestration use-case.