AWS Compute Blog
Optimizing deep learning on P3 and P3dn with EFA
This post is written by Rashika Kheria, Software Engineer, Purna Sanyal, Senior Solutions Architect, Strategic Account and James Jeun, Sr. Product Manager, and Amr Ragab
The Amazon EC2 P3dn.24xlarge instance is the latest addition to the Amazon EC2 P3 instance family, with upgrades to several components. This high-end size of the P3 family allows users to scale out to multiple nodes for distributed workloads more efficiently. With these improvements to the instance, you can complete training jobs in a shorter amount of time and iterate on your Machine Learning (ML) models faster.
This blog reviews the significant upgrades with p3dn.24xlarge, walks you through deployment, and shows an example ML use case for these upgrades.
Overview of P3dn instance upgrades
The most notable upgrade to the p3dn.24xlarge instance is the 100-Gbps network bandwidth and the new EFA network interface that allows for highly scalable internode communication. This means you can scale runs on applications to use thousands of GPUs, which reduces time to get results. EFA’s operating system bypasses networking mechanisms and the underlying Scalable Reliable Protocol that is built in to the Nitro Controllers. The Nitro controllers enable a low-latency, low-jitter channel for inter-instance communication. EFA has been adopted in the mainline Linux and integrated with LibFabric and various distributions. AWS worked with NVIDIA for EFA to support NVIDIA Collective Communication Library (NCCL). NCCL optimizes multi-GPU and multi-node communication primitives and helps achieve high throughput over NVLink interconnects.
The following diagram shows the PCIe/NVLink communication topology used by the p3.16xlarge and p3dn.24xlarge instance types.
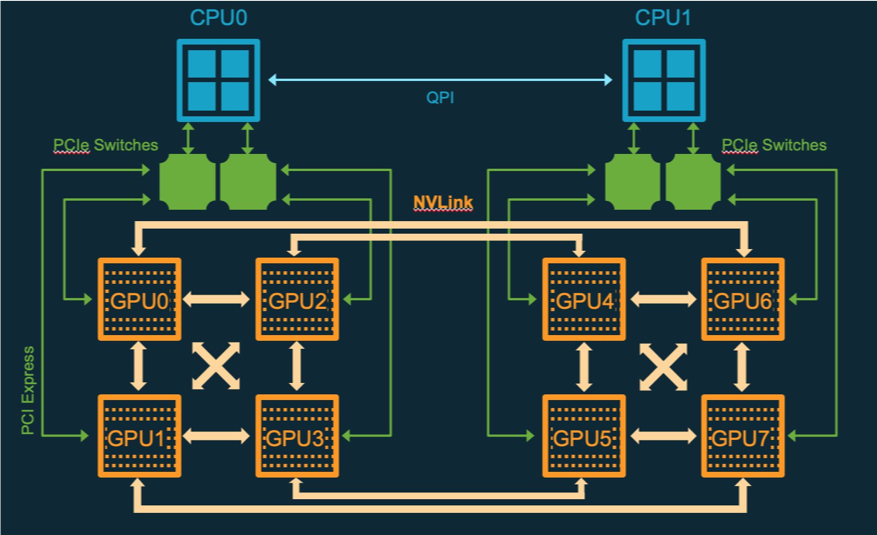
The following table summarizes the full set of differences between p3.16xlarge and p3dn.24xlarge.
| Feature | p3.16xl | p3dn.24xl |
| Processor | Intel Xeon E5-2686 v4 | Intel Skylake 8175 (w/ AVX 512) |
| vCPUs | 64 | 96 |
| GPU | 8x 16 GB NVIDIA Tesla V100 | 8x 32 GB NVIDIA Tesla V100 |
| RAM | 488 GB | 768 GB |
| Network | 25 Gbps ENA | 100 Gbps ENA + EFA |
| GPU Interconnect | NVLink – 300 GB/s | NVLink – 300 GB/s |
P3dn.24xl offers more networking bandwidth than p3.16xl. Paired with EFA’s communication library, this feature increases scaling efficiencies drastically for large-scale, distributed training jobs. Other improvements include double the GPU memory for large datasets and batch sizes, increased system memory, and more vCPUs. This upgraded instance is the most performant GPU compute option on AWS.
The upgrades also improve your workload around distributed deep learning. The GPU memory improvement enables higher intranode batch sizes. The newer Layer-wise Adaptive Rate Scaling (LARS) has been tested with ResNet50 and other deep neural networks (DNNs) to allow for larger batch sizes. The increased batch sizes reduce wall-clock time per epoch with minimal loss of accuracy. Additionally, using 100-Gbps networking with EFA heightens performance with scale. Greater networking performance is beneficial when updating weights for a large number of parameters. You can see high scaling efficiency when running distributed training on GPUs for ResNet50 type models that primarily use images for object recognition. For more information, see Scalable multi-node deep learning training using GPUs in the AWS Cloud.
Natural language processing (NLP) also presents large compute requirements for model training. This large compute requirement is especially present with the arrival of large Transformer-based models like BERT and GPT-2, which have up to a billion parameters. The following describes how to set up distributed model trainings with scalability for both image and language-based models, and also notes how the AWS P3 and P3dn instances perform.
Optimizing your P3 family
First, optimize your P3 instances with an important environmental update. This update runs traditional TCP-based networking and is in the latest release of NCCL 2.4.8 as of this writing.
Two new environmental variables are available, which allow you to take advantage of multiple TCP sockets per thread: NCCL_SOCKET_NTHREADS and NCCL_NSOCKS_PERTHREAD.
These environmental variables allow the NCCL backend to exceed the 10-Gbps TCP single stream bandwidth limitation in EC2.
Enter the following command:
The following graph shows the synthetic NCCL tests and their increased performance with the additional directives.
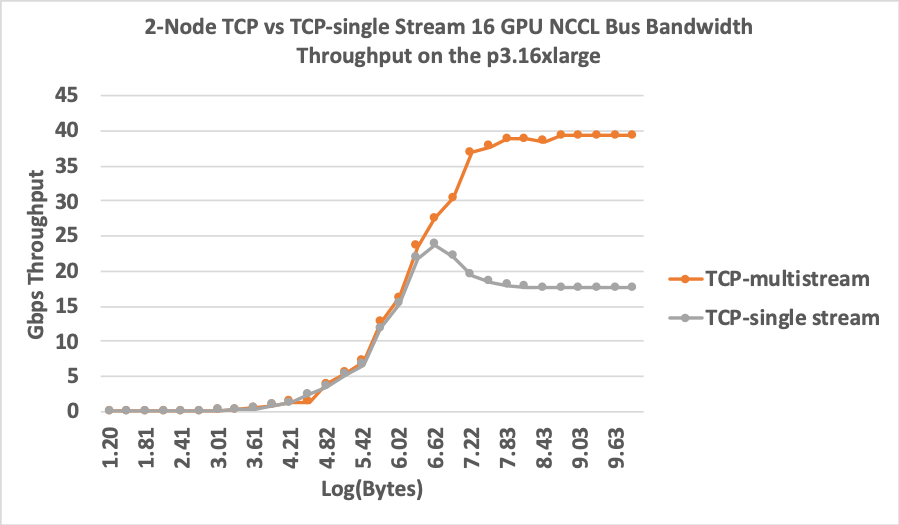
You can achieve a two-fold increase in throughput after a threshold in the synthetic payload size (around 1 MB).
Deploying P3dn
The following steps walk you through spinning up a cluster of p3dn.24xlarge instances in a cluster placement group. This allows you to take advantage of all the new performance features within the P3 instance family. For more information, see Cluster Placement Groups in the Amazon EC2 User Guide.
This post deploys the following stack based on the Deep learning AMI version 20.2:
- Deep Learning Base AMI
- NVIDIA Driver 418.87.01
- CUDA 10.1 / cuDNN 7.6.2 / NCCL 2.4.8
- CUDA 10.0 / cuDNN 7.5.1 / NCCL 2.4.8
- CUDA 9.0 / cuDNN 7.3.1 / NCCL 2.3.5
- CUDA 9.2 / cuDNN 7.3.1 / NCCL 2.3.5
- EFA Driver 1.5.1
- Compiled NCCL 2.4.8
- AWS-OFI-NCCL
- NCCL-tests
- OpenMPI 3.1.4
The latest DLAMI is ready to use with EFA and comes with the required drivers, kernel modules, libfabric, openmpi and the NCCL OFI plugin for GPU instances.
Supported CUDA Versions: NCCL Applications with EFA are only supported on CUDA-10.0 and CUDA-10.1 because the NCCL OFI plugin requires a NCCL version > 2.4.2.
Note:
- When running a NCCL Application using mpirunon EFA, you will have to specify the full path to the EFA supported installation as:
- To enable your application to use EFA, add
FI_PROVIDER="efa"to thempiruncommand as shown in Using EFA on the DLAMI.
Please refer to this documentation for steps on launching an AWS Deep Learning AMI Instance with EFA.
Synthetic two-node performance
This blog includes the NCCL-tests GitHub as part of the deployment stack. This shows synthetic benchmarking of the communication layer over NCCL and the EFA network.
When launching the two-node cluster, complete the following steps:
- Place the instances in the cluster placement group.
- SSH into one of the nodes.
- Fill out the hosts file.
- Run the two-node test with the following code:
This test makes sure that the node performance works the way it is supposed to.
The following graph compares the NCCL bandwidth performance using -x FI_PROVIDER="efa" vs. -x FI_PROVIDER="tcp“. There is a three-fold increase in bus bandwidth when using EFA.
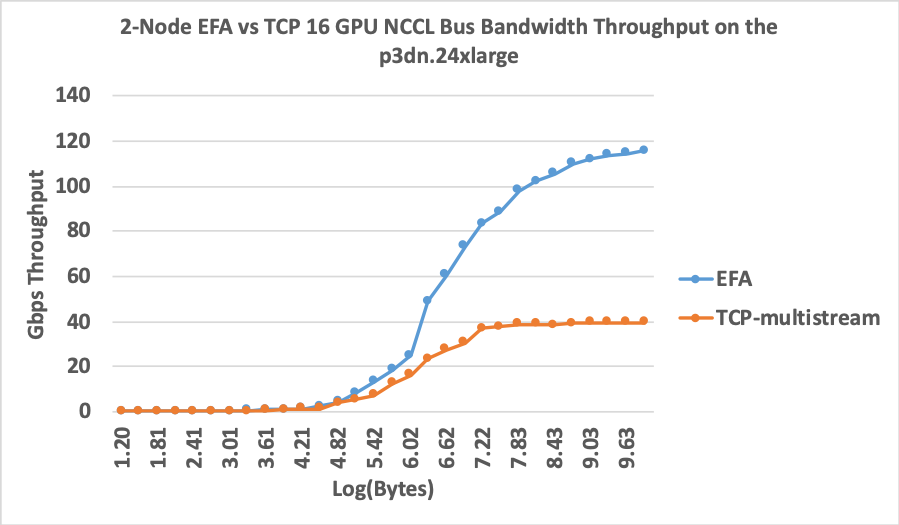
Now that you have run the two node tests, you can move on to a deep learning use case.
FAIRSEQ ML training on a P3dn cluster
Fairseq(-py) is a sequence modeling toolkit that allows you to train custom models for translation, summarization, language modeling, and other text-generation tasks. FAIRSEQ MACHINE TRANSLATION distributed training requires a fast network to support the Allreduce algorithm. Fairseq provides reference implementations of various sequence-to-sequence models, including convolutional neural networks (CNN), long short-term memory (LSTM) networks, and transformer (self-attention) networks.
After you receive consistent 10 GB/s bus-bandwidth on the new P3dn instance, you are ready for FAIRSEQ distributed training.
To install fairseq from source and develop locally, complete the following steps:
- Copy FAIRSEQ source code to one of the P3dn instance.
- Copy FAIRSEQ Training data in the data folder.
- Copy FAIRSEQ Test Data in the data folder.
git clone https://github.com/pytorch/fairseq
Now that you have FAIRSEQ installed, you can run the training model. Complete the following steps:
- Run FAIRSEQ Training in 1 node/8 GPU p3dn instance to check the performance and the accuracy of FAIRSEQ operations.
- Create a custom AMI.
- Build the other 31 instances from the custom AMI.
Use the following scripts for distributed All Reduce FAIRSEQ Training :
Now that you have completed and validated your base infrastructure layer, you can add additional components to the stack for various workflows. The following charts show time-to-train improvement factors when scaling out to multiple GPUs for FARSEQ model training.
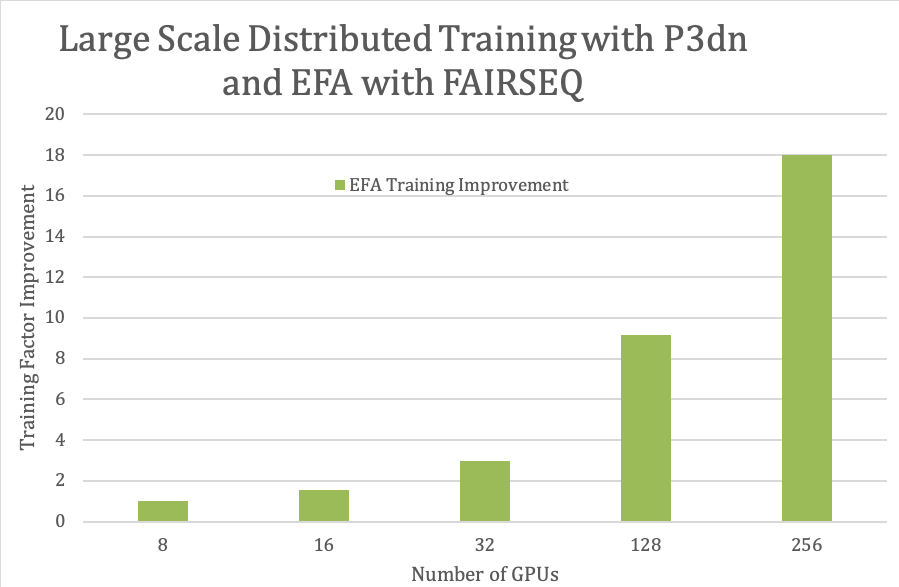
Conclusion
EFA on p3dn.24xlarge allows you to take advantage of additional performance at scale with no change in code. With this updated infrastructure, you can decrease cost and time to results by using more GPUs to scale out and get more done on complex workloads like natural language processing. This blog provides much of the undifferentiated heavy lifting with the DLAMI integrated with EFA. Go power up your ML workloads with EFA!