AWS Compute Blog
Running high-scale web applications on Amazon EC2 Spot Instances
NOTE: Amazon EC2 Auto Scaling groups now lets you mix On-Demand, Spot and RIs, as well as different instance types, as described here. In the architecture described below, the Spot Fleet component can be replaced by an EC2 Auto Scaling groups.
Contributed by Ran Sheinberg, Spot Specialist Solutions Architect, and the Appnext team
At re:Invent in 2017, AWS made some significant changes to the pricing model of Amazon EC2 Spot Instances. Instead of bidding on spare capacity, you could request to run Spot Instances, and get the capacity if it’s available.
One of the results of that change is fewer interruptions to Spot Instances. In fact, more than 95% of Spot Instances are terminated by the customer and not by EC2 interruptions. For more information about the average interruption rate for each instance type in an AWS Region, see the Spot Instance Advisor.
Customers use Spot Instances differently, depending on the type of workload:
- Time-insensitive—These are workloads that are not SLA-bound, or are possibly internal and not public-facing. Examples: scientific computations, dev/test, batch jobs, model training in machine learning or deep learning, etc.
- Time sensitive workloads—These are workloads that serve end users or which must be highly available and fault tolerant. Examples: website hosting and web services, APIs, containers running behind load balancers, etc.
When you run a time-insensitive workload such as a batch job, Spot interruptions could still affect some of your EC2 capacity. Generally, your job continues and tasks are rescheduled on new instances (for example, if you’re using AWS Batch).
In this post, I focus on time-sensitive workloads where Spot instance interruptions can potentially impact end users. In these scenarios, it is required to architect the workload properly to handle the two-minute warning to avoid outages or disconnections by following Cloud best practices.
My recommendations include avoiding state or end-user stickiness to specific instances, architecting for fault tolerance, decoupling the components of the application with queueing mechanisms, and keeping compute and storage decoupled as well.
Spot Instances
Spot Instances are spare compute capacity in the AWS Cloud. They are available to customers at up to 90% discount compared to On-Demand prices.
Spot Instances can be interrupted by Amazon EC2 with a two-minute warning, in case EC2 must reclaim capacity. Spot Instances are available in different capacity pools (comprised of an instance type and an Availability Zone in each AWS Region). We recommend that you deploy your workload across several (or many) Spot capacity pools to maximize the cost savings and obtain desired scale.
The Taking Advantage of Amazon EC2 Spot Instance Interruption Notices post walks you through preparing a workload for the interruption, by draining connections from the instance and detaching it from the Application Load Balancer (ALB).
Appnext
AWS and Spot Instances are popular in the ad tech industry, which is a great example of customers running business-critical web applications. Their workloads require a high request rate, low latency, and support for spiky traffic rates throughout the day in real-time bidding and similar applications.
Ad tech startup Appnext is a great example of a tech-savvy AWS customer, and they chose to run the EC2 instances for their business critical applications on Spot Instances, for cost saving purposes. Appnext’s technology allows advertisers to tap into users’ daily timelines, reaching them at crucial moments throughout their day, so the application’s availability is key for Appnext.
Instance diversification and capacity pools
To achieve their desired scale, Appnext uses a Spot Fleet to diversify their instances easily across many Spot Instance pools. Diversification of capacity is key when using Spot Instances for highly available applications. Customers like Appnext configure their Spot Fleets to use as many EC2 instance types as possible in all the Availability Zones in each region where the application is running. They choose the instance types that are supported by their application use case and required hardware specifications. Diversification also enables you to get Spot capacity at the lowest prices, using the suitable allocation strategy.
Appnext is prepared for rare situations where Spot capacity is unavailable in all their chosen Spot capacity pools, by automatically adding On-Demand Instances behind the Classic Load Balancer. According to the Appnext team, this is something they hardly ever encounter.
Each instance family and instance size in each Availability Zone in every Region is a separate Spot capacity pool. Each orange square in the following graphic is a capacity pool. This is true for each instance family (C4, C5, M5, R4…) in each AWS Region (the prices are just examples).

High-scale web applications on Spot Instances
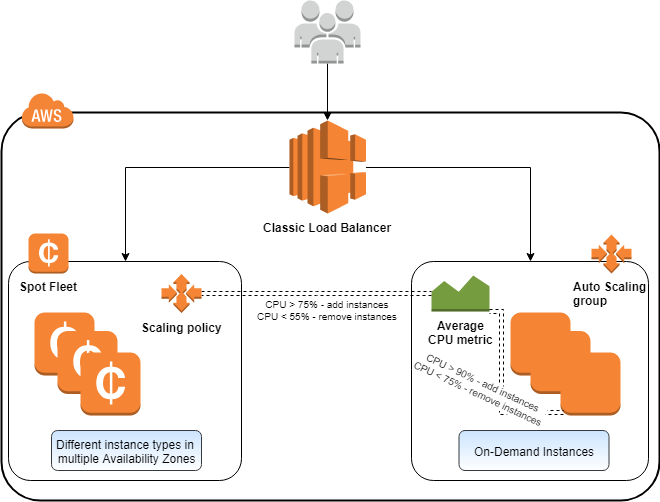
Appnext’s goal is to run EC2 capacity behind a Classic Load Balancer that is sufficient to provide both high performance and highly available service. It should use as much Spot capacity as possible during automatic scaling. At the same time, it’s important to decrease the risk of application impact due to Spot interruptions. If Spot capacity is insufficient, additional On-Demand capacity behind the Classic Load Balancer is ready to scale out fast.
To achieve this goal, Appnext set up the following components. The actual CloudWatch metric thresholds are examples, as these vary across the different applications and regions.
- Spot Fleet—This is the main supplier of Spot Instances that are automatically joined as targets behind the Classic Load Balancer when launched. The Spot Fleet is configured with an automatic scaling policy. It only adds Spot Instances if the average CPU of the On-Demand Instances passes the 75% threshold for 10 minutes. It terminates instances if the CPU utilization goes below a 55% CPU threshold.
- Auto Scaling group for On-Demand Instances—This is the secondary supplier of EC2 instances for the Classic Load Balancer. The Auto Scaling group is configured with 1–2 static On-Demand Instances. It scales out when the average CPU utilization of the instances in the Auto Scaling group passes the 90% threshold for 10 minutes. It terminates instances when the threshold goes below 75%.
If Spot Fleet is unable to fulfill the target capacity and scale out due to lack of capacity in the selected Spot capacity pools, On-Demand Instances are started instead. The CPU utilization of the existing On-Demand Instances in the EC2 Auto Scaling group increases. This setup has proven to be a great fit for Appnext’s application, because it is CPU-bound, and increased application usage is always reflected in increased CPU utilization.
Because the Spot Fleet is well-diversified across a large number of Spot capacity pools, there is hardly ever any need to launch On-Demand Instances. That keeps the EC2 compute costs of the application low while it is still being architected for availability.
Lastly, the Auto Scaling group for the On-Demand Instance is configured to use an instance type that is not configured in the Spot Fleet. This is a best practice to avoid trying to launch On-Demand Instances to replace Spot capacity in a pool that is already depleted.
By launching Spot Instances using Spot Fleet and On-Demand Instances using Auto Scaling groups, Appnext is able to decouple the metrics and scaling policies used by each of the instance groups. This is despite the fact that you can launch On-Demand Instances in Spot Fleet.
The following diagram shows how the components work together.
Coming soon
In the EC2 Fleet Manages Thousands of On-Demand and Spot Instances with One Request post that introduced EC2 Fleet, the author mentions that there will be an integration to EC2 Auto Scaling groups. If you were already using Auto Scaling groups, you would be able to diversify the usage of Spot and On-Demand Instances with different instance types. When this feature is released, you will be able to do this all from within Auto Scaling groups without using Spot Fleet or EC2 Fleet directly.
Conclusion
I hope you found this post useful. If you haven’t tried Spot Instances yet, I suggest testing them for your web applications to optimize compute costs.