AWS Compute Blog
Using AWS ParallelCluster serverless API for AWS Batch
This post is courtesy of Dario La Porta, Senior Consultant, HPC.
This blog is a continuation of a series of posts demonstrating how to create serverless architectures to support HPC workloads run with AWS ParallelCluster.
The first post, Using AWS ParallelCluster with a serverless API, explains how to create a serverless API for the AWS ParallelCluster command line interface. The second post, Amazon API Gateway for HPC job submission, shows how to submit jobs to a cluster that uses a Slurm job scheduler through a similar serverless API. In this post, I create a serverless API of the AWS Batch command line interface inside ParallelCluster. This uses AWS ParallelCluster, Amazon API Gateway, and AWS Lambda.
The integration of ParallelCluster with AWS Batch replaces the need of third-party batch processing solutions. It also natively integrates with the AWS Cloud.
Many use cases can benefit from this approach. The financial services industry can automate the resourcing and scheduling of the jobs to accelerate decision-making and reduce cost. Life sciences companies can discover new drugs in a more efficient way.
Submitting HPC workloads through a serverless API enables additional workflows. You can extend on-premises clusters to run specific jobs on AWS’ scalable infrastructure to leverage its elasticity and scale. For example, you can create event-driven workflows that run in response to new data being stored in an S3 bucket.
Using a serverless API as described in this post can improve security by removing the need to log in to EC2 instances to use the AWS Batch CLI in AWS ParallelCluster.
Together, this class of workflow can further improve the security of your infrastructure and dat. It can also help optimize researchers’ time and efficiency.
In this post, I show how to create the AWS Batch cluster using AWS ParallelCluster. I then explain how to build the serverless API used for the interaction with the cluster. Finally, I explain how to use the API to query the resources of the cluster and submit jobs.
This diagram shows the different components of the solution.

AWS ParallelCluster configuration
AWS ParallelCluster is an open source cluster management tool to deploy and manage HPC clusters in the AWS Cloud.
The same procedure, described in the Using AWS ParallelCluster with a serverless API post, is used to create the AWS Batch cluster in the new template.yml and pcluster.conf file. The template.yml file contains the required policies for the Lambda function to build the AWS Batch cluster. Be sure to modify <AWS ACCOUNT ID> and <REGION> to match the value for your account.
The pcluster.conf file contains the AWS ParallelCluster configuration to build a cluster using AWS Batch as the job scheduler. The master_subnet_id is the id of the created public subnet and the compute_subnet_id is the private one. More information about ParallelCluster configuration file options and syntax are explained in the ParallelCluster documentation.
Deploy the API with AWS SAM
The code used for this example can be downloaded from this repo. Inside the repo:
- The sam-app folder in the aws-sample repository contains the code required to build the AWS ParallelCluster serverless API for AWS Batch.
- sam-app/template.yml contains the policy required for the Lambda function for the creation of the AWS Batch cluster. Be sure to modify
<AWS ACCOUNT ID>and<REGION>to match the value for your account.
AWS Identity and Access Management Roles in AWS ParallelCluster contains the latest version of the policy. See the ParallelClusterInstancePolicy section related to the awsbatch scheduler.
To deploy the application, run the following commands:
cd sam-app
sam build
sam deploy --guided
From here, provide parameter values for the SAM deployment wizard for your preferred Region and AWS account. After the deployment, note the outputs:

SAM deploying:

The API Gateway endpoint URL is used to interact with the API. It has the following format:
https://<ServerlessRestApi>.execute-api.eu-west-1.amazonaws.com/Prod/pclusterbatch
Interact with the AWS Batch cluster using the deployed API
The deployed pclusterbatch API requires some parameters:
command– the pcluster Batch command to execute. A detailed list is available commands is available in the AWS ParallelCluster CLI Commands for AWS Batch page.cluster_name– the name of the cluster.jobid– the jobid string.compute_node– parameter used to retrieve the output of the specified compute node number in a mpi job.--data-binary "$(base64 /path/to/script.sh)"– parameter used to pass the job script to the API.-H "additional_parameters: <param1> <param2> <...>"– used to pass additional parameters.
The cluster’s queue can be listed with the following:
$ curl --request POST -H "additional_parameters: " "https://<ServerlessRestApi>.execute-api.eu-west-1.amazonaws.com/Prod/pclusterbatch?command=awsbqueues&cluster=cluster1"
A cluster job can be submitted with the following command. The job_script.sh is an example script used for the job.
$ curl --request POST -H "additional_parameters: -jn hello" --data-binary "$(base64 /path/to/job_script.sh)" "https://<ServerlessRestApi>.execute-api.eu-west-1.amazonaws.com/Prod/pclusterbatch?command=awsbsub&cluster=cluster1"
![]()
This command is used to check the status of the job:
$ curl --request POST -H "additional_parameters: " "https://<ServerlessRestApi>.execute-api.eu-west-1.amazonaws.com/Prod/pclusterbatch?command=awsbstat&cluster=cluster1&jobid=3d3e092d-ca12-4070-a53a-9a1ec5c98ca0"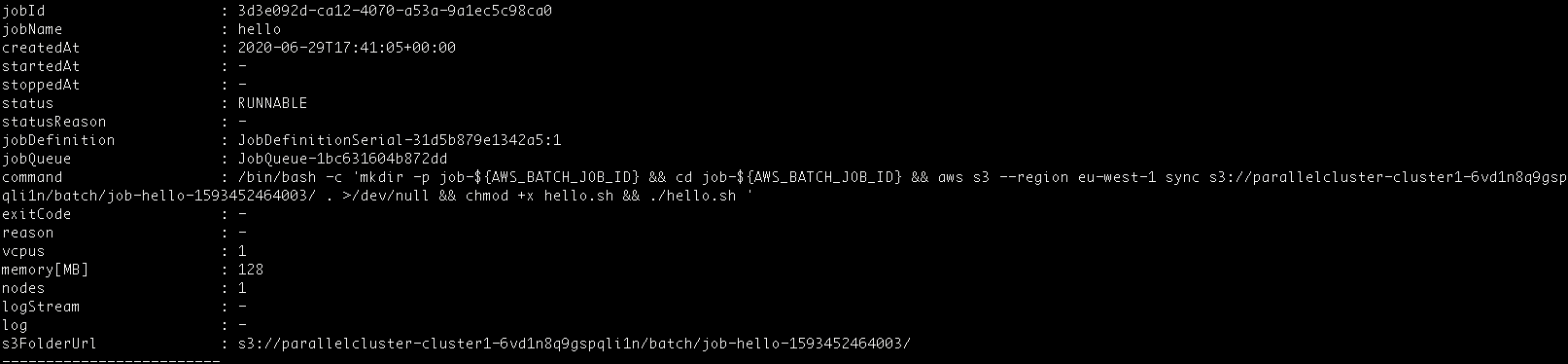
The output of the job can be retrieved with the following:
$ curl --request POST -H "additional_parameters: " "https://<ServerlessRestApi>.execute-api.eu-west-1.amazonaws.com/Prod/pclusterbatch?command=awsbout&cluster=cluster1&jobid=3d3e092d-ca12-4070-a53a-9a1ec5c98ca0"
The following command can be used to list the cluster’s hosts:
$ curl –request POST –H “additional_parameters: “ “https://<ServerlessRestApi>.execute-api.eu-west-1.amazonaws.com/Prod/pclusterbatch?command=awsbhosts&cluster=cluster1”
You can also use the API to submit MPI jobs to the AWS Batch cluster. The mpi_job_script.sh can be used for the following three nodes MPI job:
curl --request POST -H "additional_parameters: -n 3" --data-binary "$(base64 mpi_script.sh)" "https://<ServerlessRestApi>.execute-api.eu-west-1.amazonaws.com/Prod/pclusterbatch?command=awsbsub&cluster=cluster1"![]()
Retrieve the job output from the first node using the following:
$ curl --request POST -H "additional_parameters: " "https://<ServerlessRestApi>.execute-api.eu-west-1.amazonaws.com/Prod/pclusterbatch?command=awsbout&cluster=cluster1&jobid=085b8e31-21cc-4f8e-8ab5-bdc1aff960d9&compute_node=0"
Teardown
You can destroy the resources by deleting the CloudFormation stacks created during installation. Deleting a Stack on the AWS CloudFormation Console explains the required steps.
Conclusion
In this post, I show how to integrate the AWS Batch CLI by AWS ParallelCluster with API Gateway. I explain the lifecycle of the job submission with AWS Batch using this API. API Gateway and Lambda run a serverless implementation of the CLI. It facilitates programmatic integration with AWS ParallelCluster with your on-premises or AWS Cloud applications.
You can also use this approach to integrate with the previous APIs developed in the Using AWS ParallelCluster with a serverless API and Amazon API Gateway for HPC job submission posts. By combining these different APIs, it is possible to create event-driven workflows for HPC. You can create scriptable workflows to extend on-premises infrastructure. You can also improve the security of HPC clusters by avoiding the need to use IAM roles and security groups that must otherwise be granted to individual users.
To learn more, read more about how to use AWS ParallelCluster and AWS Batch.