Containers
Amazon ECS availability best practices
We spend a lot of time thinking about availability at AWS. It is critically important that our service remains available even during inevitable partial failures in order to allow our customers to gain insight and take remedial action. To achieve this, we rely on the availability afforded us by Regional independence and Availability Zones isolation. Concretely this means that the ECS control plane services (those services that deliver ECS management capabilities to our customers) do not take service dependencies outside of the Region in which we are operating to avoid multi-region impact. Additionally we ensure that we distribute our service evenly across at least three Availability Zones within the Region where ever possible. Not all services require this level of availability. Here we discuss best practice based on our experience for workloads running on ECS that do require this level of availability.
The reason we favor three Availability Zones is a cost, availability trade-off. Services that require high availability need some amount of redundancy. Services typically run at some optimal utilization in steady state, which includes head room to absorb burst and for highly available services this head room also needs to factor in absorbing failover load. The larger the blast radius of a failure in reducing available capacity the larger the head room required to absorb it. This lowers the steady state utilization on any one server because of the need for the additional headroom to handle the failure and by extension increasing cost. As an example, let’s assume a workload requires 60 hosts to service requests optimally. We would need 120 such hosts to ensure sufficient capacity in the event of Availability Zone failure if our service is running in two Availability Zones, a doubling of cost. However, if our service is running in three Availability Zones, we only need 90 hosts to achieve the same availability profile. We see continued cost reduction and increased utilization by adding more Availability Zones (where possible) but the return diminishes quickly and the cognitive overhead increases. For ECS internal services, we have settled on three Availability Zones, a number supported in most AWS Regions.
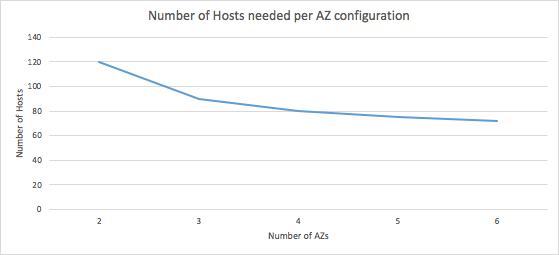
So what does all of this mean for your ECS configuration? When looking to provision capacity into your ECS Cluster, it is important to consider the availability requirements of your service. A three Availability Zone spread of EC2 instances in your Cluster delivers a good balance of availability and cost by reducing the steady state utilization to head room ratio while meeting the availability goal. The resultant lower capacity requirement may provide an opportunity to gaining saving by right sizing your EC2 instance type selection over a two Availability Zone spread. Another cost saving opportunity may be available through leveraging EC2’s burst capable platforms. Through right sizing your platform for steady state with some head room, you may be in a position to leverage the T3 platforms burst capabilities to absorb some portion of potential failover load thereby reducing the cost of the failover head room and only paying for it when needed. When supported by an EC2 Auto Scaling group, which will ensure that lost capacity is replaced this can be a very compelling cost saving mechanism while still meeting your availability goals. AWS recommends benchmarking your service, including failover scenarios to validate your selection.
Having provisioned your ECS Cluster with the appropriate spread of compute capacity it is important to ensure that ECS is going to honor this spread for Task placement in order to maintain availability. ECS and EC2 provides some useful tools to help leverage AWS availability constructs. It is important to understand how these tools work in order to ensure that you are best able to achieve your availability goals.
ECS tools for container availability
ECS Spread placement strategy
ECS groups available capacity used to place Tasks into ECS Clusters with ECS Tasks being launched into an ECS Cluster. An ECS Clusters configured to use EC2 will have EC2 Instances registered with it and each EC2 instance resides in a single Availability Zone. You should be ensuring that you have EC2 instances registered with your Cluster from multiple Availability Zones. You can read more about launching EC2 instances into ECS Clusters here.
ECS supports specifying a placement strategy in the ECS Service definition or as an argument in the RunTask request. The spread placement strategy asks ECS to spread the Tasks on a best efforts basis over some attribute of the underlying capacity. By specifying “availability-zone” as that spread attribute, ECS will spread the Tasks being launched as evenly as possible across the Availability Zones for the EC2 instances registered to the ECS Cluster. ECS Replica Service Scheduler use an Availability Zone spread strategy by default if no other placement strategy is provided. RunTask can be configured to use Availability Zone spread strategy by setting the type and field properties for placement strategy as follows in the RunTask request:
For spread placement over Availability Zone, ECS will work to spread the Tasks launched as evenly as possible across the Availability Zones for instances registered with the ECS Cluster. From an availability perspective, this is desirable. There are however some sharp edges to be aware of. ECS looks to spread the tasks for this service over the Availability Zones on a best efforts basis but this can be hampered depending on how the ECS Cluster is configured:
Unbalanced clusters
An unbalanced cluster occurs when EC2 instance capacity registered to the cluster is disproportionately spread across Availability Zones such that more capacity is available in some Availability Zones than others. This can result from some Availability Zones have more EC2 instances registered than others. ECS will always look to evenly spread Tasks using spread placement across all Availability Zones where capacity is registered. If your cluster does not have a balanced spread of EC2 instance capacity across Availability Zones this can result in higher density task placement on hosts in under provisioned Availability Zones. In the extreme case, this could mean all Tasks destined for that Availability Zone residing on a single host if that is the only host with capacity.
As an example lets assume a Cluster X has nine EC2 instances spread across Availability Zone 1, Availability Zone 2, and Availability Zone 3. However the cluster is unbalanced with Availability Zone 1 having two instances, Availability Zone 2 having one instance and Availability Zone 3 having five instances. Let’s now assume that we have an ECS Service configured to use this cluster with a desired Task count of nine tasks. ECS will spread the Tasks across the Availability Zones with the result that Availability Zone 1 will have three tasks spread across two instances, Availability Zone 2 will have three tasks all placed on a single instance and Availability Zone 3 will have three tasks spread across five instances.
This represents an availability risk from two perspectives. Firstly Tasks in Availability Zone 2 are both at risk from an Availability Zone failure but are also at risk from a single host failure. In effect, a single instance failure for our cluster in Availability Zone 2 is the same as a total Availability Zone failure. Furthermore, if Availability Zone 3 was to fail, the cluster looses an effective 50% of available capacity, more than our availability model intends. This introduces the potential risk of further failure due to unexpected increased load on the remaining service capacity.
Capacity constrained clusters
ECS spread placement is on a best efforts basis and ECS will favor placing the task over failing the launch. If your cluster is capacity constrained ECS will place were there is capacity available. In the extreme case, this can mean all Tasks for a Service placed in a single Availability Zone. Capacity constrained clusters can be the result of a number of factors. Using heterogeneous EC2 instance types in a cluster unless balanced across Availability Zones can result in disproportionate available resource in any one Availability Zone. Sharing a Cluster across multiple services with different availability constraints and placement criteria can also result in available capacity not being evenly distributed across Availability Zones. The result is an availability risk for the service and the potential for failure in one Availability Zone resulting in a disproportionate loss of healthy Tasks and the potential for a larger outage due to replacement capacity not being available when needed.
EC2 Auto scaling and Availability Zone balancing your cluster
EC2 provides an automated mechanism for balancing EC2 capacity across Availability Zones through EC2 Auto Scaling. EC2 Auto Scaling will automate ensuring that capacity is spread appropriately across Availability Zones. In addition, EC2 Auto Scaling will also look to replace capacity in the Cluster in the event of an Availability Zone failure in a healthy Availability Zone and upon recovery look to rebalance the capacity across all Availability Zones.
Leveraging EC2 Auto Scaling group for your ECS Cluster removes the burden of having to monitor and balance the Availability Zone spread in your ECS Cluster. You can read more about using EC2 Auto Scaling with ECS Clusters here.
ECS and Fargate
AWS Fargate is a compute engine for ECS that removes the need to configure, manage, and scale EC2 instances. Fargate ensures Availability Zone spread while removing the complexity of managing EC2 infrastructure and works to ensure that Tasks in a Replica Service are balanced across Availability Zones. For RunTask launches with a Fargate launch type Fargate will look to spread Task placement across all available Availability Zones ensuring even distribution of the Task Definition Family that the Task belongs to. By leveraging Fargate, you are able to sidestep the undifferentiated heavy lifting of owning and managing infrastructure allowing you to focus on delivering applications to delight your customers.
Recommendations and best practices
In order to mitigate the above scenarios, it is best to ensure the following:
- Favor configuring ECS Clusters with EC2 instance capacity resident in at least three Availability Zones.
- Favor configuring ECS Clusters with homogenous EC2 instance capacity types and keep the instance counts balanced across the Availability Zones.
- Favor single tenant ECS Clusters.
- When multi-tenant Clusters are needed ensuring that the availability requirements and placement strategies for shared tenant ECS Clusters align for all Services and Tasks being hosted in that Cluster. (i.e. make sure that all Tasks launched are using an Availability Zone spread strategy)
- Consider using EC2 Auto Scaling to manage EC2 capacity for your ECS Cluster
- Consider running your workload on Fargate
Conclusion
At AWS, we think about availability a great deal and work hard to provide customers with the tooling needed to make achieving availability as simple as possible. It is however important to understand the best practices on which these tools are based and the nuances of the tools in order to ensure the best possible availability for your service. There is a cost to scaling for availability and not all services have a zero down time requirement. For those that do following the recommendations above will help improve availability, reduce cost and avoid unexpected outcomes that can result from undesirable infrastructure configurations.