Containers
Kubernetes as a platform vs. Kubernetes as an API
Introduction
What is Kubernetes? I have been working on this technology since the beginning and after 8 years, I’m still having a problem defining what it is. Some people define Kubernetes as a container orchestrator but does that definition capture the essence of Kubernetes? I don’t think so. In this post, I’d like to explore thinking about Kubernetes outside of how we conventionally think about it and where the technology can stretch.
Amazon Elastic Kubernetes Service (Amazon EKS), an AWS managed service that operationalizes Kubernetes upstream clusters on behalf of customers, has a very large and broad user base. The way these customers use Amazon EKS and the way they think about Amazon EKS varies greatly. For some, Kubernetes is their new platform, for others it’s a facade to interface AWS services. It’s the story of the large spectrum that exists between being in full control, on one end, and embracing a fully managed service approach on the other far end.
Let’s explore this spectrum in more details. To do so we’ll use a simple application with a backend database and explore the various models you can use to deploy it on AWS using Kubernetes. Also, there is a recorded demo at the end of this post to land the concepts expressed back on the ground and demonstrate them practically.
Kubernetes is my control plane and data plane
In this model, customers opt to use only broadly available core infrastructure primitives (i.e., compute, storage, networks) and re-base every possible higher-level service onto the Kubernetes platform. These customers are either building this platform on their own stitching together Open Source Software (OSS) pieces or they are using a (more or less proprietarily) vendor software to implement it. Either way, they need a strong platform engineering team to deploy, maintain, and operate such platform. The following diagram captures the idea behind this model.
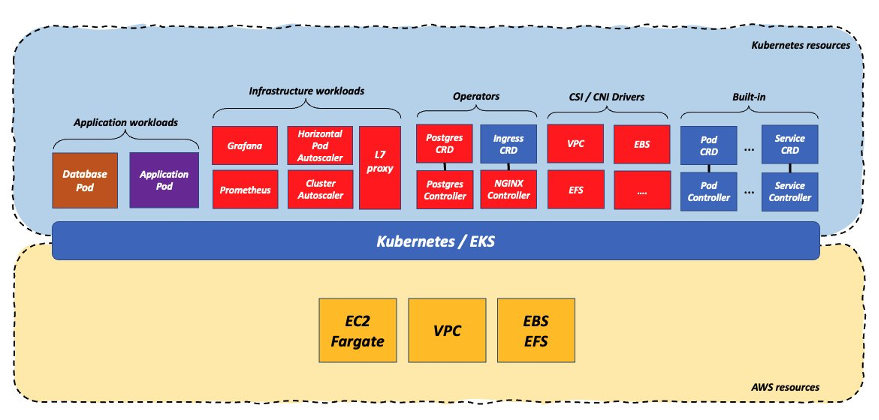
These customers are going to use:
- Container Network Interface (CNI) and Container Storage Interface (CSI) drivers to interface with the core infrastructure primitives
- The Kubernetes built-in objects (pods, deployments, etc.) to support the core primitives for applications and infrastructure components
- A control plane for custom objects built using the operators pattern (a mix of Kubernetes Custom Resource Definitions (CRDs) and Kubernetes controllers used to self-heal custom deployments of specific workloads, e.g. databases, load balancers, etc.)
Note: The example in the diagram is limited to a simple load balanced application that interacts with a database. An holistic approach of re-basing all workloads on top of Kubernetes and core infrastructure primitives can, potentially, become way more complex to manage than this. For example, this is what these components look like when you start deploying more sophisticated workloads on the cluster such as Kubeflow.
In this scenario the workload gravity is skewed towards the Kubernetes cluster which is, effectively, your workload data plane. The pros of this approach is that the customer is decoupling heavily from the infrastructure underneath thus enabling better portability of their entire platform. The cons of doing this is that the customer is signing up for a high amount of work. The amount of work is a function of the breadth and the richness that they want to offer as part of the platform they are building.
Kubernetes is (some of) my control plane and (some of) my data plane
The previous approach is a bit extreme. In fact, we see the majority of customers adopting an approach that’s more hands-off and that uses native cloud services. This allows the customer to offload some of the undifferentiated heavy lifting of running infrastructure to AWS and taking advantage of a more managed experience for some of these critical services (e.g., load balancers, databases, and possibly others such as queue services and more). This diagram tries to capture what these customers do:
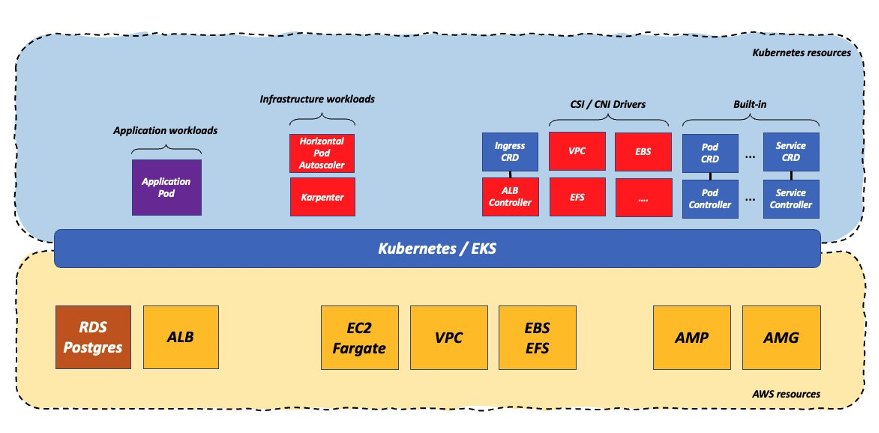
In this example, the customer has offloaded the Postgres database management to Amazon Relational Database Service (Amazon RDS) thus relieving the burden of owning the database infrastructure operations (previously implemented in the Postgres operator). They also have decided to use the AWS Application Load Balancer (ALB) which still requires to have a Kubernetes controller but it alleviates the need to own and maintain the L7 load balancer data plane running on the cluster. Some customers also opt to offload the Prometheus and Grafana implementations to managed services (in the case of AWS they would be Amazon Managed Service for Prometheus and Amazon Managed Grafana).
In this scenario the workload gravity is centered between the Kubernetes cluster and the native cloud services managed by AWS. For a lot of customers this is the sweet spot because they can still standardize on Kubernetes and open-source technologies while offloading part of the business undifferentiated operations to AWS.
Using open-source technologies that are broadly available (e.g., Postgres) offers customers a good degree of flexibility. However, a set of customers prefer to take full advantage of a serverless operational model and tend to prefer native cloud services such as DynamoDB, Amazon EventBridge, AWS Step Functions, Amazon SQS, and more.
Kubernetes is my control plane and (some of) my data plane
In the model above, the way customers manage in-cluster workloads (plain K8s YAML, helm charts, GitOps, and so forth) is different from how they manage resources in AWS (AWS CloudFormation, Terraform, AWS Cloud Development Kit [Amazon CDK], Pulumi, and so forth). In the previous and very simple example, they deploy the Amazon RDS database using a traditional Infrastructure as Code (IaC) tool that supports AWS resources while they would need to deploy the application running on Kubernetes using one of the supported Kubernetes mechanisms. Wouldn’t it be nice if they could do everything using one deployment mechanism and specifically a Kubernetes mechanism? That’s exactly what the AWS Controllers for Kubernetes (ACK) allow customers to do.
Quoting from the ACK web site: “AWS Controllers for Kubernetes (ACK) lets you define and use AWS service resources directly from Kubernetes. With ACK, you can take advantage of AWS-managed services for your Kubernetes applications without needing to define resources outside of the cluster or run services that provide supporting capabilities like databases or message queues within the cluster”.
To do so, you need to deploy on the cluster one or more controllers, depending on which services you want to control from within the Kubernetes platform. In our case we only need the Amazon RDS controller:
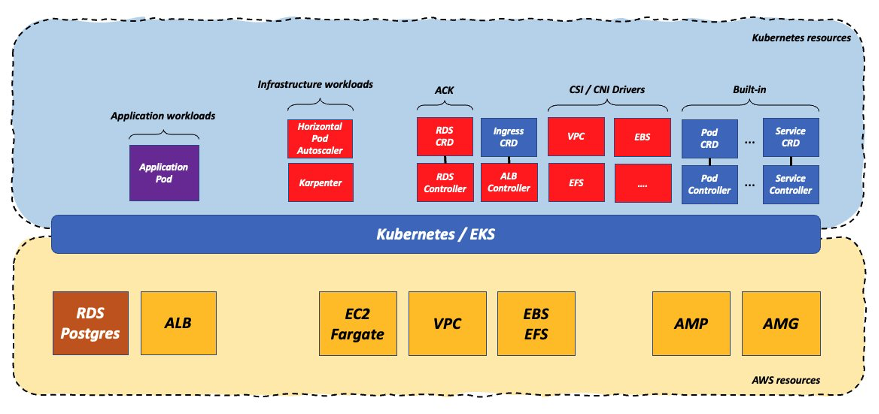
In this scenario, the workload gravity hasn’t changed vastly (it’s still centered between the Kubernetes cluster and the native AWS services) but there is one single API, the Kubernetes API, to control this heterogeneous deployment.
Note that owning the Amazon RDS ACK controller instead of a Postgres operator allows customers to simplify the complexity on a couple of dimensions. The first one is that, with Amazon RDS, you don’t own the data plane (i.e., the actual pods running the database code) and everything that’s associated to that in terms of scalability, security, performance optimizations, reliability, etc. The second is that the ACK controller is typically very lean and it only implements CRUD logic for a service (Create, Read, Update, Delete). The ACK controller offload to the managed service all the atomic operations associated to running a specific service. On the contrary, the Postgres operator (or any other such operator) is responsible for all the operations associated to a database (backups, recoveries, scaling, etc.). The long story short is that there is a lot less work (and maintenance) involved for a customer when running an ACK controller that leverages a fully managed AWS Service than there is when customers need to manage an operator for running a similar service in-cluster.
But is this enough if all I care is about reducing complexity and undifferentiated heavy lifting? While customers have offloaded a lot of the complexity to the AWS managed layer, the fact that they are running the application on the Kubernetes cluster means that there is a lot of requirements and dependencies that need to be satisfied and maintained. Managing this stack is still a non-trivial amount of work. Let’s see some of these requirements and dependencies:
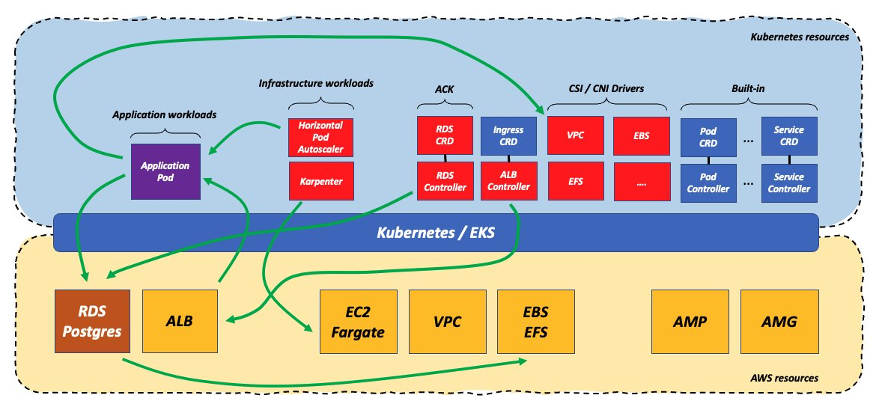
First and foremost, since customers are running their application on the Kubernetes cluster, they need to take care of its scalability (presumably via the Horizontal Pod Autoscaler). Similarly, if they use Amazon Elastic Compute Cloud (Amazon EC2), they need to have something like Cluster Auto Scaler or Karpenter to scale that infrastructure. Because they need to wire the ALB to pod(s) running on Kubernetes, they still need to have and maintain the ALB controller on the cluster. Now that they moved the database below the line the CSI drivers are less critical but they are still running application pod(s) that may require some advanced networking capabilities, so the CNI plug-ins still play an important role in the in-cluster stack. Some customers may need to run additional operators such as, the External Secrets Operator to interface with AWS Secrets Manager, which is not shown in the previous diagram. Last, but not least, for technical reasons some components like CoreDNS must be run in the data plane alongside application pods thus adding more infrastructure software workloads to maintain in-cluster.
Note that there is a common misconception that these problems can be solved by the cloud provider taking full ownership of all these components running in the cluster. While in theory this may be sound, in practice Kubernetes clusters will continue to run customer managed software (either applications workloads or infrastructure workloads) that create a large set of cross-version dependencies. In other words, the problem is not so much who manages these components but rather how to find (and maintain) working software versions across a shared responsibility model (between the provider and the customer). For example, the fact that a cloud provider owns the upgrades of a cluster, doesn’t change the fact that customers need to make sure the components they run are compatible with the Kubernetes version that is running at any point in time. This problem obviously escalates and is exacerbated when working with big multi-tenant clusters due to the larger and more intricate dependencies.
Kubernetes is my control plane but not my data plane
If customers are on a path to simplify the workloads and configurations running on the cluster, why offloading everything and stop at the application? Can they move everything, including the application, below the line and still maintain the Kubernetes API as their infrastructure standard interface?
Someone defines Kubernetes as “a well-designed and extensible API with programmable reconciliation logic, that happens to come with a container orchestrator built in.” I like that definition. What if customers could offload even the containerized application into a more managed and versionless environment that doesn’t need constant upgrades and software versions curation? In other words, if Kubernetes is a generic control plane with containers batteries included, can these batteries be removed and replaced with other type of containers batteries?
This is how that world would look like with a hypothetical Amazon ECS ACK controller:
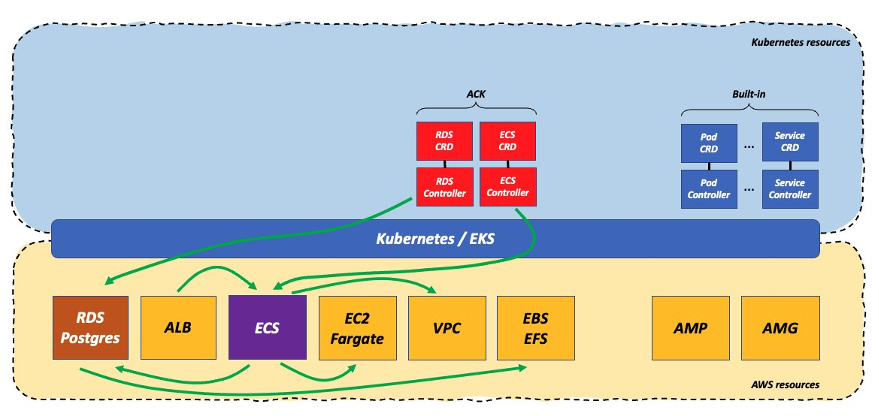
In this scenario the workload gravity has fallen squarely under the Kubernetes line into the managed AWS native services which act as the data plane for the Kubernetes control plane.
Note how all of the logical interactions between the application and the other infrastructure functions and capabilities haven’t changed drastically. What changed is who manages those interactions. In this hypothetical context all those interactions happen below the Kubernetes line and most of the burden of their integration is on AWS. Again, the most important part of this scenario isn’t so much who manages this integration but the fact that this integration is fully versionless and it just works. There are no drivers and there are no versions whatsoever that need to be taken into account. A good practical example of this theory is the difference, in undifferentiated heavy-lifting effort, between running Istio on top of the Kubernetes cluster vs. consuming Amazon ECS Service Connect out of the box.
In a scenario like this, customers end up having a lot less version dependencies on the software running on the cluster (because there is simply less software running on Kubernetes). It’s true that customers have to manage ACK controllers running on the cluster but the controllers requirements are way less sensitive to cluster versions and the dependencies are less coupled. And this makes the maintenance of the Kubernetes cluster itself, especially its upgrades, dramatically easier, faster and less risky to execute.
Yes, software-based integrations provide an incredible level of flexibility. In fact, EKS, through CSI and CNI drivers, supports more integration than what ECS does across the same core infrastructure building blocks. However, if you don’t need that extreme flexibility, software-based integrations, regardless of who manages them, can become an inhibitor for the business rather than an enabler.
Why would I ever want to do this?
There are a couple of trajectories that would allow customers to intercept a solution like this.
Customers could consider this model if they are coming from a Kubernetes background, they love Kubernetes but they are starting to realize that the flexibility gained for the additional work they are pouring into it is starting to trend net negative. This model would allow them to maintain the interface they love and that they invested into (or perhaps they hired for) while offloading more and more to AWS to manage. In a world that is fast moving from “I can run my scripts everywhere” to “I can apply my skills everywhere” this solution may create a good balance between maintaining a Kubernetes centric view of the world while being able to mitigate the operational burden. The fact that Amazon ECS is version-less and serverless, mitigates some of the dependencies that are associated to Kubernetes clusters upgrades. Another tactical reason why this solution may be appealing to committed Kubernetes customers is for the need to access AWS Fargate features that are available for the Amazon ECS orchestrator but are not (yet) available for Amazon EKS. Example of these features include Graviton support, Spot support, and Windows support to name a few.
Note also that this approach is nothing new. For example, there is already an ACK controller for Lambda that would allow you to do similar things. What’s peculiar about an ACK ECS controller is that, because the programming model and the packaging of EKS containers and ECS containers are identical, the transition from running workloads on the Kubernetes data plane to running the same workloads on the ECS data plane is potentially easier and more transparent (and it only involves changing the YAML syntax of how you describe ECS tasks and services Vs. how you describe Kubernetes pods and deployments).
All in all, customers coming from this path would essentially see the Amazon ECS ACK controller as “just yet another CRD in my arsenal”.
The second trajectory for considering this model assumes customers are coming from an Amazon ECS background, they are all in into Amazon ECS and AWS but they are finding, tactically or strategically, of benefit to adopt a Kubernetes interface. This could be because there is a company-wide mandate to adopt Kubernetes in their organization but they don’t want to let go the benefits of a fully managed AWS experience. This could also be because they want to adopt some of the practices and tooling available in the Kubernetes ecosystem that could apply nicely to their Amazon ECS operations (e.g., GitOps or Helm packaging support). Customers coming from this path would essentially see the Amazon ECS ACK controller as “this is a new deployment tool for ECS workloads”.
The following diagram depicts what it would be potentially possible to achieve using this hypothetical solution:

Conclusion
In this post, we showed you the flexibility of Kubernetes. It’s arguably an extreme option and one that doesn’t even exist today (the Amazon ECS ACK controller isn’t available but please thumb up this roadmap proposal if you are intrigued). If anything, it proves that Kubernetes can be a lot of things to a lot of different people and defining it remains a work in progress (at least in my head).
This blog is also aimed at hinting that, sometimes, the traditional “Amazon EKS Vs Amazon ECS” discussion can be misleading. What Kubernetes really is, in the end, is either a re-base or a proxy of the entire set of cloud services, depending on the approach customers use and that we have tried to outline in this blog post.
The fact that many users today use a hybrid approach, where they run some applications in the cluster and many other infrastructure components in the native cloud, is almost incidental. The Kubernetes posture that customers implement is a function of many variables and there is no right or wrong doing. At the end of the day, it’s a tradeoff and the “workload gravity” will vary greatly depending on their very specific situation. For example, I do not expect widespread adoption from Kubernetes centric customers of the last scenario presented but it may appeal, for example, large organizations with multiple independent teams making autonomous products decisions. Some of these teams may prefer to use services that embrace a full serverless and versionless operational model while adhering to the “Kubernetes” standard advocated (or mandated) by a centralized platform team.
If you are curious about how this would look like in real life, here is a short demo of some of the concepts we have alluded to in the “Kubernetes is my control plane but not my data plane” section above. For this video we have used a working ECS ACK controller prototype (thanks Amine!). The code of this controller is not available publicly at the time of this writing because it only implements a subset of the potential full functionalities for demonstration purposes.