AWS Database Blog
Amazon Aurora as an Alternative to Oracle RAC
Written by David Yahalom, CTO and co-founder of NAYA Tech—a leading database, big data, and cloud professional and consulting service provider, located in San Jose, CA. David is a certified Oracle, Apache Hadoop, and NoSQL database expert and a cloud solutions architect.
Oracle Real Application Clusters (Oracle RAC) is considered to be one of the most advanced and capable technologies for enabling a highly available and scalable relational database. It is considered the default go-to standard for creating highly available and scalable Oracle databases.
However, with the ever increasing adoption of cloud, open-source, and platform-as-a-service (PaaS) database architectures, many organizations are searching for their next-generation relational database engine. They’re looking for one that can provide similar levels of high availability and scalability to Oracle RAC, but in a Cloud/PaaS model, while maintaining the freedom of open source software.
In this post, I discuss how Amazon Aurora can serve as a powerful and flexible alternative to Oracle RAC for certain applications. Both Oracle RAC and Amazon Aurora are designed to provide increased high availability and performance scalability for your databases. But they approach these goals from very different directions using different architectures:
- Oracle RAC uses an intricate end-to-end software stack developed by Oracle—including Oracle Clusterware and Grid Infrastructure, Oracle Automatic Storage Management (ASM), Oracle Net Listener, and the Oracle Database itself—combined with enterprise-grade storage that enables a shared-everything database cluster technology.
- Amazon Aurora simplifies the database technology stack by using AWS ecosystem components to transparently enable higher availability and performance for MySQL and PostgreSQL databases.
So let’s dive right in!
Preface
I’ll start this blog post with a quick disclaimer. I’m what you would call a “born and raised” Oracle DBA. My first job, 15 years ago, had me responsible for administration and developing code on production Oracle 8 databases. Since then, I’ve had the opportunity to work as a database architect and administrator with all Oracle versions up to and including Oracle 12.2. Throughout my career, I’ve delivered a lot of successful projects using Oracle as the relational database component.
As such, I love the capabilities, features, technology, and power of Oracle Database. There’s really no denying that Oracle is still one of the most (if not the most) powerful and advanced relational databases in the world. Its place in the pantheon of database kings is undoubtedly safe.
Also, please keep in mind that the Amazon Aurora and RAC architectures vary greatly and the intention of this article is not to compare the internals of Amazon Aurora vs. Oracle RAC. Instead, my goal is to look an Amazon Aurora and Oracle RAC from a functional perspective. Put forth some of the mainstream RAC use-cases and see if they can be handled by Amazon Aurora and, at the same time, leverage the inherit benefits of AWS.
The paradigm shift
With that introduction out of the way, let’s talk about how the database industry is changing and why many customers choose to think outside the box and adopt cloud-based solutions as alternatives for commercial databases. Even applications that require the highest levels of performance and availability or those that run on high-end commercial databases can potentially now be powered by MySQL and PostgreSQL databases—albeit with some Amazon “special sauce” on top. But more on that later.
There’s a fundamental shift happening in the database landscape as customers transition their data architectures from being monolithic—where a single, big, and feature-full, relational database powers their entire solution stack—to a more services-oriented model. The commercial database isn’t going anywhere, but, in the new model, different database technologies power different parts of the solution. This “best-of-breed” approach makes perfect sense as emerging database technologies become more mature, robust, and feature-rich.
In addition, there’s a huge upward trend in the adoption of cloud services. Even the most traditional organization can see the benefits of tapping into the power that cloud-centric architectures can provide in performance, flexibility, high availability, and reduced total cost of ownership (TCO).
When you combine that with the huge and rapidly increasing adoption of open source–based relational databases, you can clearly see that the database industry is moving in a different trajectory from the classic “one commercial database to rule them all” approach that was once common.
Now, let’s dig deeper…
Oracle RAC architecture
My first step is to flesh out the major benefits that Oracle Real Application Clusters (Oracle RAC) provides to its customers. Since this is just a blog post and not a full-blown research paper, I can’t cover every single aspect and benefit of Oracle RAC so I’m intentionally keeping the discussion at a relatively high level so it can be approachable for a wide audience and not exclusively Database Administrators.
Oracle RAC is one of the major differentiating features for an Oracle database when compared to other relational database technologies. Oracle RAC is the technology that allows an Oracle database to provide increased levels of high availability and big performance benefits.
Oracle RAC is an Active/Active database cluster, where multiple Oracle database servers (running Oracle Database instances, which is a collection of in-memory processes and caches) access a shared storage device that contains a single set of disk-persistent database files. This architecture is considerably different from what you usually find in a non-Oracle database cluster. Instead of each database node having its own dedicated storage, all the database nodes coordinate and share access to the same physical disks.
All the database nodes coordinate with one another using both a dedicated network-based communication channel (known as the cluster interconnect) and a set of disk-based files.
Public access to the cluster (from incoming applications, SQL queries, users, etc.) is performed using a set of SCAN IPs that are used to load-balance incoming sessions. In addition, each RAC cluster node has its own physical and virtual IP addresses that can be used to open a connection directly to a specific node.
Greatly simplified Oracle RAC architecture
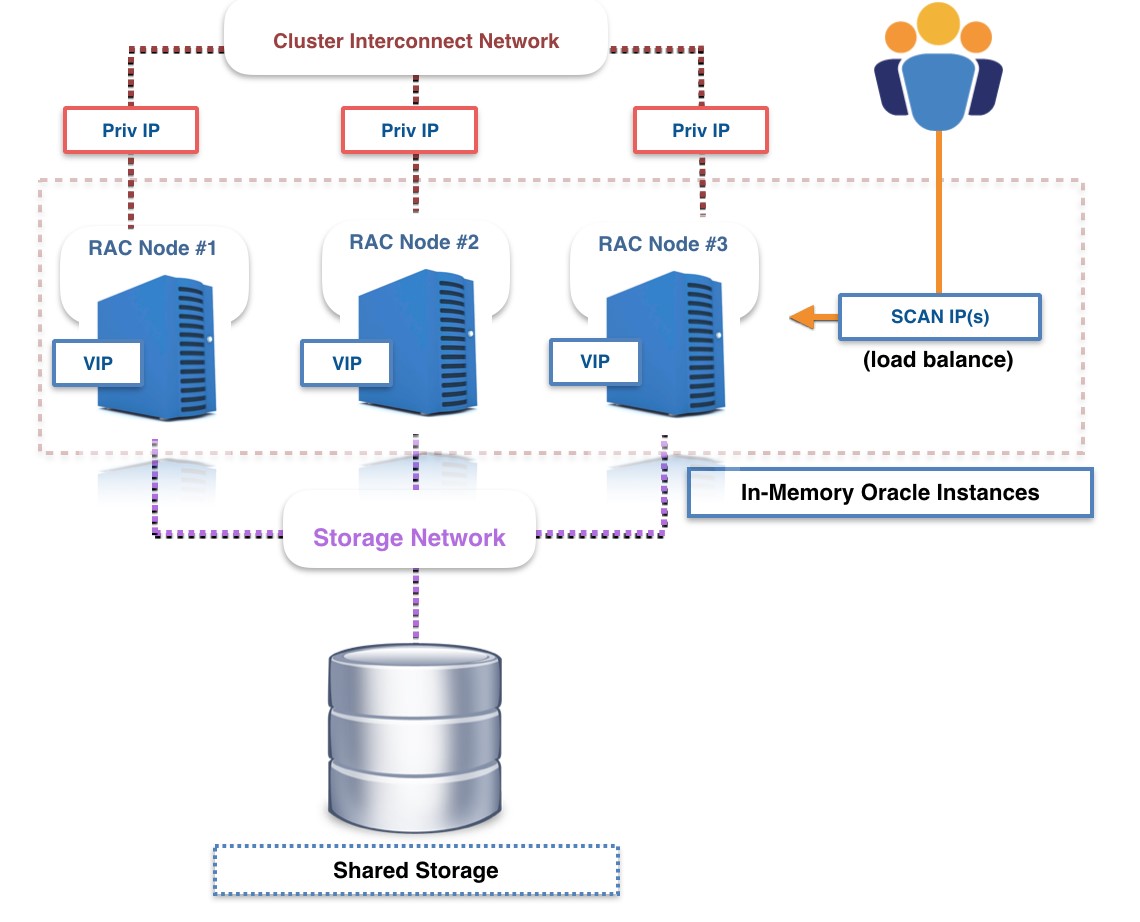
Because of the shared nature of the RAC cluster architecture—specifically, having all nodes write to a single set of database data files on disk—the following two special coordination mechanisms were implemented to ensure that the Oracle database objects and data maintain ACID compliance:
- GCS (Global Cache Services) tracks the location and the status of the database data blocks and helps guarantee data integrity for global access across all cluster nodes.
- GES (Global Enqueue Services) performs concurrency control across all cluster nodes, including cache locks and the transactions.
These services, which run as background processes on each cluster node, are essential to serialize access to shared data structures in the Oracle database.
Shared storage is another essential component in the Oracle RAC architectures. All cluster nodes read and write data to the same physical database files stored in a disk that is accessible by all nodes. Most customers rely on high-end storage hardware to provide the shared storage capabilities required for RAC.
In addition, Oracle provides its own software-based storage/disk management mechanism called Automatic Storage Management, or ASM. ASM is implemented as a set of special background processes that run on all cluster nodes and allow for easier management of the database storage layer.
So, to recap, the main components of an Oracle RAC architecture include the following:
- Cluster nodes: Set of one or more servers running Oracle instances, each with a collection of in-memory processes and caches.
- Interconnect network: Cluster nodes communicate with one another using a dedicated “interconnect” network.
- Shared storage: All cluster nodes access the same physical disks and coordinate access to a single set of database data files that contain user data. Usually handled by a combination of enterprise-grade storage with Oracle’s ASM software layer.
- SCAN (Single Client Access Name): “Floating” virtual hostname/IPs providing load-balancing capabilities across cluster nodes. Naming resolution of SCAN to IP can be done via DNS or GNS (Grid Naming Service).
- Virtual IPs (and Physical IPs): Each cluster node has its own dedicated IP address.
Performance and scale-out in Oracle RAC
With Oracle RAC, you can add new nodes to an existing RAC cluster without downtime. Adding more nodes to the RAC cluster increases the level of high availability that’s provided and also enhances performance.
Although you can scale read performance easily by adding more cluster nodes, scaling write performance is a more complex subject. Technically, Oracle RAC can scale writes and reads together when adding new nodes to the cluster, but attempts from multiple sessions to modify rows that reside in the same physical Oracle block (the lowest level of logical I/O performed by the database) can cause write overhead for the requested block and affect write performance. This is well known phenomena and why RAC-Aware applications are a real thing in the real world. Concurrency is also one of the reasons and why RAC implements a “smart mastering” mechanism which attempts to reduce write-concurrency overhead. The “smart mastering” mechanism enables the database to determine which service causes which rows to be read into the buffer cache and master the data blocks only on those nodes where the service is active. Scaling writes in RAC isn’t as straightforward as scaling reads.
With the limitations for pure write scale-out, many Oracle RAC customers choose to split their RAC clusters into multiple “services,” which are logical groupings of nodes in the same RAC cluster. By using services, you can use Oracle RAC to perform direct writes to specific cluster nodes. This is usually done in one of two ways (as shown in the diagram that follows):
- Splitting writes from different individual “modules” in the application (that is, groups of independent tables) to different nodes in the cluster. This is also known as “application partitioning” (not to be confused with database table partitions).
- In extremely un-optimized workloads with high concurrency, directing all writes to a single RAC node and load-balancing only the reads.
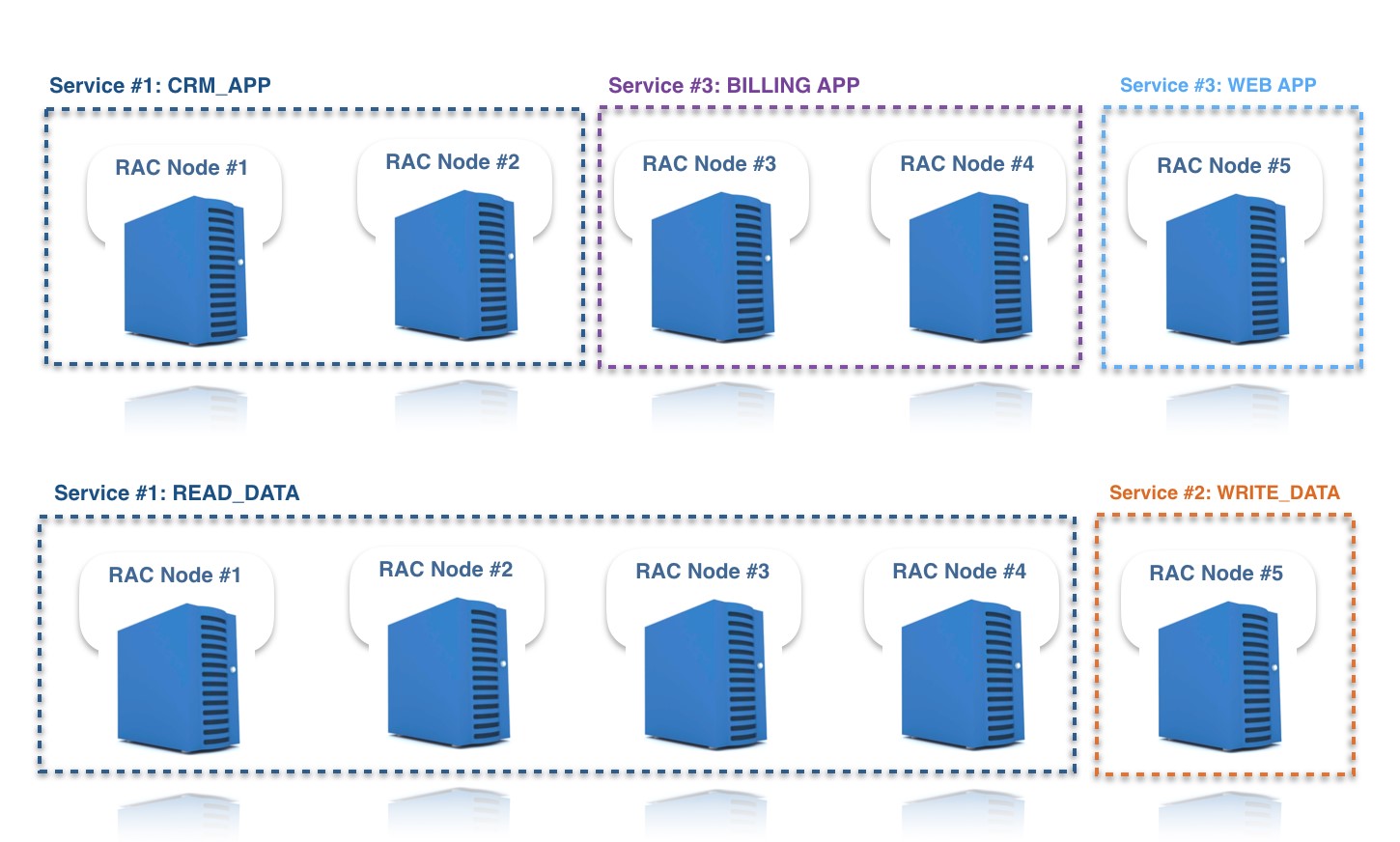
Major benefits of Oracle RAC
To recap, Oracle Real Application Clusters provides two major benefits that drive customer adoption:
- Multiple database nodes within a single RAC cluster provide increased high availability. No single point of failure exists from the database servers themselves. However, the shared storage requires storage-based high availability or DR solutions.
- Multiple cluster database nodes allow for scaling-out query performance across multiple servers.
Amazon Aurora architecture
Aurora is Amazon’s flagship cloud database solution. When creating Amazon Aurora cluster databases, you can choose between MySQL and PostgreSQL compatibility.
Aurora extends the “vanilla” versions of MySQL and PostgreSQL in two major ways:
- Adding enhancements to the MySQL/PostgreSQL database kernel itself to improve performance (concurrency, locking, multithreading, etc.)
- Using the capabilities of the AWS ecosystem for greater high availability, disaster recovery, and backup/recovery functionality.
Aurora adds these enhancements without affecting the database optimizer and SQL parser. This means that these changes are completely transparent to the application. If you provision an Aurora cluster with MySQL compatibility, as the name suggests, any MySQL-compatible application can function.
When comparing the Amazon Aurora architecture to Oracle RAC, you can see major differences in how Amazon chooses to provide scalability and increased high availability in Aurora. These differences are due mainly to the existing capabilities of MySQL/PostgreSQL and the strengths that the AWS backend can provide in terms of networking and storage.
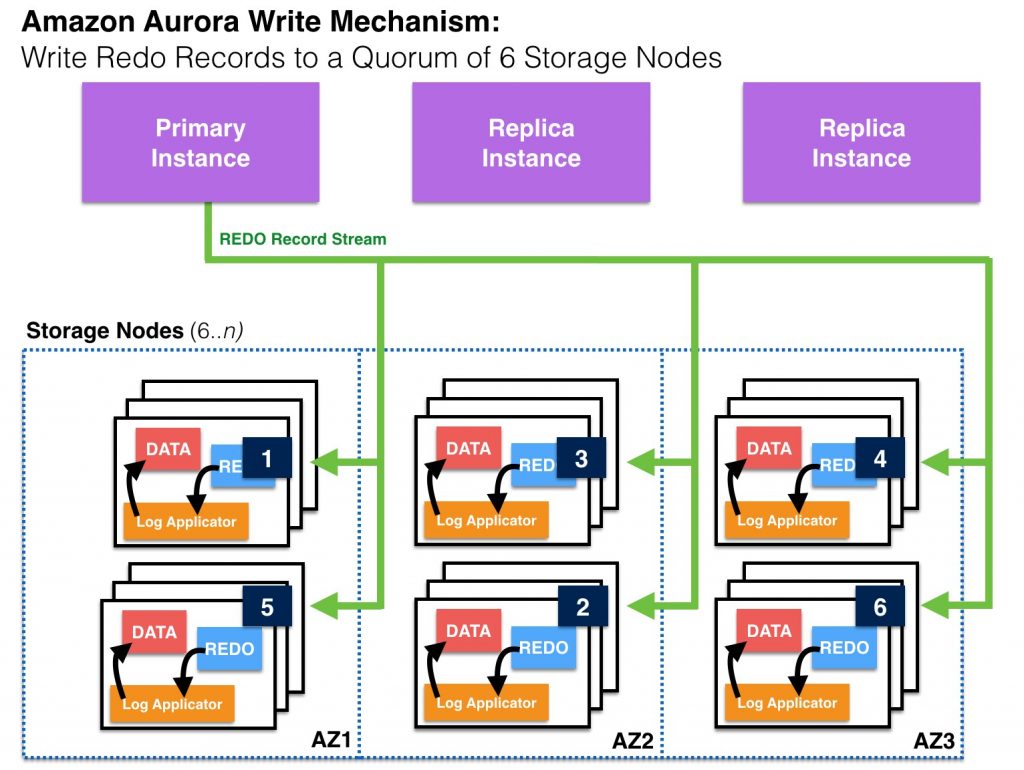
Instead of having multiple read/write cluster nodes access a shared disk, an Aurora cluster has a single primary node (“master”) that is open for reads and writes and a set of replica nodes that are open for reads with automatic promotion to primary (“master”) in case of failures. Whereas Oracle RAC uses a set of background processes to coordinate writes across all cluster nodes, the Amazon Aurora Master writes a constant redo stream to six storage nodes, distributed across three Availability Zones in an AWS Region. The only writes that cross the network are redo log records, not pages.
Let’s go deeper…
Each Aurora cluster can have one or more instances which serve different purposes:
- At any given time, a single instance functions as the primary (“master”) that handles both writes and reads from your applications.
- In addition to the primary (“master”), up to 15 read replicas can be created, which are used for two purposes:
- For performance and read scalability: as read-only nodes for queries/report-type workloads.
- For high availability: as failover nodes in case the master fails. Each read replica can be located in one of the three Availability Zones that hosts your Aurora cluster. A single Availability Zone can host more than one read replica.
The following is a high-level Aurora architecture diagram showing four cluster nodes: one primary (“master”) and three read replicas. The primary node is located in Availability Zone A, the first read replica in Availability Zone B, and the second and third read replicas in Availability Zone C.
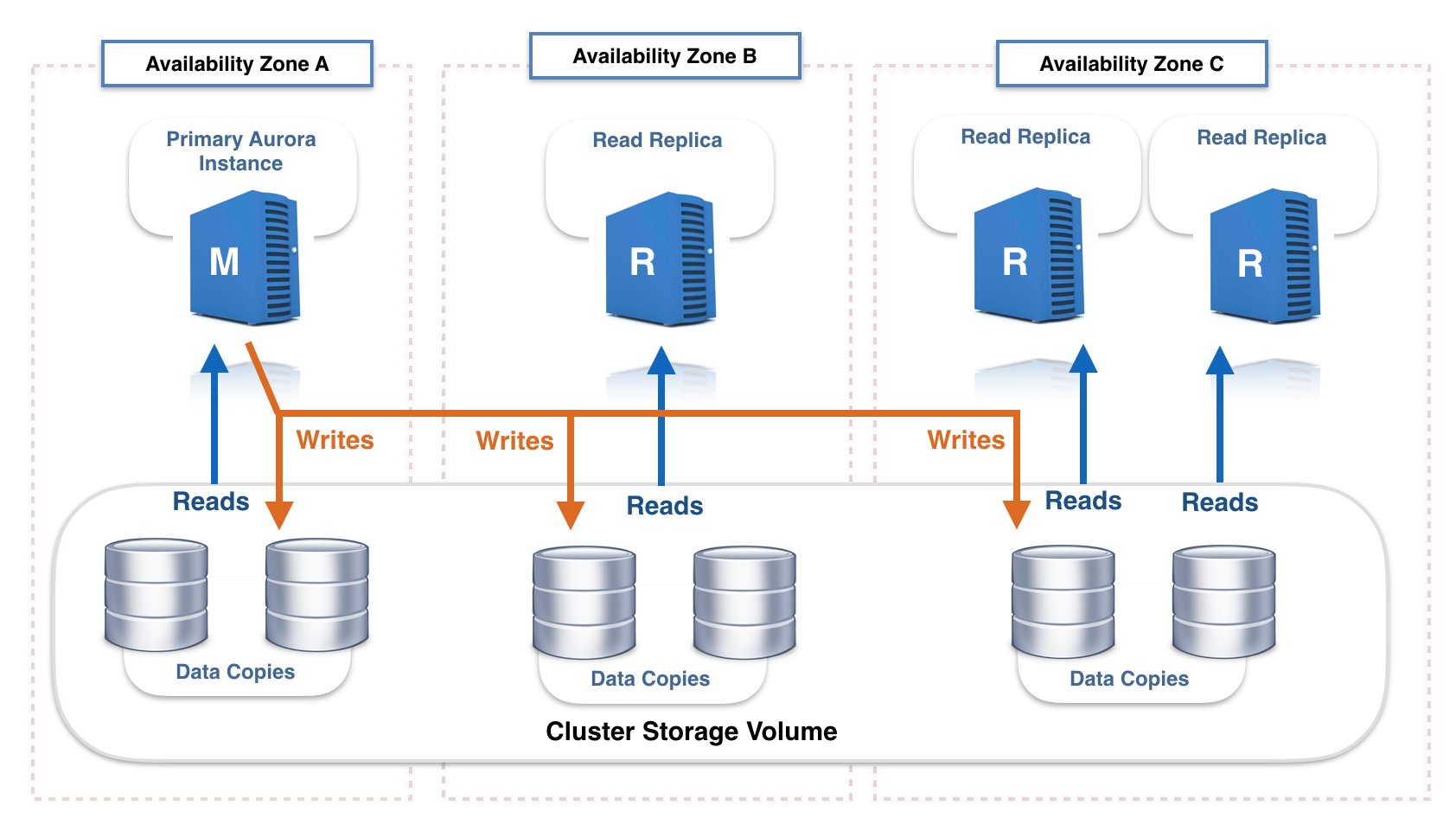
An Aurora Storage volume is made up of 10 GB segments of data with six copies spread across three AZs. Each Amazon Aurora read replica shares the same underlying volume as the master instance. Updates made by the master are visible to all read replicas through a combination of reading from the shared Aurora storage volume, and applying log updates in-memory when received from the primary instance After a master failure, promotion of a read replica to master is usually less than 30 seconds with no data loss.
Drilling down, for a write to be considered durable in Aurora, the primary instance (“master”) sends a redo stream to six storage nodes, two in each availability zone for the storage volume, and waits until four of the six nodes have responded. No database pages are ever written from the database tier to the storage tier. The Aurora Storage volume asynchronously applies redo records to generate database pages in the background or on demand. Remember that Aurora hides the underlying complexity from the user.
Amazon Aurora cluster with 1 X Primary, 2 X Replicas (and shared distributed storage).
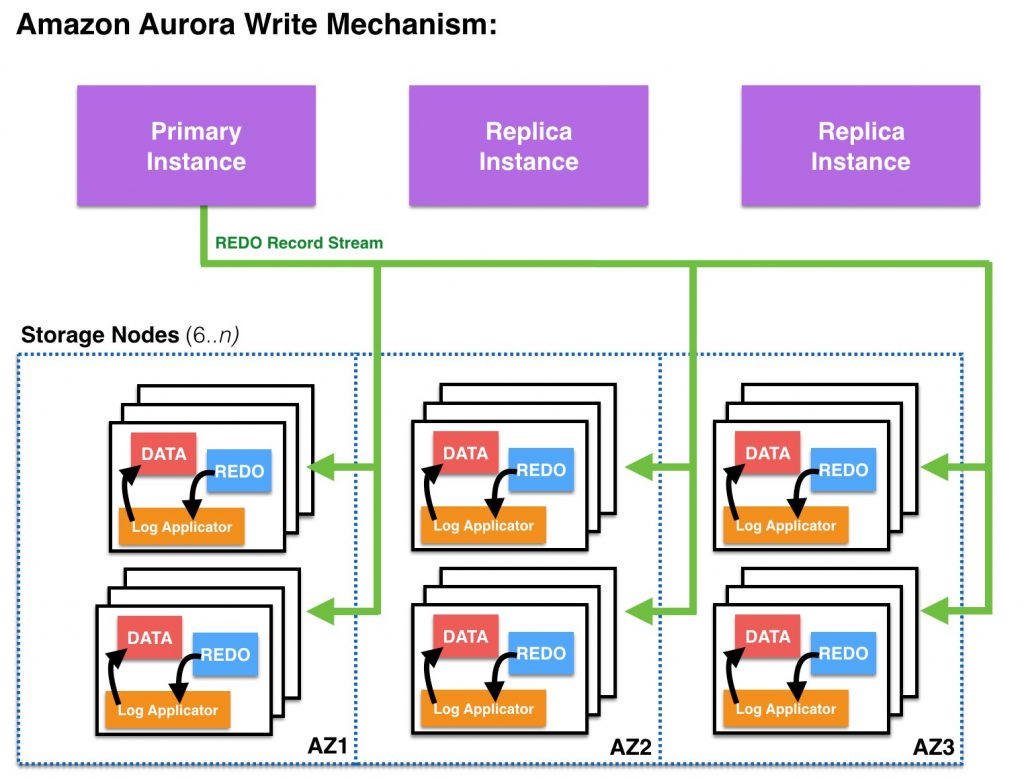
Primary writes REDO records to a quorum of 6 storage nodes spread across three AZs.
After 4 out of 6 storage nodes in the quorum confirm write, the ACK is sent back to the client.
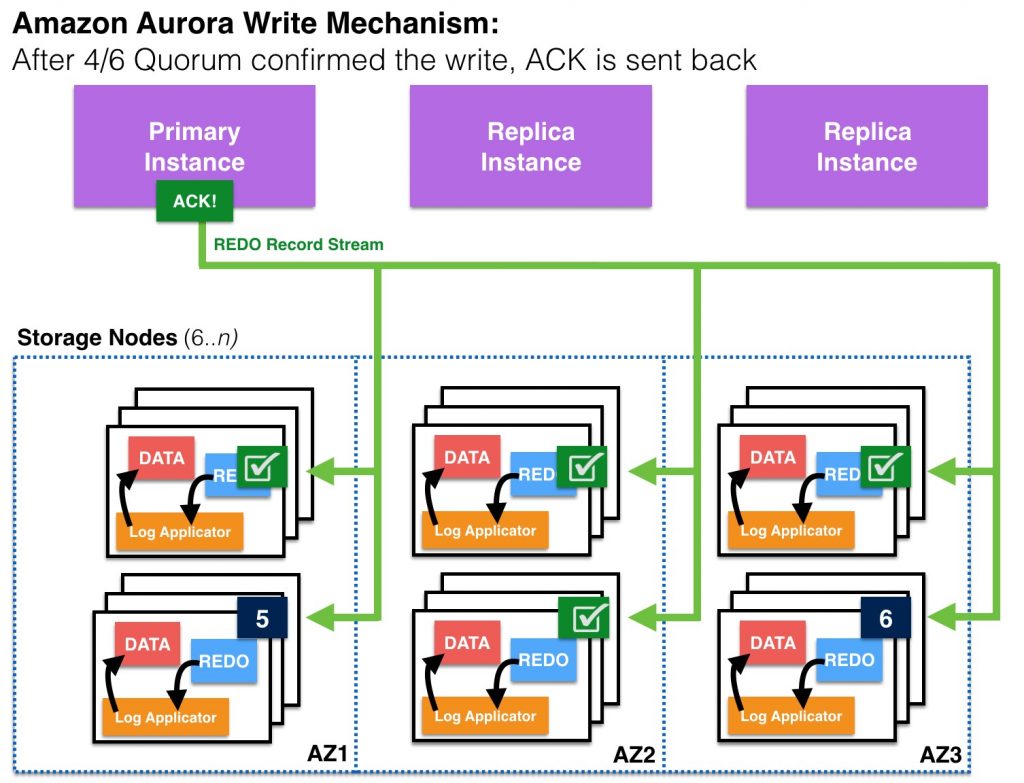
Writes to 6 out of 6 quorum continues in the background.

In parallel, REDO vectors are sent over the network from the Primary to the Replicas to be applied in-memory.
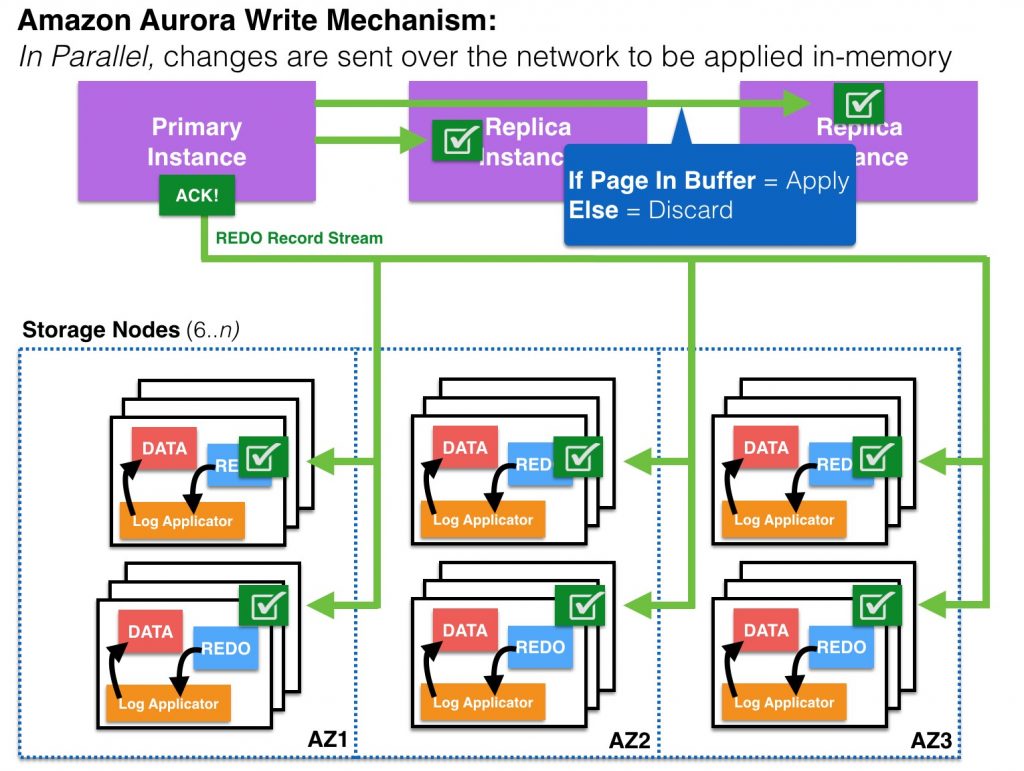
High availability and scale-out in Aurora
Aurora provides two endpoints for cluster access. These endpoints provide both high availability capabilities and scale-out read processing for connecting applications
- Cluster Endpoint: Connects you to the current primary instance for the Aurora cluster. You can perform both read and write operations using the cluster endpoint. Writes will always be directed to the “primary” instance when applications use the Cluster Endpoint. If the current primary instance fails, Aurora automatically fails over to a new primary instance. During a failover, the DB cluster continues to serve connection requests to the cluster endpoint from the new primary instance, with minimal interruption of service.
- Reader Endpoint: Provides load-balancing capabilities (round-robin) across the replicas allowing applications to scale-out reads across the Aurora cluster . Using the Reader Endpoint provides better use of the resources available in the cluster. The reader endpoint also enhances high availability. If an AWS Availability Zone fails, the application’s use of the reader endpoint continues to send read traffic to the other replicas with minimal disruption.

While Amazon Aurora focuses on the scale-out of reads and Oracle RAC can scale-out both reads and writes, most OLTP applications are usually not limited by write scalability; From my own experience, many Oracle RAC customers use RAC firstly for high availability and to scale-out their reads. You can write to any node in an Oracle RAC cluster, but this capability is often a functional benefit for the application versus a method for achieving unlimited scalability for writes.
Scaling reads is usually more important for the following reasons:
- Most RDBMS-centric applications are generally more read-heavy. A mix of 70 percent reads/30 percent writes is normal for most applications (for reference, the TPC-E benchmark has a 7:1 I/O read to write ratio).
- Scaling read performance is especially crucial when combining OLTP workloads (transactional) with analytical-type workloads, such as executing reports on operational data.
- Even with Oracle RAC, which can scale-out writes to some extent, because of concurrency issues that can occur when multiple sessions try to modify rows in the same database block(s), many customers choose to partition the read/write workload to specific nodes in their RAC cluster creating “RAC-Aware applications”.
Can Amazon Aurora Be Your Next Data Platform?
To summarize, Amazon Aurora provides the following benefits as a database platform:
- Multiple cluster database nodes provide increased high availability. There is no single point of failure from the database servers. In addition, since an Aurora cluster is always distributed across three availability zones, there is a huge benefit for high availability and durability of the database. These types of “stretch” database clusters are usually uncommon with other database architectures.
- AWS managed storage nodes also provide high availability for the storage tier. A zero-data loss architecture is employed in case a master node fails and a replica node is promoted to the new master. This failover can usually be done in under 30 seconds.
- Multiple cluster database nodes allow for scaling-out query read performance across multiple servers.
- Greatly reduced operational overhead using a cloud solution and reduced TCO by using AWS and open source database engines.
- Automatic management of storage. No need to pre-provision storage for a database. Storage is automatically added as needed, and you only pay for one copy of your data.
- With Amazon Aurora you can easily scale-out your reads (and scale-up your writes) which fits perfectly into the workload characteristics of many, if not most, OLTP applications. Remember that scaling out reads usually provides the most tangible performance benefit.
When comparing Oracle RAC and Amazon Aurora side by side, you can see the architectural differences between the two database technologies. Both provide high availability and scalability but approach it with different architectures.
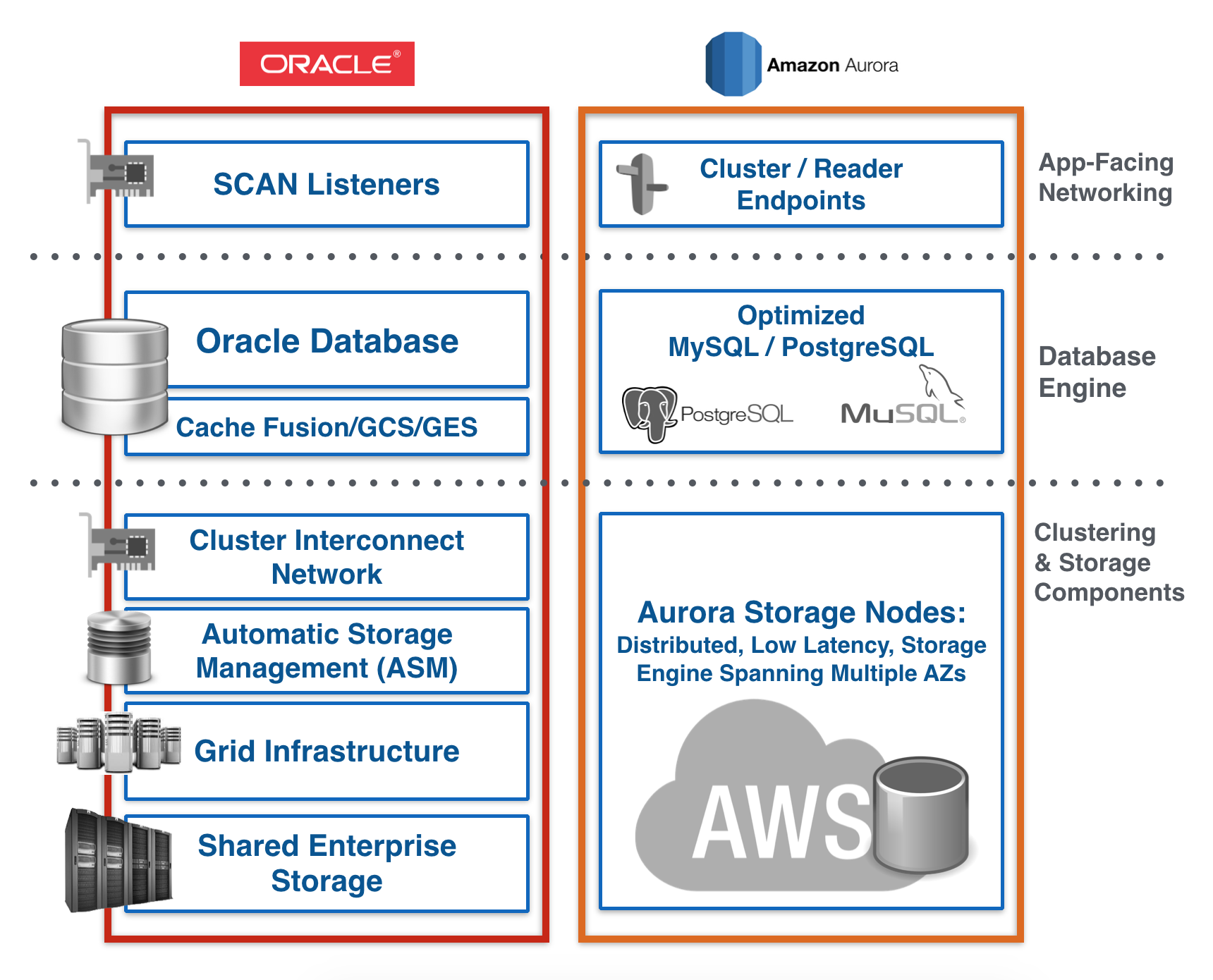
Stepping back and looking at the bigger picture, Amazon Aurora introduces a simplified solution that can function as an Oracle RAC alternative for many typical OLTP applications that need high performance writes, scalable reads, very high levels of high availability with lower operational overhead.
| Feature | Oracle RAC | Amazon Aurora |
| Storage | Usually enterprise-grade storage + ASM | Aurora Storage Nodes: Distributed, Low Latency, Storage Engine Spanning Multiple AZs |
| Cluster type | Active/Active
· All nodes open for R/W |
Active/Active · Primary node open for R/W
|
| Cluster virtual IPs | R/W load balancing: SCAN IP | R/W: Cluster endpoint
+ Read load balancing: Reader endpoint |
| Internode coordination | Cache-fusion + GCS + GES | – |
| Internode private network | Interconnect | – |
| Transaction (write) TTR from node failure | Typically 0–30 seconds | Typically < 30 Seconds |
| Application (Read) TTR from node failure | Immediate | Immediate |
| Max number of cluster nodes | Theoretical maximum is 100, but smaller clusters (2 – 10 nodes) are far more common | 15 |
| Provides built-in read scaling | Yes | Yes |
| Provides built-in write scaling | Yes (with limitations*) | No |
| Data loss in case of node failure | No data loss | No data loss |
| Replication latency | – | Milliseconds |
| Operational complexity | Requires database, IT, network and storage expertise | Provided as a cloud-solution |
| Scale-up nodes | Difficult with physical hardware, usually requires to replace servers | Easy using the AWS UI/CLI |
| Scale-out cluster | Provision, deploy, and configure new servers, unless you pre-allocate a pool of idle servers to scale-out on | Easy using the AWS UI/CLI |
| Database engine | Oracle | MySQL or PostgreSQL |
* Under certain scenarios, write performance can be limited and affect scale-out capabilities. For example, when multiple sessions attempt to modify rows contained in the same database block(s).
Summary
With the increasing availability of cloud-based solutions, many organizations are looking for a relational database engine that can provide very high levels of availability, great performance and easy read scalability—but in a cloud/PaaS model. Amazon Aurora can serve as a powerful alternative solution to commercial database cluster technologies, using AWS ecosystem components and open source database engines to greatly reduce complexity and operational database management overhead.