AWS Database Blog
Best practices for Amazon RDS PostgreSQL replication
September 2023: This post was reviewed and updated for accuracy.
Amazon RDS for PostgreSQL enables you to easily configure replicas of your source PostgreSQL instance to clear your read load and to create disaster recovery (DR) resources. You can configure Read Replicas within the same Region as the source or in a different Region.
When you use an RDS PostgreSQL Read Replica instance, you both offload your read workload to a replica instance and reserve the source instance’s compute resources for write activities. But you must configure Read Replicas properly and set appropriate parameter values to avoid replication lag.
Overview
In this post, I provide some best practices for properly configuring Read Replicas. I discuss the pros and cons of various RDS PostgreSQL replication options, including intra-Region, cross-Region, and logical replication. I recommend appropriate parameter values and metrics to monitor. The following steps show how to optimize disaster recovery strategy, read workload, and healthy source instance while minimizing replication lag.
General recommendation
As an overall best practice, make sure that the read queries you run on Read Replicas use the latest version of the data as the source instance. You can confirm the data version by looking at the replication lag in Amazon CloudWatch metrics. Minimizing replication lag avoids both query outputs based on stale data and compromises to source instance health.
Intra-Region replication
To create a read replica in the same AWS Region as the source instance, RDS PostgreSQL uses Postgres native streaming replication. Data changes at the source instance stream to Read Replica using streaming replication. If the process is for any reason delayed, replication lags. The following diagram illustrates how RDS PostgreSQL performs replication between a source and replica in the same Region:

In the following sections, I describe how to tune your Postgres instances to replicate RDS PostgreSQL instances hosted in the same Region optimally.
Proper value of wal_keep_size
In PostgreSQL, the wal_keep_size specifies the minimum size of past log file segments kept in the pg_wal directory. RDS PostgreSQL archives any WAL segments exceeding this parameter to Amazon S3 buckets.
If Read Replica does not find a WAL segment in the pg_wal location, Read Replica downloads the segment from the S3 bucket, then restores and applies it. In general, restoration from archive proceeds more slowly than streaming replication. So, the more WAL segments you keep on-instance, the faster the replication.
After the streaming replication stops, you should see the following error message in the database log: Streaming replication has stopped. If the streaming replication halts for a longer time, you might see this message in the database log: Streaming replication has been terminated.
By default, RDS PostgreSQL sets wal_keep_size to 2GB. You can modify the value of this parameter using RDS Parameter Group. This parameter is dynamic and changing its value doesn’t require instance restart.
For example, the following Postgres log file message suggests that RDS is recovering a read replica by replaying archived WAL files:
2018-11-07 21:01:16 UTC::@:[23180]:LOG: restored log file "000000010000001A000000D3“ from archive
After RDS replays enough archived WAL files on the replica to catch up, the read replica resumes streaming. At this point, RDS writes a line similar to the following to the log file:
2018-11-07 21:41:36 UTC::@:[24714]:LOG: started streaming WAL from primary at 1B/B6000000 on timeline 1
As a best practice, try to avoid exceeding the pg_wal directory’s maximum size, and therefore the slower process of restoring segments from the S3 bucket. To adjust this value, modify the value of wal_keep_size using parameter group at source instance.
Before launching a new replica instance, modify the value of wal_keep_size. Set this parameter high enough to prevent WAL files from archiving when streaming replication starts. For example, if you set wal_keep_size at 10GB, you can keep around 625 WAL files at the source instance.
Avoid heavy write activity at the source instance
At the source instance, as the part of the write activity, WAL first logs the transaction, then writes those changes into storage blocks. High write activity at the source instance can create high influx of WAL files. The multiplication of WAL files and replaying of these files on Read Replica slows down overall replication performance.
To track the rate of WAL file creation, see the TransactionLogsGeneration metric in CloudWatch metrics. This parameter shows the size of transaction logs generated per second. The following diagrams describe how high write activity at the source affects replication lag:
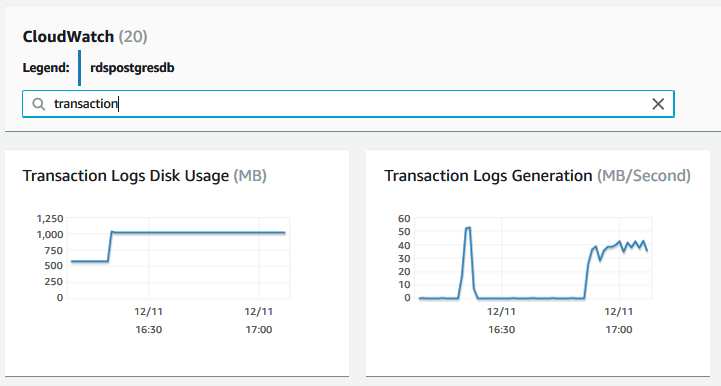
The metrics TransactionLogsDiskUsage, TransactionLogsGeneration, WriteIOPS, WriteThroughput, and WriteLatency show that the source instance was under heavy write pressure at around 16:20 and 17:00. This pressure increased the replication lag at Read Replica up to 11 mins at same time:
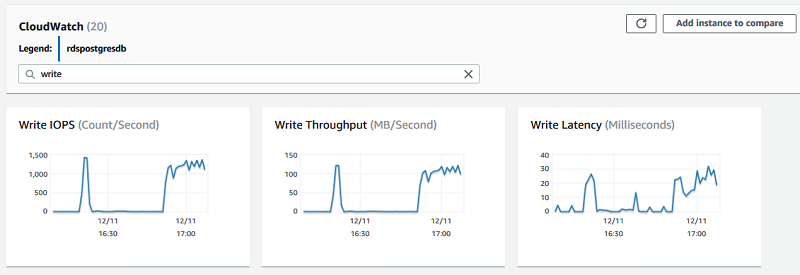

To avoid this situation, control and distribute write activity at the source instance. Instead of performing many write activities together, break them into small task bundles, and distribute them evenly throughout multiple transactions. Use CloudWatch alerts on metrics such as Write Latency and Write IOPS to keep alert to heavy writes on the source instance. Set wal_compression to ON to reduce the amount of WAL and, over time, reduce replication lag.
Avoid exclusive lock on source instance tables
At the source instance, whenever you run commands such as DROP TABLE, TRUNCATE, REINDEX, CLUSTER, VACUUM FULL, and REFRESH MATERIALIZED VIEW (without CONCURRENTLY), Postgres processes an Access Exclusive lock.
ACCESS EXCLUSIVE is the most restrictive lock mode (conflicts with all other lock modes). This lock prevents all other transactions from accessing the table for the lock’s hold duration. Generally, the table remains locked until the transaction ends. This lock activity is recorded in WAL and is replayed and held by Read Replica. The longer the table remains under an ACCESS EXCLUSIVE lock, the longer the replication lag.
To avoid such situations, AWS recommends monitoring for this situation by periodically querying the pg_locks and pg_stat_activity catalog tables. For example, the following query monitors locks in Postgres 9.6 and newer Postgres instances:
Parameter settings at Read Replica
You can also impact overall replication by setting some parameters at the replica instance. The parameter hot_standby_feedback specifies whether the replica instance sends feedback to the source instance about queries currently executing at replica instance.
By enabling this parameter, you curate the following error message at the source and postpone VACUUM on related tables (unless the read query has completed at Read Replica):
ERROR: canceling statement due to conflict with recovery
Detail: User query might have needed to see row versions that must be removed
In this way, a hot_standby_feedback-enabled replica instance can serve long-running SQLs, but can bloat tables at the source instance. If you do not monitor long-running queries at replica instances, you may face serious issues at the source instance, such as out-of-storage and Transaction ID Wraparound.
Alternatively, you can enable parameters like max_standby_archive_delay or max_standby_streaming_delay on the replica instance, to enable completion of long-running read queries. Both of these parameters pause WAL replay at the replica if the source data is modified while read queries are running on the replica. A value of -1 lets the WAL replay wait until the read query completes. However, this pause increases replication lag indefinitely and causes high storage consumption at the source due to WAL accumulation.
If you modify any of these three parameters, watch out for long-running read queries at the replica instance to keep the source instance healthy and keep any replication lag manageable.
You may also find the following SQL query useful. This query kills read transactions running longer than five minutes:
Read Replica instance configuration
Improper replica instance configurations can also impact replication performance. Use replicas of the same or higher instance class and storage type as the source instance. As the replica must replay the same write activity as the source instance, the use of a lower-instance class replica can cause high latency at Read Replica and increase replication lag.
Read Replica handles a similar write workload as the source instance, as well as additional read queries. It’s better to have Read Replica using at least the same or a higher instance class. Similarly, you should also match source and replica instance storage types. Mismatched storage configurations increase replication lag.
Cross-region replication
RDS PostgreSQL also supports cross-region replication. In addition to scaling read queries, cross-region Read Replicas provide solutions for disaster recovery and database migration between AWS Regions.
Instead of maintaining WAL retention based on wal_keep_size, cross-region replication uses a physical replication slot at the source instance. The CloudWatch metric OldestReplicationSlotLag shows the replication delay in terms of WAL size in MB. The metric TransactionLogsDiskUsage shows the storage size used by WAL files. As replication slots retain WAL, cross-region replication lag causes WAL accumulation at the source instance and can eventually cause serious issues such as out-of-storage.
As a best practice, you should also monitor IOPS performance at the source instance. That is, if the source instance runs out of IOPS, the high read latency can delay WAL file reading and cause high cross-region replication lag. Due to the longer geographic distances involved in cross-region replication, I recommend that you monitor cross-region replication lag closely to avoid high storage consumption at source instance due to WAL retention.
Logical replication
You can set up logical replication slots at RDS PostgreSQL instance, and stream database changes. AWS Database Migration Service (AWS DMS) provides the most common use case of logical replication.
Logical replication uses logical slots that remain ignorant of the recipient. If replication pauses or WALs go unconsumed, source instance storage can fill up quickly. To avoid this situation, make sure that you verify the following settings:
- Set parameter
rds.logical_replication: If this parameter enables the use of the RDS PostgreSQL instance as the DMS source, monitor DMS tasks. If the DMS task pauses or drops, or you find that change-data-capture is not enabled, disable this parameter. - Monitor replication slots: If you enable the previous parameter, unconsumed WAL files keep accumulating at the source. As a best practice, keep a close eye on replication slots and kill inactive ones. To that end, here are some important slot maintenance queries:
- a. Find inactive replications slots:
SELECT slot_name FROM pg_replication_slots WHERE active='f'; - b. Drop inactive replication slots:
SELECT pg_drop_replication_slot('slot_name'); - c. Combine the previous two commands in one, as follows:
SELECT pg_drop_replication_slot('slot_name') from pg_replication_slots where active = 'f';
- a. Find inactive replications slots:
RDS PostgreSQL supports native logical replication based on publication and subscription model. Unlike traditional physical replication, which replicates the entire instance along with all the databases, logical replication enables you to replicate a subset, such as table- or database-level changes. So, you can replicate a different major version of Postgres or consolidate multiple databases into one.
Bear in mind that logical replication has certain limitations. Issues may arise concerning the following:
- Schema changes: As a best practice, schema changes should be committed first by the subscriber, then by the publisher.
- Sequence data: Though logical replication replicates sequence data in serial or identity columns, in the event of switchover or failover to the subscriber database, you must update the sequences to the latest values.
- Truncation of large objects: A workaround of TRUNCATE could be DELETE. To avoid accidental TRUNCATE operations, you can REVOKE TRUNCATE privileges from tables.
- Partition tables: Logical replication treats partition tables as regular tables. Replicate partitioned tables on a one-to-one basis.
- Foreign tables: Logical replication does not replicate foreign tables.
Summary
In this post, I recommended best practices for configuring Read Replicas. I discussed the pros and cons of various RDS PostgreSQL replication options, including intra-region, cross-region, and logical replication operations.
Though RDS facilitates replication configuration and management, the best practices described here remain essential to minimizing replication lag. These practices also help optimize DR strategy, read workload, and healthy source instances. For more information about RDS Postgres Read Replica limitations, monitoring and troubleshooting, see Working with RDS PostgreSQL Read Replicas.
As always, AWS welcomes feedback. Please submit comments or questions below.
About the Authors
 Vivek Singh is a Principal Database Specialist Technical Account Manager with AWS focusing on RDS/Aurora PostgreSQL engines. He works with enterprise customers providing technical assistance on PostgreSQL operational performance and sharing database best practices. He has over 17 years of experience in open-source database solutions, and enjoys working with customers to help design, deploy, and optimize relational database workloads on AWS.
Vivek Singh is a Principal Database Specialist Technical Account Manager with AWS focusing on RDS/Aurora PostgreSQL engines. He works with enterprise customers providing technical assistance on PostgreSQL operational performance and sharing database best practices. He has over 17 years of experience in open-source database solutions, and enjoys working with customers to help design, deploy, and optimize relational database workloads on AWS.