AWS Database Blog
Building resilient applications with Amazon DocumentDB (with MongoDB compatibility), Part 2: Exception handling
Amazon DocumentDB (with MongoDB compatibility) is a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. You can use the same MongoDB 3.6, 4.0 or 5.0 application code, drivers, and tools to run, manage, and scale workloads on Amazon DocumentDB without worrying about managing the underlying infrastructure. As a document database, Amazon DocumentDB makes it easy to store, query, and index JSON data.
In Part 1 of this multi-part series, I discussed client-side configurations and how to use them for effective connection and cursor management. To build resilient applications, it’s important to understand the exceptions that an application should tolerate and how to handle them efficiently. In this post, I discuss exception handling mechanisms and associated retry techniques for various APIs provided by the MongoDB driver.
Error types
Applications interacting with Amazon DocumentDB can receive errors that are either transient or persistent. Transient errors occur when a blip at the network layer occurs, such as a connection timeout or TCP reset. Amazon DocumentDB automatically detects instance failures where a cluster has at least two instances and promotes one of the replica instances to primary during the automatic failover process. This process takes less than 30 seconds to complete, and the application receives transient errors until the failover process is complete. Handling these exceptions appropriately allows write operations to complete.
As a fully managed service, Amazon DocumentDB removes the undifferentiated heavy lifting by periodically performing maintenance and updating the database engine (cluster maintenance) or the instance’s underlying operating system (instance maintenance). When these maintenance patches are applied to the primary instance, applications receive transient errors. Transient errors are generally brief and last for milliseconds to a few seconds.
Persistent errors occur when there is an outage due to network unavailability or when connection to Amazon DocumentDB fails due to SSL handshake issues resulting from an expired certificate. Persistent errors are sustained and last for minutes to a few hours.
When an application receives errors, distinguishing between transient errors and persistent errors can become tricky. A network blip and a network outage return similar errors, thereby making the process of error handling challenging. Although the driver throws an error back to the application, there is no indication as to whether the operation was received by Amazon DocumentDB. This poses further challenges for certain write operations, such as updates, because the data may or may not be updated more than once. The operations impacted due to transient errors succeed when retried, but those impacted due to persistent errors continue to fail, wasting time and system resources on both the client and server side. To build resilient applications, it’s important to address these challenges and handle errors that have the potential to complete an operation that failed earlier.
Approach to exception handling
When dealing with transient errors due to automatic failover of the primary instance, the driver is aware of the new primary, once promoted. After a new primary is selected, the write operations begin to complete successfully. The application receives timeout errors during the primary promotion process. Persistent errors, on the other hand, time out after the server selection timeout duration is met. The default value for server selection timeout is 30 seconds, and if the primary selection process doesn’t complete within this duration, the error generally is persistent.
Applications receive the transient and persistent errors in the form of an exception. A common approach to handling these exceptions is to implement an appropriate retry strategy for selected exceptions. Ideally, you want to retry operations impacted by transient errors and avoid retrying operations impacted by persistent errors. Due to the challenges discussed earlier with respect to distinguishing between the transient and persistent errors, an all-or-nothing strategy for retry doesn’t work. If you don’t retry at all, you lose the opportunity to complete operations that failed earlier due to transient errors. The operations impacted by persistent errors benefit from no retry strategy. On the other hand, if you retry every operation until it succeeds, you waste time and system resources for persistent errors and in some cases cause application deadlock. The operations impacted by transient errors benefit from this strategy. Therefore, the all-or-nothing strategy for retry doesn’t cover both types of errors.
Transient errors like network blips generally last for 1–2 seconds. Retrying one time in 2 seconds helps address network blips. Reading from replica instances can benefit from a retry once strategy because the request is routed to a different read replica upon retry, if the current replica is unavailable. However, for transient errors such as automatic failover, a retry once strategy is suboptimal for write operations because retrying one time may not complete the write operation or may require a longer wait time. Retry with exponential backoff is a good strategy to handle transient errors. You can control the number of retries to avoid excessive retries for persistent errors. In this strategy, the network blips are handled in the first retry and the other transient errors are handled either in the first or subsequent retries. I provide samples later in this post.
Best practices
You can optimize the retry mechanism by applying the retry strategy to selected exceptions instead of all exceptions. This helps you avoid retrying for some of the known persistent errors, such as server selection timeout.
When implementing a retry strategy, it’s important that you make the operations idempotent. This makes sure that retrying operations multiple times doesn’t alter expected results. Let’s look at the CRUD operations in the MongoDB driver and how to make them idempotent.
Insert operation
An Amazon DocumentDB cluster can have only one primary instance that can accept write operations. When this primary instance is unavailable during failover, the inflight insert operations fail and new insert operations are queued until a new primary is selected. Retrying these inflight insert operations and other insert failures resulting from a network blip help to complete the operation eventually.
If the document _id field is set, and if the initial insert operation was successful, retry operation results in a duplicate key exception. This insert operation is idempotent.
If the document _id field isn’t set when sending the insert request, the retry operation results in duplicate data because the _id field is autogenerated by the database engine when not provided by the client. Such insert operations aren’t idempotent because a new document with a new _id field is created with each retry. MongoDB drivers support retryable writes, but DocumentDB does not. Instead, implementing retry strategies as mentioned in this post can make write operations resilient. The following diagram illustrates this architecture.

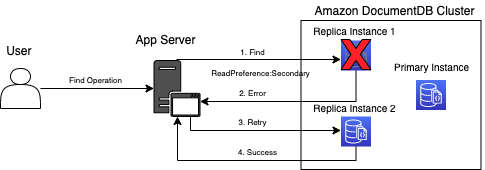
Find operation
Amazon DocumentDB can scale reads by adding read replicas with the following read preferences:
- secondary – The read requests are routed to replica instances
- secondaryPreferred – The read requests are routed to replicas first and then to the primary if all replicas are unavailable
- primary – The read requests are routed to the primary instance, but if the primary instance isn’t available, inflight requests fail and new requests are queued, and the retry logic similar to insert operations (discussed earlier) works well
- primaryPreferred – The read requests are routed to the primary instance first and then to replicas if the primary instance is unavailable
For more information about read preferences, see Read Preference Options.
Retrying read operations once for secondary or secondaryPreferred read preference should be sufficient to address the network blips. Read operations are idempotent and no additional effort is required to implement retry strategies. The latest versions of the MongoDB driver, which are compatible with MongoDB server 4.2, supports retryable reads when connecting to DocumentDB. The driver automatically performs a one-time retry for errors due to network or socket issues. The following diagram illustrates this architecture.
Update operation
Update operations are handled by the primary instance in Amazon DocumentDB. Update operations that set a specific value for a key in the document and use a defined predicate to identify these documents are idempotent. For example, the following update query results in the same outcome when called multiple times and therefore can be retried with no additional effort:
Update operations that uses operators such as $inc, $mul, and $add alter the value of the field for every call and are not idempotent. For example, the following update query increments the age for each run. Retrying this operation results in an age value that is equal to the number of retries, but the expected result is to increment age by 1.
When possible, use the $set operator to provide idempotency. For example, you can rewrite the preceding query using the find and update API. The find operation retrieves the document with the current value for age. The increment operation is handled at the application layer, and the update query uses the original value of age in the filter condition to make sure that the document is updated only if its value hasn’t changed. The $set idempotent operator is used to update the value, and retrying the update operation multiple times results in the same result. See the following code:
To implement a successful retry strategy when non-idempotent operators must be used, it’s important to make these update operations idempotent. You can accomplish this by running a two-step update process. In the first step, add a tracker to track operations that are yet to perform an increment operation. Idempotent operators like $addToSet make sure that the tracker is added only one time to the pendingOperations array, irrespective of the number of retries. See the following code:
In the second step, perform the intended increment operation to update the age and delete the pending operation tracker. Adding the tracker to the filter criteria makes sure that the update is performed on the appropriate record, irrespective of the number of retries. See the following code:
This two-step update operation provides idempotency but increases the load on the server because it requires two discrete updates for one logical update. Because performance is traded for resiliency, you should only follow this approach when required by your workload. For scenarios where the application stopped after adding the tracker, a periodic batch job to find pending trackers and update the counter is required. Also, the application should check if the pendingOperations array is empty while performing read operations to address corner cases, such as when a read operation is performed after Step 1 is complete and before Step 2 is complete. See the following code:
The following diagram illustrates this architecture.

Delete operation
Delete operations are handled by the primary instance in Amazon DocumentDB, and the retry strategy discussed in the insert operation section is applicable to delete operations as well. You can make delete operations idempotent by using the document _id to identify and delete the document. If the document is already deleted, the operation returns with an acknowledgement that no documents were deleted. When performing bulk deletes, for example running a purge script to remove historical data, retrying bulk delete may delete new documents created within the retry period. These bulk deletes can be made idempotent by using appropriate query predicates such as time period to delete documents. See the following code:
Transactions
Amazon DocumentDB supports ACID transactions, since version 4.0. Within the transaction context, multiple write operations can insert or update data across multiple collections or databases. Retry strategies discussed in the insert and update operation sections are applicable to transactions as well. Transactions are only committed to the database when explicitly committed from the application; therefore either all operations within the transaction are committed or none of them are. The latest versions of MongoDB driver that are compatible with MongoDB server 4.2 support a callback API that automatically retries transactions during failures and times out after 2 minutes.
Code samples
In Part 1 of this multi-part series, I provided code samples for connecting to Amazon DocumentDB. I now extend the code base to include samples for exception handling as discussed in the best practices section. These samples demonstrate idempotent CRUD operations along with retry once and retry with exponential backoff strategies.
For the MongoDB Java driver, retrying exceptions for the following exceptions should address most of the transient errors:
MongoSocketOpenExceptionMongoSocketReadExceptionMongoNotPrimaryExceptionMongoNodeIsRecoveringException
Let’s populate these exceptions to a hash set. See the following code:
The following method determines if an exception should be retried based on the value in the preceding list:
I use the preceding method while performing CRUD operations to retry specific exceptions for both retry once and exponential retry strategies.
Retry with exponential backoff
The following code is a generic method to retry all insert, update, and delete operations using exponential backoff. I’m using capped exponential backoff with jitter to determine wait times for every retry. The application stops retrying after MAX_RETRIES_FOR_WRITES to minimize resource utilization.
Retry once
The following method retries the read operations one time. If you’re using read preference as secondary or secondaryPreferred, retrying once should be sufficient because the request is routed to a healthy replica upon retry. Retry with exponential backoff works well for other read preferences.
Idempotent operations
These retry methods call various CRUD operations. As discussed in the previous section, find, insert, and delete operations are idempotent when referenced by document _id. For more information about implementing these methods, see Connecting to Amazon DocumentDB from Java Application. Let’s focus on the two-step implementation for update operations with $inc, $mul, and similar operators. The first step in the update process is to add a tracker to track the pending operation using the $addToSet idempotent operator. The operationID is a unique ID that facilitates tracking. See the following code:
The second step is to perform the update operation. In the following example code, I increment age using the $inc operator. I use the unique object ID from the previous step to filter the document. If the update operation succeeds, the pending operations tracker is removed and the document isn’t retrieved for further update operations.
Summary
In this post, I discussed various error types and best practices for handling them when building resilient applications. I explained the need for making operations idempotent and using appropriate retry strategies while dealing with various operations. The source code referred to in this post is available in the GitHub repo. For more information about developing applications using Amazon DocumentDB, see Developing with Amazon DocumentDB and Migrating to Amazon DocumentDB.
About the Author
 Karthik Vijayraghavan is a Senior DocumentDB Specialist Solutions Architect at AWS. He has been helping customers modernize their applications using NoSQL databases. He enjoys solving customer problems and is passionate about providing cost effective solutions that performs at scale. Karthik started his career as a developer building web and REST services with strong focus on integration with relational databases and hence can relate to customers that are in the process of migration to NoSQL.
Karthik Vijayraghavan is a Senior DocumentDB Specialist Solutions Architect at AWS. He has been helping customers modernize their applications using NoSQL databases. He enjoys solving customer problems and is passionate about providing cost effective solutions that performs at scale. Karthik started his career as a developer building web and REST services with strong focus on integration with relational databases and hence can relate to customers that are in the process of migration to NoSQL.