AWS Database Blog
Building resilient applications with Amazon DocumentDB (with MongoDB compatibility), Part 1: Client configuration
Amazon DocumentDB (with MongoDB compatibility) is a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. You can use the same MongoDB 3.6, 4.0 or 5.0 application code, drivers, and tools to run, manage, and scale workloads on Amazon DocumentDB without worrying about managing the underlying infrastructure. As a document database, Amazon DocumentDB makes it easy to store, query, and index JSON data.
MongoDB drivers provide parameters that you can use to configure applications that connect to Amazon DocumentDB. Although it’s good to have options, it’s important to understand how these parameters impact your application behavior and what to consider when determining appropriate values for these configurations. In this multi-part series, you learn about best practices for building applications when interacting with Amazon DocumentDB. In this first post, I discuss client-side configurations and how to use them for effective connection and cursor management.
Application configuration
Database connection management determines an application’s behavior in terms of performance, resource utilization, availability, and resiliency. In this section, I discuss various configuration options in the MongoDB driver for effective connection management with Amazon DocumentDB. I also discuss how Amazon DocumentDB handles write concerns, configurations for journaling, and best practices for working with connection and cursor limits. I use the MongoDB Java driver throughout this post, but most of the concepts explained here are applicable to other drivers as well.
A prerequisite for following the examples in this post is to provision an Amazon DocumentDB cluster and create an Amazon Elastic Compute Cloud (Amazon EC2) instance in the same VPC as your cluster to deploy your application. If you have not deployed an Amazon DocumentDB cluster yet, see Getting started with Amazon DocumentDB (with MongoDB compatibility); Part 1 – using Amazon EC2.
Connection string
Your application needs a database connection string to connect to the Amazon DocumentDB cluster. Navigate to your Amazon DocumentDB cluster to copy the connection string to connect to the cluster with an application. This connection string is built optimally to connect as a replica set and to use read preference as SecondaryPreferred. As shown in the following screenshot, copy the connection string to your application and replace the placeholder password with your cluster’s password.
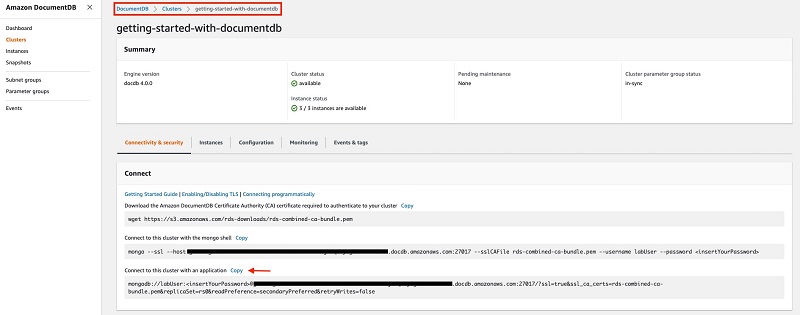
Your application can now connect to the Amazon DocumentDB cluster.
The benefit of connecting as a replica set is that it enables your MongoDB driver to discover cluster topology automatically, including when instances are added or removed from the cluster. Using a replica set allows your application to be aware of the primary instance in the cluster for sending write requests and replica instances for sending read requests. The Replica set rs0 is created automatically when you create an Amazon DocumentDB cluster. When you use replicaSet=rs0 in the connection string, it tells the MongoDB driver that you’re connecting as a replica set. The following diagram illustrates that, when connecting using replica set, the application has visibility to current cluster topology.
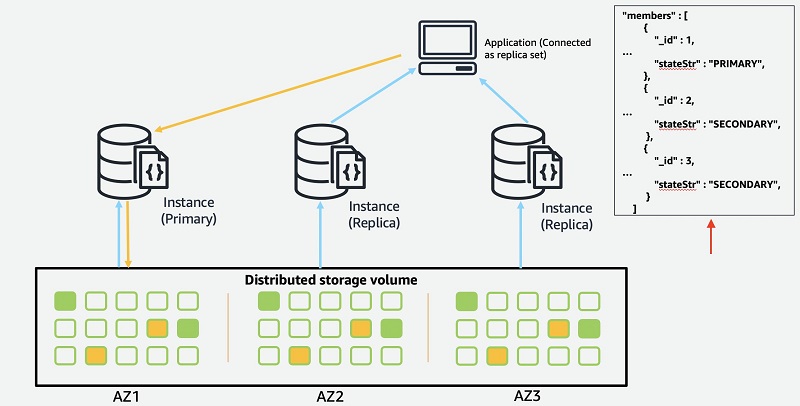
This view of topology is automatically updated when instances are added or removed.
The connection string has read preference specified as readPreference=SecondaryPreferred. When connected as a replica set, the application uses this setting to route the read requests to the replicas and write requests to the primary. For other values that can be configured for readPreference, see read preference options. The connection string includes a cluster endpoint, which is a CNAME pointing to the primary instance of the cluster. During failover, the cluster endpoint makes sure writes from the application are redirected to the newly selected primary instance.
Therefore, when you connect to your cluster as a replica set while using the readPreference as secondaryPreferred, your application can scale reads by using the available instances in your Amazon DocumentDB cluster. The reads from replica using secondaryPreferred are eventually consistent. The connection string allows the application to automatically load balance requests across available instances in the cluster and also to new instances when you perform a scale operation. Cluster endpoints provide resiliency for write operations by automatically routing the write requests to the primary instance.
If you’re connecting to the Amazon DocumentDB cluster from your application via SSH tunnel, you can’t connect using replica set mode. You should drop replicaSet=rs0 from the connection string provided in the next section. The application throws timeoutError if you connect using replica set mode via SSH. For more information see, connecting to Amazon DocumentDB cluster from outside an Amazon VPC.
Sample code
The following code shows how to connect to Amazon DocumentDB using the connection string:
Monitoring metrics
With the readPreference set to secondaryPreferred, the read workload should be distributed across all reader instances. The following visualization monitors the DatabaseConnections metric on the replica instances.
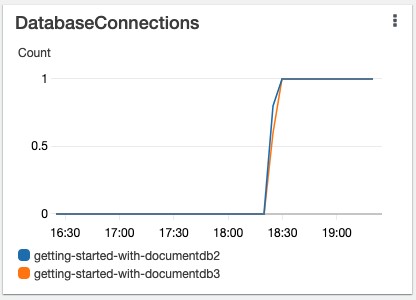
The metric shows that the application connected to both replica instances, getting-started-with-documentdb2 and getting-started-with-documentdb3, to perform read operations, and therefore has the ability to scale reads.
Let’s monitor the operations on the instances to validate that the reads are distributed to available replicas. In the application, I run a few inserts and find operations. The OpcountersQuery metric in the following visualization indicates the number of queries issued in a 1-minute period. Based on our connection string, the replica instances in the cluster should handle the find query requests.
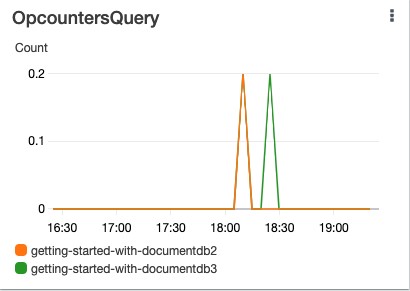
The following metric shows that only write (OpcountersInsert) requests are sent to our primary instance and no reads (OpcountersQuery) are sent to the primary instance.
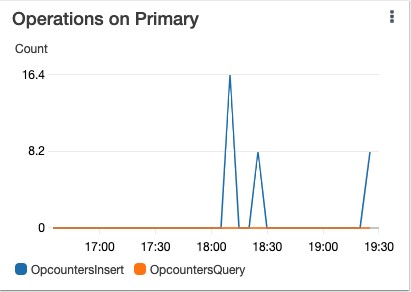
The CPUUtilization metric (see the following visualization) shows that about 5% CPU is utilized in each instance.
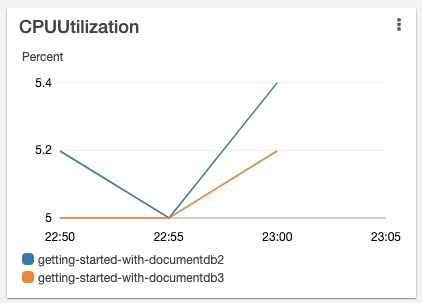
When this usage increases due to increase in read traffic, for example to 75%, you can scale reads by adding more read replicas. When connected as a replica set, the application uses the MongoDB driver to monitor the Amazon DocumentDB cluster topology changes in real time. As new read replicas are added to the cluster, the application automatically distributes the requests to these replicas as they become available, without any changes or manual intervention to the application. For more information on scaling replicas, see scaling Amazon DocumentDB clusters.
Client settings
MongoDB drivers provide additional capabilities to manage connections to the database. In this section, we look at some of these settings to understand how to configure applications using these settings.
Connection management
Connection pooling and related timeout configurations are key for connection management. It’s a best practice to explicitly declare these configurations, and the values vary based on your use case and access patterns. When you observe connection timeout issues on your application side, review the following configurations to ensure that appropriate values are used while creating connection to the database.
Connection pool
A connection pool is a cached set of connections that the application can reuse to avoid creating new database connections for every request. A MongoDB driver creates connections in the pool as defined by the minPoolSize and maxPoolSize setting, when needed by the application.
For Java driver, the default value for minPoolSize is 0 and maxPoolSize is 100. Default value varies by driver; for example, NodeJS driver has a default value of 5, whereas Python has default value of 100. To make sure that your application doesn’t run out of connections in the pool, it’s recommended to set max pool size to 10–20% more than the number of concurrent queries that the application runs.
Typically, the value for maxPoolSize is set taking into consideration slow queries, fast queries, and overall latency requirements of your application. If maxPoolSize is set too high, your application can create database connections up to the maxPoolSize, which results in more connections than what your application needs at sustained load. These connections use memory on your application server and can adversely affect your application’s performance. It’s important to benchmark your application by simulating production workloads to determine if the chosen value for your connection pool satisfies your latency requirements.
Connection pools are specific to MongoClient. Additionally, connections in the pool are declared when the MongoClient is initialized and all the connections in the pool are dropped when the MongoClient is stopped.
WaitQueueSize
WaitQueueSize is the maximum number of threads allowed to wait for a connection to become available from the pool. Synchronous drivers make blocking calls. These calls wait for the result of an operation and therefore it’s less likely that the application exhausts the wait queue. With asynchronous drivers, it’s common to perform concurrent operations in a request. This means using a connection from the pool for each operation, which can cause the connections to exhaust and require the application to have threads waiting for a connection. Therefore, wait queue size is generally applicable to asynchronous drivers, and available threads determine the parallel running of operations on the driver.
When maxPoolSize is set too low, the probability of getting the MongoWaitQueueFull exception is high, due to unavailability of connections. If you see this exception, try increasing maxPoolSize.
WaitQueueTimeMS
WaitQueueTimeMS is the maximum time a thread waits for a connection to become available on the connection pool. If all available connections in the pool are serving concurrent requests, new requests wait for the connections to complete the operation and be available in the pool. These new requests time out if a connection is not available within a time defined by WaitQueueTimeMS.
The default value varies by driver; for example, 2 minutes for a Java driver and 0 for Python.
If this time is reached and no connection becomes available, a MongoTimeoutException is raised. If you’re frequently running into this exception, identify long-running queries and fine-tune them or try increasing maxPoolSize.
ServerSelectionTimeoutMS
ServerSelectionTimeoutMS is the maximum time the driver waits to select an instance for an operation before raising a timeout exception. The driver selects the primary instance for write operations and the replica instance for read operations, and waits for a time defined by ServerSelectionTimeoutMS before raising a MongoTimeoutException.
The default value for this setting is 30 seconds and is sufficient for a new primary to be elected during failover.
It’s a best practice to handle this error to make the application aware of any hardware and software problems and take appropriate actions (like changing failover time). To make your application resilient to server failures, implement appropriate retry mechanisms like exponential backoff.
ConnectTimeoutMS
ConnectTimeoutMS is the maximum time the driver waits before a new connection attempt is stopped. The value for this setting depends on your network infrastructure. Because Amazon DocumentDB runs in a VPC-only setup and the clients are a part of this VPC, the connection timeout should not exceed the default value of 10 seconds.
The following are some of the common reasons for connection timeout errors:
- If your application throws
MongoTimeoutExceptionconsistently, it’s likely that your application server’s security group isn’t configured to interact with Amazon DocumentDB. To remediate this issue, ensure that your application is running in the same VPC as Amazon DocumentDB, and the security group assigned to Amazon DocumentDB has an inbound rule configured to receive requests from the application server on port 27017 over TCP. - If you’re setting a timeout in your application context to manage application lifecycle processes, for example setting a
ContextTimeoutin the go routine, you should ensure that the timeout value is set higher than the maximum session duration of your application. If these timeouts are set too low, the application can frequently close connections and open new connections, resulting in suboptimal utilization of resources. - If you see frequent connection failure errors on the client (such as connection reset), look for long-running queries that are holding up the connections and optimize these queries or increase timeout setting. It’s also a best practice to set
maxIdleTimeMSto close idle connections in the pool. You can also use a singleton pattern to create aMongoClientobject, which we explain later in this post.
MaxIdleTimeMS
MaxIdleTimeMS is the maximum time the driver waits before removing and closing an idle connection in the pool.
If you observe increasing connection timeout errors over a period of time, setting maxIdleTimeMS to a value that is greater than the maximum session duration of your application can help close idle connections.
SocketTimeout
SocketTimeout is the maximum time for sending or receiving data on a socket before timing out. This setting typically comes into play after a connection with the cluster is established. Each connection uses the TCP socket to send and receive data. The driver raises the appropriate type of MongoSocketException if it can’t read or write to the socket.
It’s best to leave this setting at its default value of 0 (no timeout) because operations may not take the same time to complete, depending upon your access patterns and queries. The default value for SocketTimeout varies by driver. For example, Java and NodeJS have 0 or no SocketTimeout by default, but Ruby has a default value of 5 seconds. You should only change this value if you’re certain about your query patterns and response times.
It’s important to note that the queries on the database don’t time out when the SocketTimeout error occurs and only the client socket is closed.
Sample code
The following code uses MongoClientSettings to create a client (compared to the connection string approach in the previous section) as a convenient way to configure connection management settings:
Durable writes
Amazon DocumentDB replicates six copies of the data across three Availability Zones. MongoDB drivers provide an option to tune write concern and journal files. Amazon DocumentDB doesn’t expect developers to set write concern and journal, and ignores the values sent for w and j (writeConcern and journal). Amazon DocumentDB always writes data with writeConcern: majority and journal: true so the writes are durably recorded on a majority of nodes before sending an acknowledgement to the client. This behavior makes sure that there is no data loss after receiving an acknowledgment from the database and removes the burden from developers to manually tune write concerns.
For example, Amazon DocumentDB ignores the following code::
The code is implicitly replaced as the following:
Amazon DocumentDB does not support the wtimeout option. The value passed in this setting is ignored and writes to the primary instance are guaranteed not to block indefinitely. Because the writes are always durable, setting the read preference to Primary provides read-your-own-write consistency, if desired.
Cursor and connection limits
When designing your application, it’s important to understand the service limits and quotas because it may have an impact on your design decision. For example, if your application requires support for a high number of concurrent requests and therefore needs more connections, you should select an instance size that satisfies your connection limit requirements. In this section, I discuss cursor and connection limits in detail.
Cursor limits
When you perform read operations against the database that results in multiple documents (greater than batch size), the server returns a cursor. You can access documents by iterating over this cursor. Amazon DocumentDB gets the full result set but instead of sending all the data to the client, it holds the result set in memory and returns the query results in batches to the client.
The client can iterate through the result set using the cursor, and the batch size can be overridden using the batchSize() method on the cursor. If cursors are not closed, Amazon DocumentDB continues to hold the data in memory, waiting for the cursor to be utilized again.
It’s a best practice to close cursors when you complete processing the result set. Open cursors that are idle are closed after 10 minutes of inactivity but, when managed proactively, can save you resources and cost.
Amazon CloudWatch metric DatabaseCursorsMax indicates the maximum number of open cursors on an instance in a 1-minute period. It’s recommended to set an alarm when this metric is at 80% of the limit. If this alarm occurs, your developers can inspect the application code to make sure that cursors are closed or scale your database instances to increase the cursor limits.
The following code is an example of closing the cursor:
If the preceding code is called by two users as shown in the following diagram, the application opens two connections to the Amazon DocumentDB cluster. The application receives one cursor for each request.
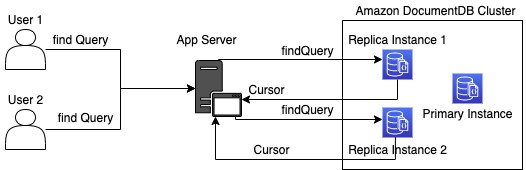
When cursors are opened, they place a lock on the memory pages of replica instance. In write-heavy use cases, when the cursors aren’t closed, the lock prevents the replica instance from catching up with the writes from the primary instance. To avoid catchup delays, Amazon DocumentDB reboots the instance if the lock is not released in 30 seconds.
When an instance reboots, connection to the instance from application is lost and re-established, and your application receives MongoSocketException.
You can monitor the DatabaseCursorsTimedOut metric to observe number of cursors that timed out in a 1-minute period. If the value for this metric consistently increases, it’s a good idea to review the application and identify opportunities to close the cursor.
Connection limits
Each MongoClient connecting to Amazon DocumentDB uses database connections as defined by the minimum and maximum pool size setting. Creating connections consumes memory on the application server and therefore must be managed appropriately. For instance, let’s say that you have a microservice that has one query that takes 3 seconds to complete, and five operational queries that take 1 second to complete. A pool size of three should be sufficient to satisfy the SLA of 3 seconds for this microservice. One connection is used by the long-running query for 3 seconds, and two connections are used by operational queries, and the total runtime is approximately 3 seconds.
The connection pool size is associated to the MongoClient object, and it’s a best practice to always create MongoClient as a singleton object. It’s not common to increase the ConnectionPerHost setting; if you decide to do so, stress test the value that is appropriate for your use case before deploying to production.
In the microservice example, if there are 10 requests to your microservice, the maximum number concurrent connections is 3 (1 * 3), if MongoClient is created as a singleton object, assuming clients are using synchronous driver. If MongoClient is not created as a singleton object, the maximum number of concurrent connections is 30 (10 * 3), because one instance of MongoClient is created for each request to microservice. For clients using asynchronous drivers, this number should be further multiplied by the value set for WaitQueueSize. If you have other applications writing data to Amazon DocumentDB, such as AWS Database Migration Service (AWS DMS), AWS Lambda, or similar, you should also factor the additional connections from these services and applications on the primary instance.
If you’re connecting to Amazon DocumentDB from Lambda, it’s a best practice to create the MongoClient instance outside of the handler function in the Lambda execution context as a global variable. This allows Lambda to reuse the already established Amazon DocumentDB connections and reduces runtime, because the Lambda doesn’t have to create a new connection on every invocation. For sample code, refer this python application.
Amazon DocumentDB allows you to monitor the maximum number of open connections on every instance using the DatabaseConnectionsMax metric (see the following screenshot).
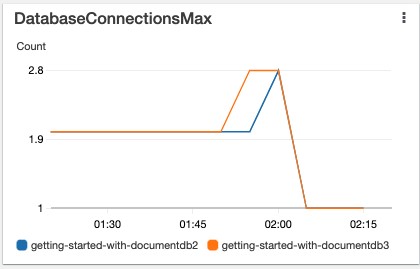
It’s recommended to set an alarm when this metric is at 80% of the limit. In response to this alarm, you should inspect your connection pool configuration or scale your database instances to increase the connection limits.
If you’re seeing ECONNREFUSED errors on the client side, it’s possible that you’re hitting the instance limit and you should consider scaling your instances up.
Summary
In this post, I discussed connection strings and best practices for defining connection management configurations. I also discussed cursor and connection limits and some of the common issues and possible solutions for establishing and managing Amazon DocumentDB connections. The source code referred to in this post is available in GitHub. For more information about developing applications using Amazon DocumentDB, see Developing with Amazon DocumentDB and Migrating to Amazon DocumentDB.
About the Author
 Karthik Vijayraghavan is a Senior DocumentDB Specialist Solutions Architect at AWS. He has been helping customers modernize their applications using NoSQL databases. He enjoys solving customer problems and is passionate about providing cost effective solutions that performs at scale. Karthik started his career as a developer building web and REST services with strong focus on integration with relational databases and hence can relate to customers that are in the process of migration to NoSQL.
Karthik Vijayraghavan is a Senior DocumentDB Specialist Solutions Architect at AWS. He has been helping customers modernize their applications using NoSQL databases. He enjoys solving customer problems and is passionate about providing cost effective solutions that performs at scale. Karthik started his career as a developer building web and REST services with strong focus on integration with relational databases and hence can relate to customers that are in the process of migration to NoSQL.