AWS Database Blog
Detect and fix low cardinality indexes in Amazon DocumentDB
Amazon DocumentDB (with MongoDB compatibility) is a fully managed native JSON document database that makes it easy and cost effective to operate critical document workloads at virtually any scale without managing infrastructure. It’s a best practice to create indexes to improve query performance especially when database size is very large. Without indexes, queries have to run a lot longer to filter out documents that does not meet the criteria. Another best practice for databases to have indexes created on fields that are highly cardinal or have high number of unique values. This post walks through how you can proactively detect and fix low cardinality indexes across all you DocumentDB databases and collections.
Amazon DocumentDB uses a B-tree data structure for its indexes. A B-tree index uses a hierarchical structure that stores data in its nodes in a sorted order. Keeping the data sorted this way allows for reading, inserting, and deleting data in a memory-efficient way. As new data is written, in addition to modifying the documents in the collection, the indexes are updated, which can impact write latencies and increase IOPS. By choosing fields that have high cardinality (fields with high number of unique values), such as an identity field, you increase the index selectivity. Conversely, choosing a low cardinality field such as Boolean, where there are only two unique values, can retrieve more information than is needed, which increases memory usage and the risk of going into the distributed storage volume. The goal with index selectivity is to allow the query to filter as much data as possible up front, thereby letting the query processor do less work.
When you are running tens or hundreds of Amazon DocumentDB clusters, it’s important to proactively detect and monitor the change in cardinality. Though in some cases low cardinality indexes may be required or the collection is small enough that they are not causing any issue at the moment, in a lot of cases low cardinality indexes on large collections causes performance issues. In this post, we walk through steps of reviewing and remediating low cardinality indexes for existing Amazon DocumentDB clusters.
In order to demonstrate this we use sample datasets available at Amazon DocumentDB samples repository and the utility available on the following GitHub repo to find indexes with low cardinality.
Low cardinality detection utility overview
This utility can sample documents (default 100K per index) in each collection of a DocumentDB cluster to create a report on cardinality. Users can then take this report and focus on indexes that are below the recommended 1% cardinality. The script does a collection scan for random samples for each collection and depending upon the sample size and instance type it may impact ongoing workload. You can either run this on non-prod environment or use a reader instance which is not actively serving traffic.
The GitHub repo contains instructions on how to load sample data, create test indexes, and run cardinality tests. If you’re running this on your own cluster, you can skip to step 6 as documented in the README file.
The following table summarizes the parameters supported by the cardinality test script. Except for --connection-string, the rest are optional parameters. By default, the cardinality test runs on all databases and collections. You can scope the test down to a single database or collection by passing in --database or --collections parameters.
| Parameter | Details | Default |
--uri |
Connection string of Amazon DocumentDB instance. | N/A |
--max-collections |
Maximum number of collections to scan in a database. | 100 |
--threshold |
Index cardinality threshold percentage. Indexes with less than this percentage will be reported. Value should be numeric integers or decimal type. | 1 |
--databases |
Command separated list of databases to check cardinality. | All |
--collections |
Command separated list of collections to check cardinality. | All |
--sample-count |
Max documents to sample for each index. Increasing this limit may result in higher IOPS cost and extended runtime. | 100000 |
Prerequisites
The host used to run the utility must meet the following prerequisites:
- CLI access to DocumentDB cluster through ssh-tunnel or in an Amazon Elastic Compute Cloud (Amazon EC2) instance shell within the same VPC.
- Python 3.9+ installed
- Pandas
- Mongo Client 4.0+
Setup and run the Cardinality Detection Utility
To configure and use the utility perform the following actions:
- Connect to Amazon DocumentDB via a mongo shell (make sure you have indexes in your collections). You can run the following query in the mongo shell:

- Download the project from GitHub and the certificate for DocumentDB connections.
- Find Amazon DocumentDB cluster or reader endpoint on the Amazon DocumentDB console. Navigate to your database and then choose the Configuration tab. Copy and save that endpoint.

- Run the utility replacing the variables
[DOCDB-USER],[DOCDB-PASS]and[DOCDB-ENDPOINT]with your cluster’s information.It may take few mins for script to finish. The output will be similar to the following screenshot:

In this example, the script found 3 out of 5 indexes total (_idindexes are ignored) that are below the low cardinality threshold of 1%. The script also saves a CSV file in the current directory that has a detailed report, which looks like the following screenshot:
The report shows that Case_Type, Province_Type, and Country_Region are indexes of low cardinality and may not be good candidates for indexes.
This utility can potentially read large amount of data (100,000 docs for each index) so it’s recommended to run this script in a QA or representative environment. To be safer, you can run this during off-peak hours. You can also clone your production cluster and run cardinality detection on cloned cluster.
Fixing low cardinality indexes
This section explains how you can fix low cardinality indexes found in the report generated by index cardinality detection utility.
Delete unused indexes
Indexes are often left unused because the requirements have changed or they were created by mistake. Amazon DocumentDB keeps statistics on the number of times indexes are utilized. For instructions on how to find and delete unused indexes, refer to How do I analyze index usage and identify unused indexes? It’s recommended to delete used indexes regardless if they are low cardinality or not.
Build compound indexes if possible
In the example mentioned in this post, we checked samplecollection indexes for cardinality and found three indexes with low cardinality: Case_Type, Country_Region, and Province_State. If a user searches for all three at the same time, then it makes sense to build a compound index instead of adding multiple search clauses. You can do this with the following code:
To make sure compound indexes gets utilized, the order of the fields supplied in the query must be the same as your index’s. Depending upon your collection size, it may take from a few minutes to hours to complete the index creation. You can speed up the process by increasing workers for the background job as described in Managing Amazon DocumentDB Indexes. A successful build looks similar to the following screenshot:
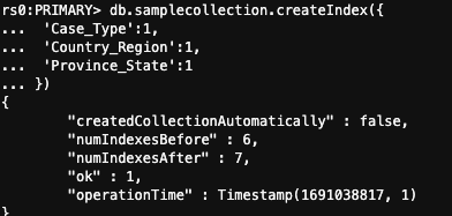
After creating the index, you can review the query explain executationStats status to make sure the index was used and the property nReturned shows a smaller number.
You can test with a query similar to the following:
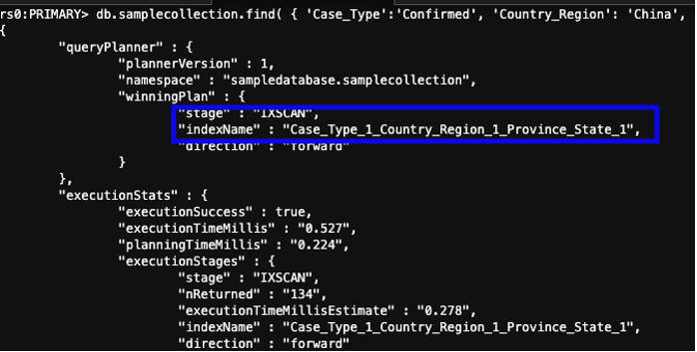
The preceding query is less expensive to run at scale. After you confirm the indexes have been created, you can keep the compound index and delete indexes you don’t use anymore. This also helps reduce storage and may improve data ingestion performance.
Cleanup
Following command deletes the in databases, collections and indexes created as part of instructions described in the Github project. Skip this test if you did not use the sample database used.
Conclusion
Low cardinality generally becomes an issue when your collection size starts to grow into millions of documents and you constantly have to scale up instances to keep up with memory and CPU requirements. This makes cardinality hygiene very important for larger collections, but it’s good to keep an eye on cardinality for smaller collections too because they may pose issues in the future. In this post we explained covered how you can use Cardinality Detection Script to proactively monitor the health of indexes and report back to application teams when cardinality thresholds are going below the recommendations.
Post your questions or feedback in the comments section or create a Github issue suggesting enhancements to the script.
About the Author
 Puneet Rawal is a Chicago-based Sr Solutions Architect specializing in AWS databases. He holds more then 20 years of experience in architecting and managing large-scale database systems.
Puneet Rawal is a Chicago-based Sr Solutions Architect specializing in AWS databases. He holds more then 20 years of experience in architecting and managing large-scale database systems.