AWS Database Blog
Easier and faster graph machine learning with Amazon Neptune ML
Amazon Neptune ML provides a simple workflow for training machine learning (ML) models for graph data. With version 1.0.5.0, Neptune ML delivers additional enhancements to all the steps of this workflow to reduce cost, increase speed, and offer a more flexible modeling experience. Starting with data export and data processing, Neptune ML now provides additional feature encoding methods and a new option to automatically infer the feature encoding method for properties. During model training, Neptune ML now supports early stop on training jobs during hyperparameter search, as well as the option perform hyperparameter search incrementally across multiple instances of Neptune ML model training.
This post is third in a series of posts detailing new features of Neptune ML:
- In Part 1, you saw how to use the new tasks supported by Neptune ML: edge classification and edge regression
- In Part 2, you saw how to use a Neptune ML trained model to get predictions for evolving graph data
- In this post, you learn about the enhanced feature processing and greater customizations for faster training that Neptune ML provides
Simplified and enhanced graph data preprocessing
Graph property values come in different formats and data types. To use these properties as features during model training, you must encode the features properly. Neptune ML now has additional capabilities to detect property data types and perform feature engineering, with minimal effort from the user during the data export and data processing steps.
When the training graph data is being exported, the Neptune export tool detects the data types of properties and writes a default mapping for each feature property in the generated training-data-configuration.json file. For example, integer and float properties are set to “numerical” to denote numerical feature encoding, and string property values are set to “auto” to denote automatic inference of feature encoding. To specify overrides to the Neptune export tool, you can pass feature encoding specifications to the additionalParams section. Neptune ML now supports a datetime feature encoding for datetime data types as well as a new text preprocessing encoding (text-tfidf) for string text properties. For all feature encoding types supported by Neptune ML, see the documentation page.
During the data processing step, the training-data-configuration.json file generated by the export tool is parsed and used to inform feature transformations. As detailed earlier, the export tool sometimes assigns the encoding type “auto” to certain properties by default. You can also set auto as a feature encoding method for any property in the graph. When the feature encoding type for a property is set to “auto“, Neptune ML data processing automatically infers the feature encoding to use based on the raw data values of the property. For some heuristics used to perform auto feature type inference, see this section of the Neptune ML data processing documentation.
Furthermore, Neptune ML now uses a simplified training-data-configuration.json file to configure how the model training graph is constructed and data preprocessing is performed. You can review numerous examples of how to use Neptune export to generate custom data configuration files for various ML tasks. Although the Neptune export tool generates a default data configuration file based on the additionalParams you supply, you can also customize this configuration file after the export is complete. This means that you can export data only one time and modify just the training-data-configuration.json file to include or exclude nodes or edges to construct different training graphs, try different train/validation/test splits, or try different feature encoding methods.
Faster model training
During model training, Neptune ML launches an Amazon SageMaker hyperparameter tuning job, which launches multiple instances of SageMaker training jobs with different hyperparameter configurations so as to obtain the best training configuration for the model. Neptune ML supports early stopping of a particular training job by regularly evaluating the model on the validation set. Initially, performance improves as training proceeds, but when the model starts overfitting, it starts to decline again. The early stopping feature identifies the point at which the model starts overfitting and halts model training at that point. This feature is enabled by default, but you can disable it or control the early stopping behavior by editing the model-hpo-configuration file.
Neptune ML also supports HPO early stop for the hyperparameter tuning job. HPO early stop uses the early stopping feature in SageMaker to detect and stop training jobs that aren’t improving significantly compared to other training jobs in hyperparameter search in order to provide cost savings and faster overall training. By default, both early stop features are enabled and work together to stop training jobs early based on the training progression of the particular job and its relative performance compared to other training jobs.
In addition, Neptune ML now only computes model artifacts for the best training job. In other words, instead of precomputing node embeddings at the end of training for all training jobs, Neptune ML selects the best training job according to the evaluation metric after the hyperparameter tuning job is complete and computes node embeddings, and other model artifacts necessary for inference, for that particular training job. You can still compute the node embeddings and model artifacts for other training jobs using the model transform API.
Additional training controls including incremental training
Neptune ML now supports passing in a previousModelTrainingJobId as an input parameter when creating a new model training job. This additional parameter allows Neptune ML to link the previous ML model training job with the new one to ensure that it uses the previous ML model training job as a training point for hyperparameter exploration. This feature of Neptune ML uses the SageMaker hyperparameter warm start feature to launch SageMaker training runs in the new Neptune ML training job using hyperparameter configurations informed by the previous Neptune ML training job.
This incremental training feature supports use cases where you want to gradually increase the number of overall SageMaker resources over several Neptune ML training jobs based on the results you see after each iteration. In addition, the feature allows you to transfer the state of hyperparameter search from a previous model training job to train a new model on new data, using the Neptune ML model retraining with HPO warm start workflow, as shown in the following diagram.
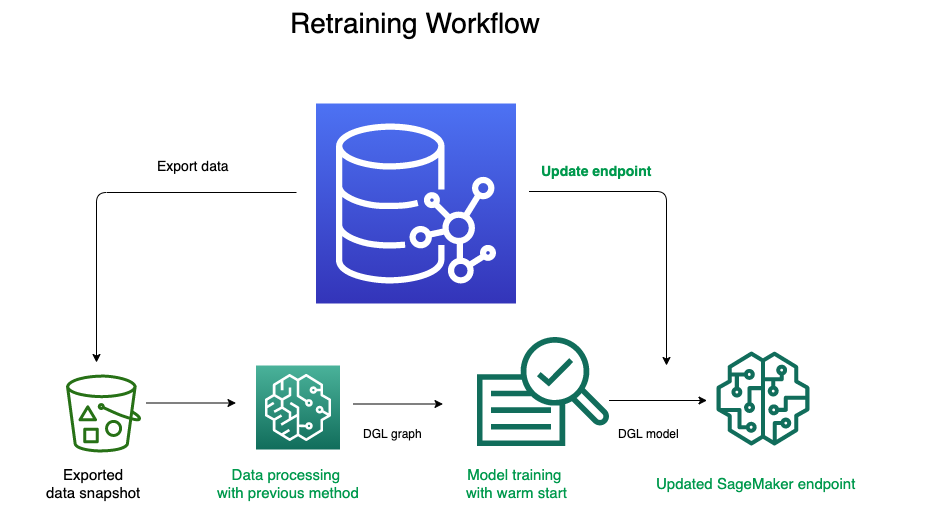
You can also change the ranges of hyperparameters that you used in a previous Neptune ML training job, change static hyperparameters to tunable, or change tunable hyperparameters to static values by editing the model-hpo-configuration without restarting the hyperparameter search from scratch.
The notebook example on the Neptune workbench contains a full example to demonstrate these new capabilities on an example dataset. You can run this by using the Neptune ML AWS CloudFormation quick start to launch a Neptune cluster with the Neptune workbench and Neptune ML.
Conclusion
In this post, you learned about new capabilities that Neptune ML delivers, including datetime and text_tfidf feature encoding, auto feature encoding, a simpler training-data-configuration.json format, model training early stopping, HPO early stop, and HPO warm start. These features further simplify the process of performing ML on graphs and deliver both cost and speed improvements.
This post is part of a three-post series on new Neptune ML features. Part 1 focuses on the new tasks of edge classification and edge regression. Part 2 details how to use the Neptune ML incremental prediction feature to obtain predictions for new graph data without retraining your model.
About the Author
 Soji Adeshina is an Applied Scientist at AWS where he develops graph neural network-based models for machine learning on graphs tasks with applications to fraud & abuse, knowledge graphs, recommender systems, and life sciences. In his spare time, he enjoys reading and cooking.
Soji Adeshina is an Applied Scientist at AWS where he develops graph neural network-based models for machine learning on graphs tasks with applications to fraud & abuse, knowledge graphs, recommender systems, and life sciences. In his spare time, he enjoys reading and cooking.