AWS Database Blog
Hidden dangers of duplicate key violations in PostgreSQL and how to avoid them
A common coding strategy is to have multiple application servers attempt to insert the same data into the same table at the same time and rely on the database unique constraint to prevent duplication. The “duplicate key violates unique constraint” error notifies the caller that a retry is needed. This seems like an intuitive approach, but relying on this optimistic insert can quickly have a negative performance impact on your database. In this post, we examine the performance impact, storage impact, and autovacuum considerations for both the normal INSERT and INSERT..ON CONFLICT clauses. This information applies to PostgreSQL whether self-managed or hosted in Amazon Relational Database Service (Amazon RDS) for PostgreSQL or Amazon Aurora PostgreSQL-Compatible Edition.
Understanding the differences between INSERT and INSERT..ON CONFLICT
In PostgreSQL, an insert statement can contain several clauses, such as simple insert with the values to be put into a table, an insert with the ON CONFLICT DO NOTHING clause, or an insert with the ON CONFLICT DO UPDATE SET clause. The usage and requirements for all these types differ, and they all have a different impact on the performance of the database.
Let’s compare the case of attempting to insert a duplicate value with and without the ON CONFLICT DO NOTHING clause. The following table outlines the advantages of the ON CONFLICT DO NOTHING clause.
| .. | Regular INSERT | INSERT..ON CONFLICT DO NOTHING |
| Dead tuples generated | Yes | No |
| Transaction ID used up | Yes | No |
| Autovacuum has more cleanup | Yes | No |
| FreeStorageSpace used up | Yes | No |
Let’s look at simple examples of each type of insert, starting with a regular INSERT:
The INSERT 0 1 depicts that one row was inserted successfully.
Now if we insert the same value of id again, it errors out with a duplicate key violation because of the unique primary key:
The following code shows how the INSERT… ON CONFLICT clause handles this violation error when inserting data:
The INSERT 0 0 indicates that while nothing was inserted in the table, the query didn’t error out. Although the end results appear identical (no rows inserted), there are important differences when you use the ON CONFLICT DO NOTHING clause.
In the following sections, we examine the performance impact, bloat considerations, transaction ID acceleration and autovacuum impact, and finally storage impact of a regular INSERT vs. INSERT..ON CONFLICT.
Performance impact
The following excerpt of the commit message adding the INSERT..ON CONFLICT clause describes the improvement:
“This is implemented using a new infrastructure called ‘speculative insertion’. It is an optimistic variant of regular insertion that first does a pre-check for existing tuples and then attempts an insert. If a violating tuple was inserted concurrently, the speculatively inserted tuple is deleted and a new attempt is made. If the pre-check finds a matching tuple the alternative DO NOTHING or DO UPDATE action is taken. If the insertion succeeds without detecting a conflict, the tuple is deemed inserted.”
This pre-check avoids the overhead of inserting a tuple into the heap to later delete it in case it turns out to be a duplicate. The heap_insert () function is used to insert a tuple into a heap. Back in version 9.5, this code was modified (along with a lot of other code) to incorporate speculative inserts. HEAP_INSERT_IS_SPECULATIVE is used on so-called speculative insertions, which can be backed out afterwards without canceling the whole transaction. Other sessions can wait for the speculative insertion to be confirmed, turning it into a regular tuple, or canceled, as if it never existed and therefore never made visible. This change eliminates the overhead of performing the insert, finding out that it is a duplicate, and marking it as a dead tuple.
For example, the following is a simple select query on a table that attempted 1 million regular inserts that were duplicates:
For comparison, the following is a simple select query on a table that used the INSERT..ON CONFLICT statement:
The difference in time is because of the 1 million dead tuples generated in the first case by the regular duplicate inserts. To count the actual visible rows, the entire table has to be scanned, and when it’s full of dead tuples, it takes considerably longer. On the other hand, in the case of INSERT..ON CONFLICT DO NOTHING, because of the pre-check, no dead tuples are generated, and the count(*) completes much faster, as expected for just one row in the table.
Bloat considerations
In PostgreSQL, when a row is updated, the actual process is to mark the original row deleted (old value) and then insert a new row (new value). This causes dead tuple generation, and if not cleared up by vacuum can cause bloat. This bloat can lead to unnecessary space utilization and performance loss as queries scan these dead rows.
As discussed earlier, in a regular insert, there is no duplicate key pre-check before attempting to insert the tuple into the heap. Therefore, if it’s a duplicate value, it’s similar to first inserting a row and then deleting it. The result is a dead tuple, which must then be handled by vacuum.
In this example, with the pg_stat_user_tables view, we can see these dead tuples are generated when an insert fails due to a duplicate key violation:
As we can see, n_dead_tup currently is 4. We attempt inserting five duplicate values:
We now observe five additional dead tuples generated:
This highlights that even though no rows were successfully inserted, there is an increase in dead tuples (n_dead_tup).
Now, we run the following insert with the ON CONFLICT DO NOTHING clause five times:
Again, checking pg_stat_user_tables, we observe that there is no increase in n_dead_tup and therefore no dead tuples generated:
In the normal insert, we see dead tuples increasing, whereas no dead tuples are generated when we use the ON CONFLICT DO NOTHING clause. These dead tuples result in unnecessary table bloat as well as consumption of FreeStorageSpace.
Transaction ID usage acceleration and autovacuum impact
A PostgreSQL database can have two billion “in-flight” unvacuumed transactions before PostgreSQL takes dramatic action to avoid data loss. If the number of unvacuumed transactions reaches (2^31 – 10,000,000), the log starts warning that vacuuming is needed. If the number of unvacuumed transactions reaches (2^31 – 1,000,000), PostgreSQL sets the database to read-only mode and requires an offline, single-user, standalone vacuum. This is when the database reaches a “Transaction ID wraparound”, which is described in more detail in the PostgreSQL documentation. This vacuum requires multiple hours or days of downtime (depending on database size). More details on how to avoid this situation are described in Implement an Early Warning System for Transaction ID Wraparound in Amazon RDS for PostgreSQL.
Now let’s look at how these two different inserts impact the transaction ID usage by running some tests. All tests after this point are run on two different identical instances: one for regular INSERT testing and another one for the INSERT..ON CONFLICT clause.
Duplicate key with regular inserts
In the case of regular inserts, when the inserts error out, the transaction is canceled. This means if the application inserts 100 duplicate key values, 100 transaction IDs are consumed. This could lead to autovacuum runs to prevent wraparound in peak hours, which consumes resources that could otherwise be used for user workload.
For testing the impact of this, we ran a script using pgbench to repeatedly insert multiple key values into the blog table:
The script runs the INSERT statement 1 million times, and if it throws an error, prints out duplicate row.
We used the following pgbench command to run it through multiple connections:
We observed multiple notice messages, because all were duplicate values:
For this test, we modified some autovacuum parameters. First, we set log_autovacuum_min_duration to 0, to log all autovacuum actions. Secondly, we set rds.force_autovacuum_logging_level to debug5 in order to log detailed information about each run.
As the script did more and more loops, the transaction ID usage increased, as shown in the following visualization.

On this test instance, only our contrived workload was being run. We used Amazon CloudWatch to observe that as soon as MaximumUsedTransactionIds hit autovacuum_freeze_max_age (default 200 million), autovacuum worker was launched to prevent wraparound. The following is a snapshot of pg_stat_activity for that time:
When we observe the query output and the graph, we can see that the autovacuum started at the time MaximumUsedTransactionIds reached 200 million (around 12:22 UTC; this was expected so as to prevent transaction ID wraparound). During the same time, we observed the following in postgresql.log:
The preceding code shows autovacuum running and having to act on 5.9 million dead tuples in the table. The warning about wraparound problems is because of the script generating the dead tuples, and advancing the transaction IDs. As time passed, autovacuum finally completed cleaning up the dead tuples:
Autovacuum had to act on approximately 115 million tuples. This is what we observed on an idle system with only a script running to insert duplicate values. The table here was pretty simple, with only two columns and two live rows. For bigger production tables, which realistically have more columns and more data, it could be much worse. Let’s now see how to avoid this by using INSERT..ON CONFLICT.
Duplicate key with INSERT..ON CONFLICT
We modified the same script as in the previous section to include the ON CONFLICT DO NOTHING clause:
We ran the script on the instance in the following steps:
The preceding testing shows that if we use INSERT..ON CONFLICT, the transaction IDs aren’t consumed. The following visualization shows the MaximumUsedTransactionIds metric.

There is still one more benefit to examine by using this clause: storage space.
Storage space considerations
In the case of the normal insert, the dead tuples that are generated result in unnecessary space consumption. Even in our small test workload, we were able to quickly end up in a storage full situation. If this happens in a production system, a scale storage is required.
Duplicate key with regular inserts
As discussed earlier, the tuples are inserted into the heap and checked if they are valid as per the constraint. If it fails, it’s marked as deleted. We can observe the impact on the FreeStorageSpace metric.
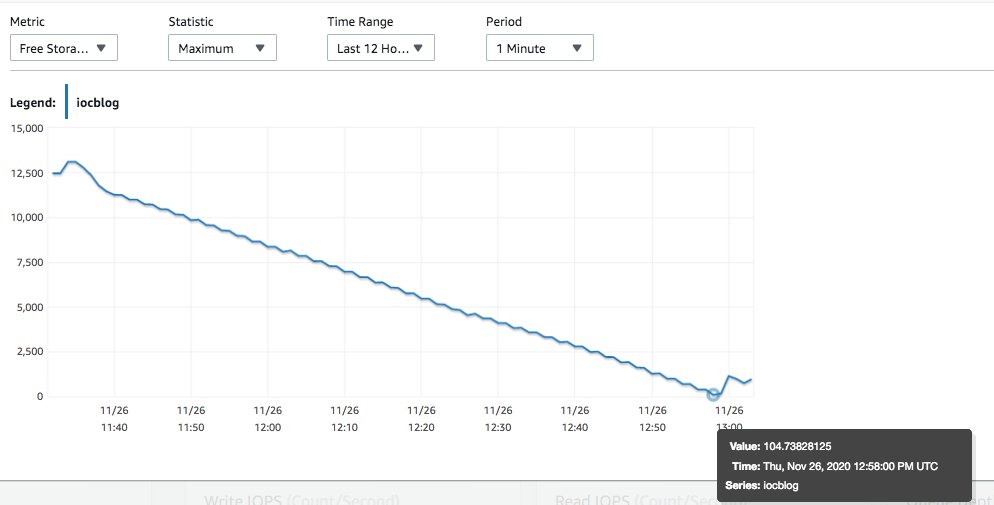
FreeStorageSpace went down all the way to a few MBs because these dead rows consume disk space. We used the following queries to monitor the script, they show that while there are only two visible tuples, space is consumed by the dead rows.
In our small instance, we went into Storage-full state during our script execution.

Duplicate key with INSERT..ON CONFLICT
For comparison, when we ran the script using INSERT..ON CONFLICT, there was absolutely no drop in storage. This is because the transaction is prechecked and the tuple isn’t inserted in the table. With no dead tuples generated, no space is taken up by them, and the instance doesn’t run out of storage space due to duplicate inserts.

Summary
Let’s recap each of the considerations we discussed in the previous sections.
| .. | Regular INSERT | INSERT..ON CONFLICT DO NOTHING |
| Bloat considerations | Dead tuples generated for each conflicting tuples inserted in the relation. | Pre-check before inserting into the heap ensures no duplicates are inserted. Therefore, no dead tuples are generated. |
| Transaction ID considerations | Each failed insert causes the transaction to cancel, which causes consumption of 1 transaction ID. If too many duplicate values are inserted, this can spike up quickly. | The transaction can be backed out and not canceled in the case of a duplicate, and therefore, a transaction ID is not consumed. |
| Autovacuum Impact | As transaction IDs increase, autovacuum to prevent wraparound is triggered, consuming resources to clean up the dead rows. | No dead tuples, no transaction ID consumption, no autovacuum to prevent wraparound is triggered. |
| FreeStorageSpace considerations | The dead tuples also cause storage consumption. | No dead tuples generated, so no extra space is consumed. |
In this post, we showed you some of the issues that duplicate key violations can cause in a PostgreSQL database. They can cause wasted disk storage, high transaction ID usage and unnecessary Autovacuum work.
We offered an alternative approach using the “INSERT..ON CONFLICT“ clause which avoid these problems. It is recommended to use this alternative if you are constantly observing high volumes of the “duplicate key violates unique constraint” error in your logs. You might need to make some application code changes while using this option to see whether the INSERT succeeded or failed. This can not be determined by the error anymore (as there will be none generated) but by checking the number of rows affected with the insert query.
If you have any questions, let us know in the comments section.
About the Authors
 Divya Sharma is a Database Specialist Solutions architect at AWS, focusing on RDS/Aurora PostgreSQL. She has helped multiple enterprise customers move their databases to AWS, providing assistance on PostgreSQL performance and best practices.
Divya Sharma is a Database Specialist Solutions architect at AWS, focusing on RDS/Aurora PostgreSQL. She has helped multiple enterprise customers move their databases to AWS, providing assistance on PostgreSQL performance and best practices.
 Shawn McCoy is a Senior Database Engineer for RDS & Aurora PostgreSQL. After being an Oracle DBA for many years he became one of the founding engineers for the launch of RDS PostgreSQL in 2013. Since then he has been improving the service to help customers succeed and scale their applications.
Shawn McCoy is a Senior Database Engineer for RDS & Aurora PostgreSQL. After being an Oracle DBA for many years he became one of the founding engineers for the launch of RDS PostgreSQL in 2013. Since then he has been improving the service to help customers succeed and scale their applications.