AWS Database Blog
Level Up Your Games with Amazon Aurora
Dhruv Thukral and Yahav Biran are solutions architects at Amazon Web Services.
Amazon Aurora is a relational database that combines the speed and reliability of high-end commercial databases with the simplicity and cost-effectiveness of open-source databases. Amazon Aurora offers two types of modes: provisioned and serverless. AWS gaming customers that use Aurora have typically observed higher throughput compared to standard installations of MySQL.
X.D. Network, one of the largest mobile gaming companies in Shanghai, uses Aurora for operating their MMORPG, Ragnarok Online. They process 25,000 write transactions/second with minimal administration and keep their read latency under 35 ms providing excellent player experience. Grani and Gumi, a top Japanese social gaming publisher, use Aurora with MySQL compatibility for their web-based games platform. Grani and Gumi are able to keep write transaction latency within the range of 15–22 ms and read transaction latency in the range of 5.5 ms. Zynga’s microservice architecture is also powered by Amazon Aurora. They use Aurora for their player identity, messaging, and payments microservice platform. With Aurora, Zynga is able to simplify its live operations and scale to billions of requests per day.
Amazon Aurora’s combination of performance, operational simplicity, and cost effectiveness has even allowed companies like Double-Down Interactive to achieve better cost effectiveness with Aurora MySQL compared to MySQL community edition. For example, the higher performance of Aurora means that you can use fewer or smaller instances than with MySQL. If you’re running a sharded MySQL environment, which we see many gaming companies do, you can potentially save money by switching to Aurora. At the same time, you can also get two to three times better performance, as you can see later in this blog post.
Finally, with Aurora Serverless you can let the service scale its capacity for you based on a policy you set. Aurora Serverless works well when the database workload is predictable, but requires that you adjust capacity manually based on the expected workload. We highlight the key advantages of the Serverless option following.
In this post, we discuss how Amazon Aurora offerings, provisioned and serverless, can help you build a reliable and scalable database tier using a sample reference architecture for a mobile game. We also highlight experiences from gaming customers who have already migrated their existing databases to Amazon Aurora.
The value of choosing the right database
When architecting an application for scale, one key factor is the database tier. The database tier is especially important for games, which are extremely read- and write-heavy. Game data is continuously updated and read as the player progresses through levels, defeats enemies, receives in-game currency, changes inventory, unlocks upgrades, and completes achievements. Each event must be written to your database layer so it isn’t lost. Losing this progress within the game can lead to negatively trending Twitter posts and being paged in the middle of the night.
Developers of games and web apps often use an open-source relational database such as MySQL for their database layer because it is familiar. The querying flexibility and the ACID properties for transactional aspects of the game logic are very appealing for many developers. The traditional way of scaling this tier, especially when using MySQL, is by sharding. In some cases, scaling is also done by splitting the reads off to a read replica. Although this approach enables developers to keep adding shards, maintaining such an infrastructure comes with overhead. For example, what if you run out of storage in a shard, or what happens if your read replica goes down? Or what happens if you lose an entire shard and the data with it when it’s unexpected?
Why do game developers feel Aurora is the right choice for them?
- Drop-in MySQL compatibility: MySQL compatibility enables you to integrate with Aurora and get all its benefits without changing their applications. You just need to change the endpoint in your database configuration within the application. You can keep using the same code and tools that you are used to today.
- Not having to make decisions on how much storage to allocate to the database: Deciding how much storage to allocate to your database, especially for production workloads is one decision that game developers (or developers and DBAs in general) don’t want to make. Allocate too little, and you end up running out of space when you need it the most, requiring you to put your game in maintenance mode while you upgrade. Allocate too much, and you are wasting money.With Aurora, data is stored in a cluster volume, which is a single, virtual volume that uses solid-state disk (SSD) drives. A cluster volume consists of copies of the data across multiple Availability Zones in a single AWS Region. Aurora cluster volumes automatically grow as the amount of data in your database increases. An Aurora cluster volume can grow to a maximum size of 64 tebibytes (TiB). Table size is limited to the size of the cluster volume. That is, the maximum table size for a table in an Aurora DB cluster is 64 TiB. Even though an Aurora cluster volume can grow to up to 64 TiB, you are only charged for the space that you use in an Aurora cluster volume. You can start with a volume as small as 10 GB.
- Unique Read Replicas: Aurora’s Read Replicas use the same underlying cluster volume as that of the primary. This approach allows for a reduced replication lag even when the replicas are launched in different Availability Zones. Aurora supports up to 15 replicas with minimal impact on the performance of write operations. In contrast, MySQL supports up to 5 replicas, which can impact the performance of write operations and exhibit some replication lag. Additionally, Aurora automatically uses its replicas as failover targets with no data loss. Because these replicas share the same underlying storage as the primary, they lag behind the primary by only tens of milliseconds, making the performance nearly synchronous.
- Amazon manages your database for you: Game developers are focused on building great games, not on dealing with maintenance and operations. Amazon Aurora is a managed service that includes operational support and high availability across multiple data centers. You don’t have to worry about installing software or dealing with hardware failures. Aurora Serverless takes this simplicity one step further. It eliminates the complexity of managing DB instances. It seamlessly scales compute and memory capacity as needed, with no disruption to client connections. Finally, with Aurora Serverless you pay for only the database resources that you consume, on a per-second basis.
- Performance boost: Gaming customers have reported up to two to three times the performance by moving to Amazon Aurora when compared to existing open-source databases. Grani, a top Japanese social gaming publisher, moved their web-based games platform from MySQL to Aurora and shared the following results. The first graph shows their average web transaction response time in their legacy system, broken down by the different layers in their overall stack.

In the preceding setup, Grani was running MySQL on an r3.4xl instance type in Amazon RDS with Multi-AZ enabled. Their total database response times were in the range of 15–22 ms., with a total response time of about 50 ms. The graph following shows their results after moving to Amazon Aurora.

They migrated to a similar r3.4xl node with one master and one Read Replica. They were able to get their overall response time down to 5.5 ms. Following is another graph that provides a full picture of the overall response times for their platform database before and after migration.

Getting started quickly with Amazon Aurora
As we updated our old sample reference architecture for running mobile and online games on AWS, we realized the importance of recommending Aurora for our gaming customers. The updated reference architecture for asynchronous online games, shown following, demonstrates how to use AWS to build a services backend for large-scale mobile and online games.
These workloads are a natural fit for running on AWS, due to unexpected traffic patterns and highly demanding request rates. AWS provides the flexibility to start small and scale your architecture in response to players. Scale up and scale down your architecture to make sure that you are only paying for resources that are driving the best experience for your game. Use our managed services for popular caching and database technologies, and work with an architecture that captures the best practices of some of the largest games running on AWS today.
Amazon Aurora Serverless option
With a provisioned model for Amazon Aurora, you choose an instance size and create Aurora Replicas to increase read throughput. If the workload changes, you can modify the instance size or change the number of Aurora Replicas. This model works well when the database workload is predictable, but requires that capacity adjustments are based on the expected workload.
However, in some environments, workloads can be intermittent and unpredictable. There can be periods of heavy traffic that might last only a few minutes or hours, and long periods of light activity, or inactivity. Examples of such workload characteristics include game backend services with intermittent game events like authentication, messaging, and payments as referenced by the Zynga use case. Other good uses cases for the above are ad hoc reporting databases, development, and testing environments. In such cases, it is difficult to configure the right capacity needed by the business, resulting in higher costs when provisioned capacity is not used.
In contrast, the Serverless option enables you to specify Aurora Capacity Units (ACUs). Each ACU is a combination of processing and memory capacity. Database storage automatically scales from 10 GiB to 64 TiB, the same as storage in a standard Aurora DB cluster.
Serverless has rules that are based on upper and lower thresholds for CPU utilization and connections. Aurora Serverless manages the warm pool of resources in an AWS Region to minimize scaling time. When Aurora Serverless adds new resources to the Aurora DB cluster, it uses the proxy fleet to switch active client connections to the new resources. At any specific time, you are only charged for the ACUs that are being actively used in your Aurora DB cluster.
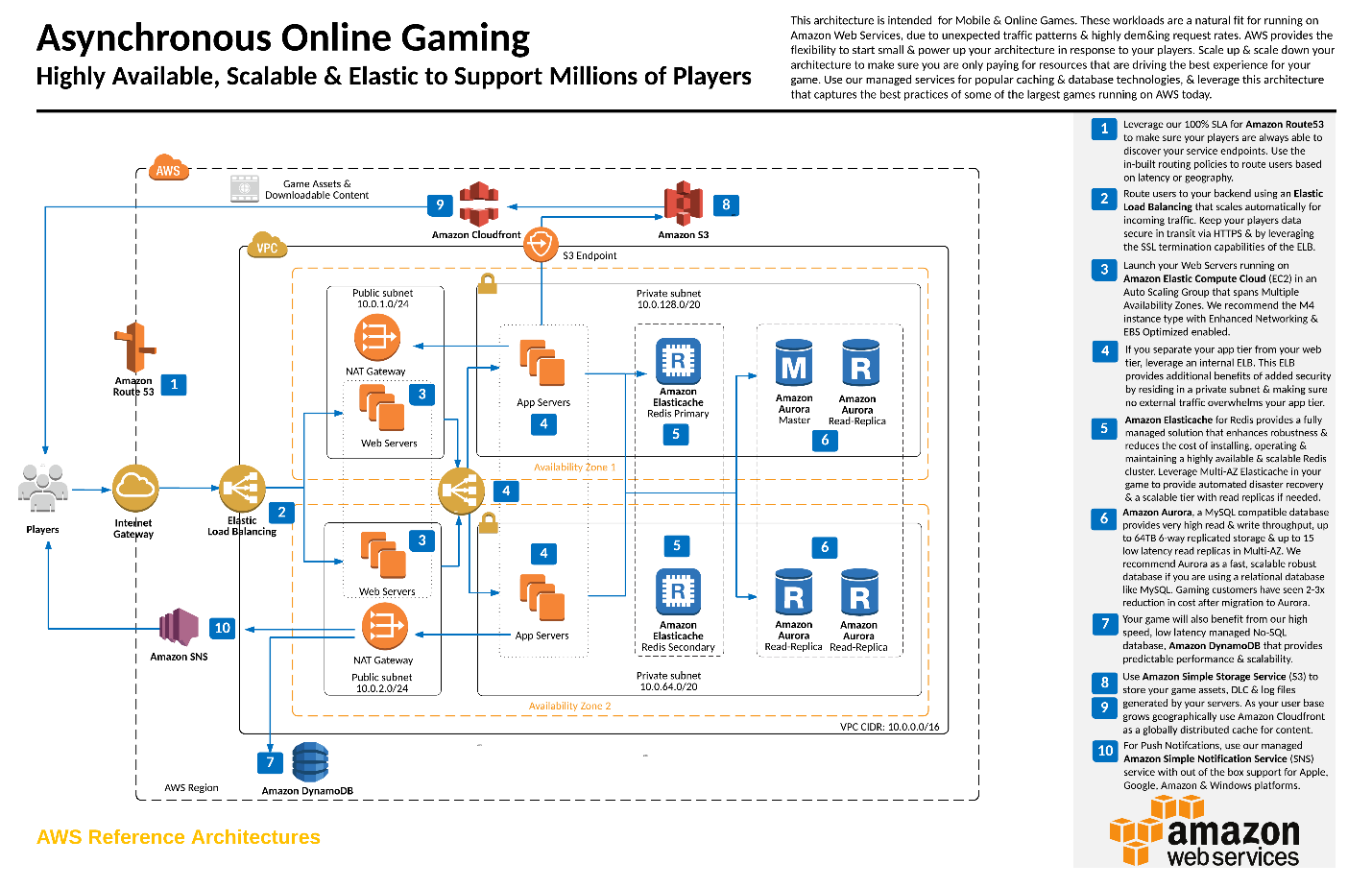
The preceding architecture recommends that you deploy Aurora in multiple Availability Zones with a recommended starting node size of R3.2XL and three Read Replicas. We recommend this setup because we assume that your game has more reads than writes and can benefit from the additional Read Replicas. You also benefit from the inherent high availability that comes when you use Aurora Replicas as a failover target.
Keep a few things in mind when referencing the preceding architecture:
- Shard configurations: The preceding architecture is a single-shard configuration with one master and three replicas. If your environment ends up with more than a single shard, you can change the preceding configuration to a single Aurora master and two Read Replicas per shard. This approach helps balance cost and high availability. It also enables you to still have a master and a Read Replica in case of a failover event.
- Retry logic: When a primary instance fails, an Aurora Replica is promoted to the primary instance. There is a brief interruption, during which read and write requests made to the primary instance fail with an exception. Make sure that your game handles this scenario gracefully and has built-in retry logic, or proper exception handling within your game clients.
- Connection pooling: Suppose that you use popular connection pooling libraries like c3p0, HikariCP, Apache DBCP, and so on, and prefer to support a large connection pool. If so, keep in mind that Aurora’s thread pooling works differently from MySQL’s. With features like multiplexed connections and the ability to handle over 5000 concurrent sessions, Aurora’s thread pool is much more scalable than MySQL’s thread pool. As always, we recommend that you test your workload to make sure that you are getting the required performance for your game.
Resources
This AWS Database Blog post goes into details on how you can simplify your sharded MySQL environment on Aurora: Reduce Resource Consumption by Consolidating Your Sharded System into Aurora.
You can also look into the details of how Aurora handles scaling of its storage tier in this Database Blog post: Introducing the Aurora Storage Engine.
For a comprehensive overview about Aurora Serverless, see Using Amazon Aurora Serverless in the Aurora documentation.