AWS Database Blog
Scaling Amazon DocumentDB (with MongoDB compatibility), Part 1: Scaling reads
Amazon DocumentDB (with MongoDB compatibility) is a fast, scalable, highly available, fully managed document database service that supports MongoDB workloads. With Amazon DocumentDB, you can run the same application code and use the same drivers and tools you use with MongoDB. This post shows you how the modern, cloud-native database architecture of Amazon DocumentDB allows you to scale your cluster’s read throughput faster and more flexibly than traditional architectures. The post also provides recommendations for connecting to and reading from your Amazon DocumentDB cluster.
Amazon DocumentDB cloud-native architecture
Unlike traditional monolithic databases, the Amazon DocumentDB cloud-native architecture separates storage and compute. An Amazon DocumentDB cluster consists of a distributed storage volume and one or more compute instances that read and write data from the storage volume. The following diagram illustrates an Amazon DocumentDB cluster with one primary instance and two replica instances.

The compute instances handle your requests, and cluster storage volume provides durability by maintaining six copies of all data (two copies in each of the three Availability Zones). The architecture provides a single primary instance for read and write operations and up to 15 read replicas for read operations, scaling to millions of reads per second.
Because Amazon DocumentDB instances aren’t data-bearing, you can add and remove new instances to a cluster quickly because adding a new instance doesn’t require copying data. You can add a new replica instance or change an existing instance’s sizes in just a few minutes, regardless of the amount of data stored. New instances are typically provisioned in 8–10 minutes, and are immediately ready to process queries when active. The fully-managed approach of Amazon DocumentDB also takes advantage of this architecture to quickly replace instances in the event of hardware failure, which results in a much quicker recovery than traditional database architectures.
Amazon DocumentDB endpoints
Amazon DocumentDB supports three types of endpoints:
- Cluster endpoint – Connects to your cluster’s current primary instance; you can use it for read and write operations. This is usually the recommended endpoint when connecting to your cluster.
- Reader endpoint – Load balances read-only connections across all available replicas in your cluster. You shouldn’t use the reader endpoint because your database driver does a better job of balancing reads across your cluster.
- Instance endpoint – Connects to a specific instance within your cluster. This is useful for specialized workloads that only want to impact a specific replica instance.
The following diagram illustrates the architecture of these endpoints.
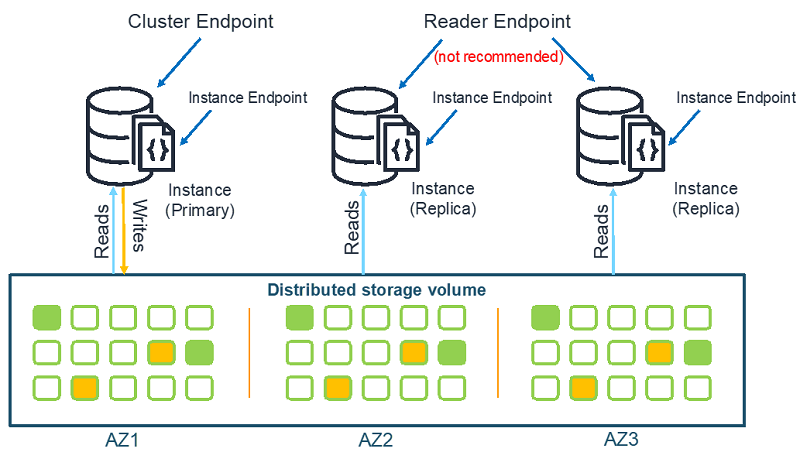
Because an instance’s role as primary or replica can change due to a failover event, your applications should never assume that a particular instance endpoint is the primary instance.
You should connect to your Amazon DocumentDB cluster using the cluster endpoint and as a replica set so your driver can discover cluster topology changes automatically.
Connecting as a replica set
Amazon DocumentDB supports emulation of MongoDB replica sets, so your drivers can automatically discover the topology of the cluster (for example, how many instances are in the cluster and which one is the primary and the replicas) and the ongoing changes in this topology, and distribute reads according to your preference. To demonstrate this capability, this post walks you through using a Python program from an Amazon EC2 instance to connect to the Amazon DocumentDB cluster as a replica set, change the cluster’s topology, and verify the change in the program’s output.
You can only access Amazon DocumentDB clusters within their VPC, so for this post, use an EC2 instance in the same VPC as your cluster. If you want to access the cluster from outside of the VPC, you need to take additional steps to enable connectivity through means like VPC peering, VPN, or SSH tunneling. For more information, see Connecting to an Amazon DocumentDB Cluster from Outside an Amazon VPC.
For this use case, you use an Amazon DocumentDB cluster created with the default settings, including two instances deployed across multiple AZs. For more information about creating a cluster, see Getting Started with Amazon DocumentDB. You also use an EC2 instance in the same VPC as your cluster. For more information about creating an EC2 instance, see Getting Started with Amazon EC2.
After you create and log in to your EC2 instance, you can run the following Python program to connect to the cluster as a replica set and print the cluster members one time every minute:
To connect as a replica set, the script uses the cluster endpoint and includes the replica set name rs0 in the connection string. If you receive connection errors, you can check your security group’s settings to make sure you allowed the proper connectivity from your EC2 instance to your cluster. For more information, see Troubleshooting Amazon DocumentDB.
You can run your script and see that it has connected to the cluster and identified the primary instance and one replica shown as SECONDARY. This is demonstrated in the following output:
You can now add an additional secondary replica to your cluster and verify that your client automatically discovers the replica when it becomes active. To add the replica to a cluster, complete the following steps:
- On the Amazon DocumentDB console, select your cluster.
- From the Actions drop-down menu, choose Add instances.

- For Instance identifier, enter the instance name.
- For Instance class, enter the appropriate class. This post uses the default option, r5.large.
- For Promotion tier, leave at the default No preference.
- Choose Create.

The newly added replica instance is usually available in fewer than 10 minutes. Your program’s output now shows that it has automatically discovered the new replica, as shown in the following output:
As you can see from this use case, when you scale your instances out/in (by adding or removing read replicas), or up/down (by resizing the instances), the MongoDB driver automatically detects these changes in the cluster’s topology without you having to do any additional work.
Read preference
When you connect to Amazon DocumentDB as a replica set, you can specify the read preference in your connection string to determine how you want your application to route read requests from your application across the instances in your cluster.
There are five read preference options to choose from:
- primary – Specifying a
primaryread preference helps make sure that all reads are routed to the cluster’s primary instance. If the primary instance is unavailable, the read operation fails. - primaryPreferred – Specifying a
primaryPreferredread preference routes reads to the primary instance under normal operation. If there is a primary failover, the client routes requests to a replica. - secondary – Specifying a
secondaryread preference makes sure that reads are only routed to a replica, never the primary instance. If there are no replica instances in a cluster, the read request fails. - secondaryPreferred – Specifying a
secondaryPreferredread preference makes sure that reads are routed to a read replica when one or more replicas are active. If there are no active replica instances in a cluster, the read request is routed to the primary instance. - nearest – Specifying a
nearestread preference routes reads based solely on the measured latency between the client and all instances in the Amazon DocumentDB cluster.
For more information, see Amazon DocumentDB Read Preferences.
The preceding code example used readPreference=secondaryPreferred. Specifying secondaryPreferred read preference when connecting as a replica set is the recommended approach with Amazon DocumentDB. For more information about best practices, see Best Practices for Amazon DocumentDB.
By using secondaryPreferred read preference, the client automatically routes read queries to your replicas and write queries to your primary instance. This is a better use of your cluster resources because it allows the primary instance to handle a higher volume of writes. If the cluster doesn’t have a read replica (for example, a single node cluster, or a cluster with single read replica that temporarily has issues), the client automatically falls back to the primary instance for read traffic when using the secondaryPreferred read preference.
Reads from Amazon DocumentDB replicas are eventually consistent. There are use cases in which an application needs to have read-after-write consistency, which can only be served from the primary instance in Amazon DocumentDB. In these use cases, you can create two client connection pools in your application: one for writes and reads that need read-after-write consistency (readPreference=primary) and another for eventually consistent reads (readPreference=secondaryPreferred). Alternatively, you can overwrite the read preference for a given collection. For more information, see Multiple Connection Pools.
Conclusion
This post showed how the Amazon DocumentDB unique architecture allows you to scale cluster throughput by routing read traffic to the replica instances. To take full advantage of such an approach, you should use the built-in abilities in your MongoDB driver for connecting to the cluster as a replica set and set the suitable read preference.
About the Authors

Leonid Koren is a Solutions Architect with Amazon Web Services. He works with AWS customers to help them architect secure, resilient, scalable and high performance applications in the cloud.

Jeff Duffy is a Sr NoSQL Specialist Solutions Architect at Amazon Web Services.