AWS DevOps & Developer Productivity Blog
Chaos experiments on Amazon RDS using AWS Fault Injection Simulator
Performing controlled chaos experiments on your Amazon Relational Database Service (RDS) database instances and validating the application behavior is essential to making sure that your application stack is resilient. How does the application behave when there is a database failover? Will the connection pooling solution or tools being used gracefully connect after a database failover is successful? Will there be a cascading failure if the database node gets rebooted for a few seconds? These are some of the fundamental questions that you should consider when evaluating the resiliency of your database stack. Chaos engineering is a way to effectively answer these questions.
Traditionally, database failure conditions, such as a failover or a node reboot, are often triggered using a script or 3rd party tools. However, at scale, these external dependencies often become a bottleneck and are hard to maintain and manage. Scripts and 3rd party tools can fail when called, whereas a web service is highly available. The scripts and 3rd party tools also tend to require elevated permissions to work, which is a management overhead and insecure from a least privilege access model perspective. This is where AWS Fault Injection Simulator (FIS) comes to the rescue.
AWS Fault Injection Simulator (AWS FIS) is a fully managed service for running fault injection experiments on AWS that makes it easier to improve an application’s performance, observability, and resiliency. Fault injection experiments are used in chaos engineering, which is the practice of stressing an application in testing or production environments by creating disruptive events, such as a sudden increase in CPU or memory consumption, database failover and observing how the system responds, and implementing improvements.
We can define the key phases of chaos engineering as identifying the steady state of the workload, defining a hypothesis, running the experiment, verifying the experiment results and making necessary improvements based on the experiment results. These phases will confirm that you are injecting failures in a controlled environment through well-planned experiments in order to build confidence in the workloads and tools we are using to withstand turbulent conditions.
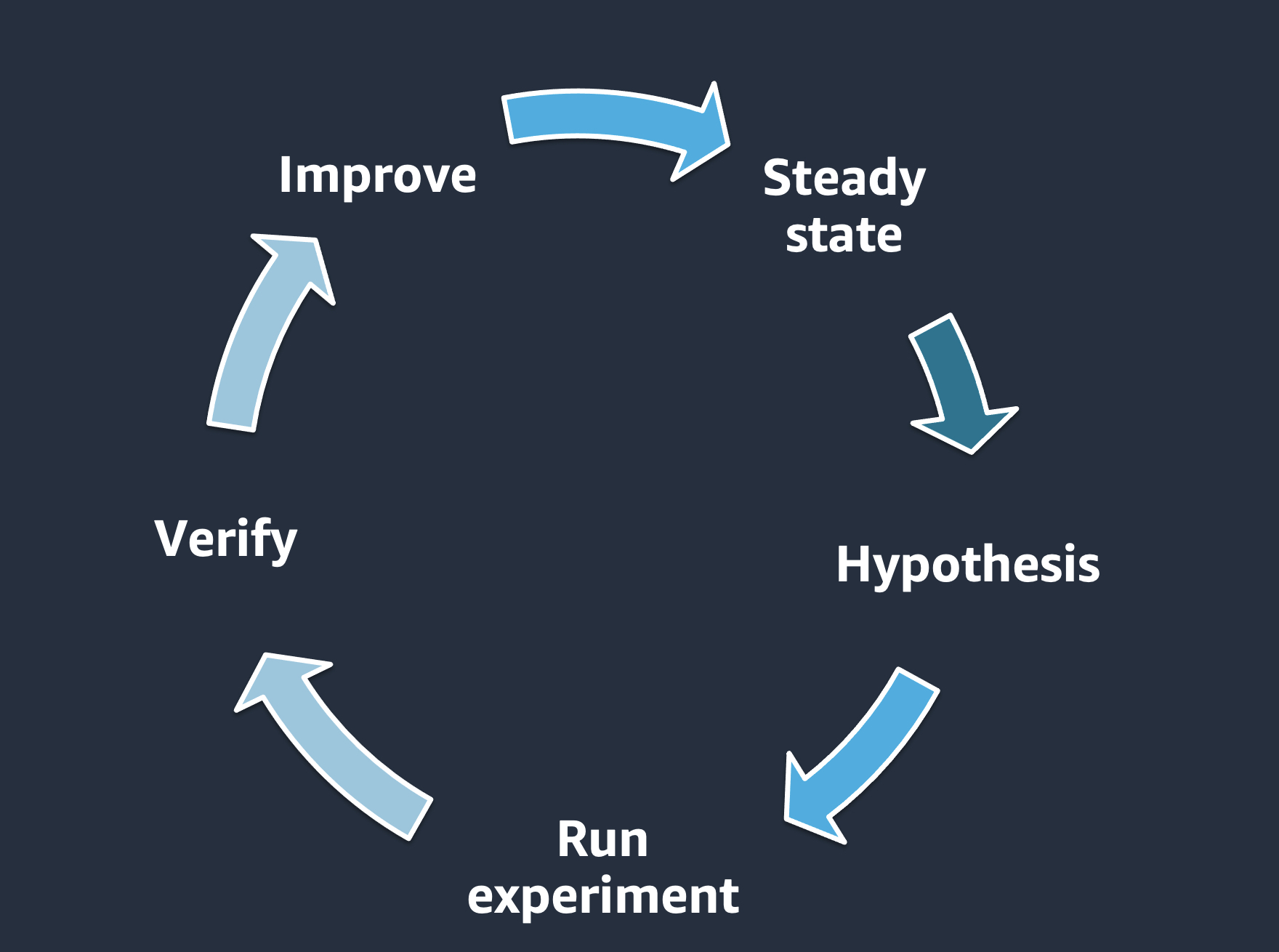
Example—
- Baseline: we have a managed database with a replica and automatic failover enabled.
- Hypothesis: failure of a single database instance / replica may slow down a few requests but will not adversely affect our application.
- Run experiment: trigger a DB failover.
- Verify: confirm/dis-confirm the hypothesis by looking at KPIs for the application (e.g., via CloudWatch metric/alarm).
Methodology and Walkthrough
Let’s look at how you can configure AWS FIS to perform failure conditions for your RDS database instances. For this walkthrough, we’ll look at injecting a cluster failover for Amazon Aurora PostgreSQL. You can leverage an existing Aurora PostgreSQL cluster or you can launch a new cluster by following the steps in the Create an Aurora PostgreSQL DB Cluster documentation.
Step 1: Select the Aurora Cluster.
The Aurora PostgreSQL instance that we’ll use for this walkthrough is provisioned in us-east-1 (N. Virginia), and it’s a cluster with two instances. There is one writer instance and another reader instance (Aurora replica). The cluster is named chaostest, the writer instance is named chaostest-instance-1, and the reader is named chaostest-intance-1-us-east-1a.
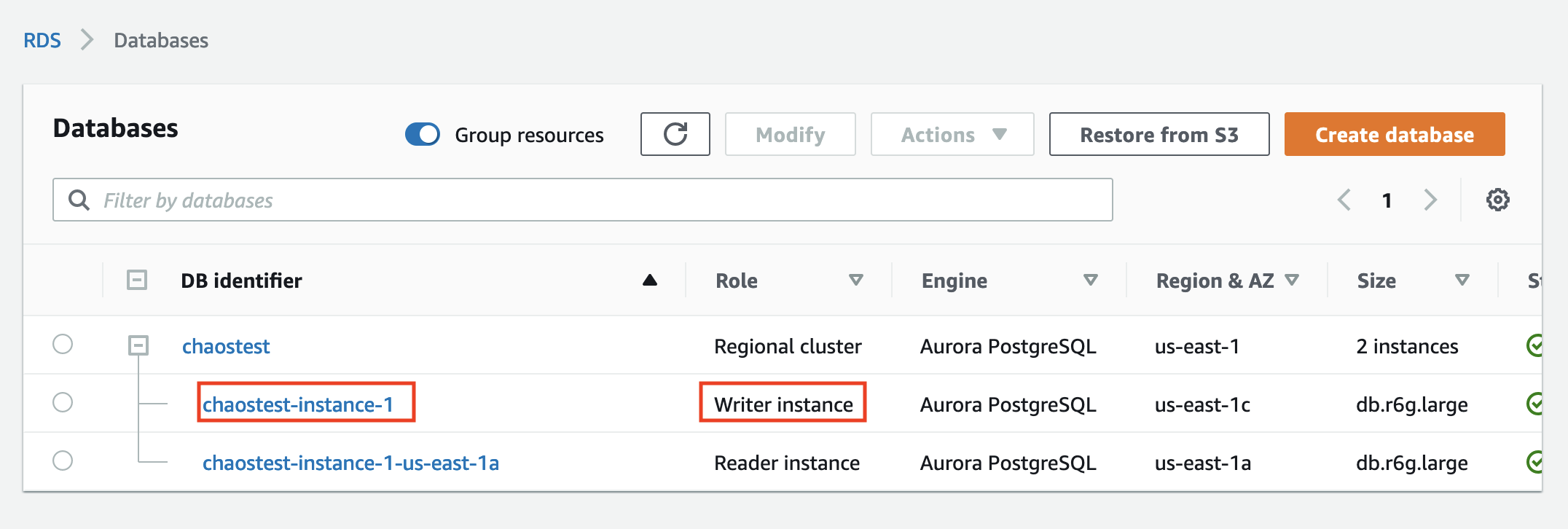
The goal is to simulate a failover for this Aurora PostgreSQL cluster so that the existing chaostest-intance-1-us-east-1a reader instance will switch roles and then be promoted as the writer, and the existing chaostest-instance-1 will become the reader.
Step 2: Navigate to the AWS FIS console.
We will now navigate to the AWS FIS console to create an experiment template. Select Create experiment template.

Step 3: Complete the AWS FIS template pre-requisites.
Enter a Description, Name, and select the AWS IAM Role for the experiment template.
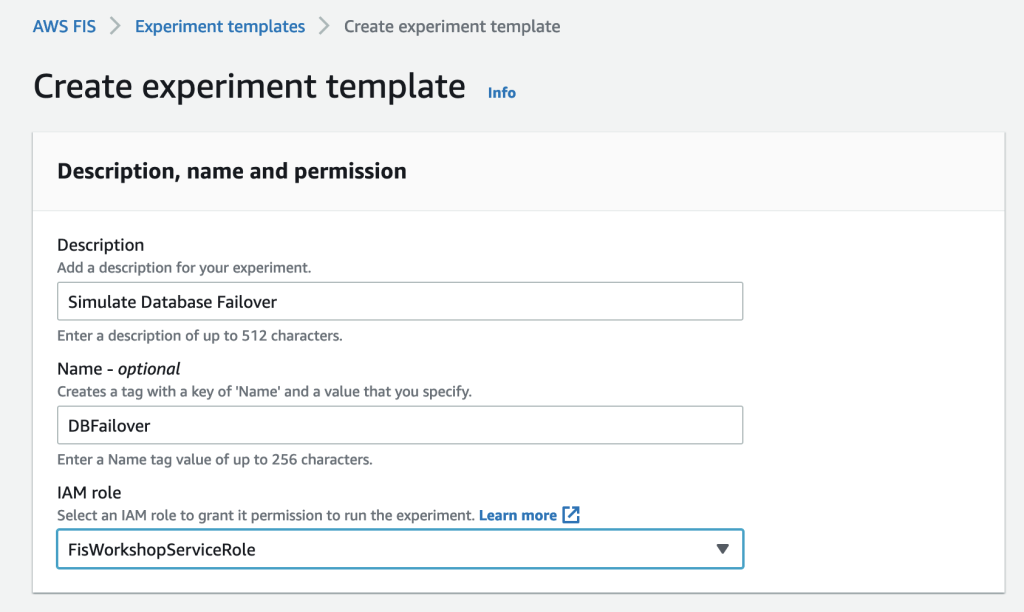
The IAM role selected above was pre-created. To use AWS FIS, you must create an IAM role that grants AWS FIS the permissions required so that the service can run experiments on your behalf. The role follows the least privileged model and includes permissions to act on your database clusters like trigger a failover. AWS FIS only uses the permissions that have been delegated explicitly for the role. To learn more about how to create an IAM role with the required permissions for AWS FIS, refer to the FIS documentation.
Step 4: Navigate to the Actions, Target, Stop Condition section of the template.
The next key section of AWS FIS is Action, Target, and Stop Condition.

Action—An action is an activity that AWS FIS performs on an AWS resource during an experiment. AWS FIS provides a set of pre-configured actions based on the AWS resource type. Each Action runs for a specified duration during an experiment, or until you stop the experiment. An action can run sequentially or in parallel.
For our experiment, the Action will be aws:rds:failover-db-cluster.
Target—A target is one or more AWS resources on which AWS FIS performs an action during an experiment. You can choose specific resources or select a group of resources based on specific criteria, such as tags or state.
For our experiment, the target will be the chaostest Aurora PostgreSQL cluster.
Stop Condition—AWS FIS provides the controls and guardrails that you need to run experiments safely on your AWS workloads. A stop condition is a mechanism to stop an experiment if it reaches a threshold that you define as an Amazon CloudWatch alarm. If a stop condition is triggered while the experiment is running, then AWS FIS stops the experiment.
For our experiment, we won’t be defining a stop condition. This is because this simple experiment contains only one action. Stop conditions are especially useful for experiments with a series of actions, to prevent them from continuing if something goes wrong.
Step 5: Configure Action.
Now, let’s configure the Action and Target for our experiment template. Under the Actions section, we will select Add action to get the New action window.
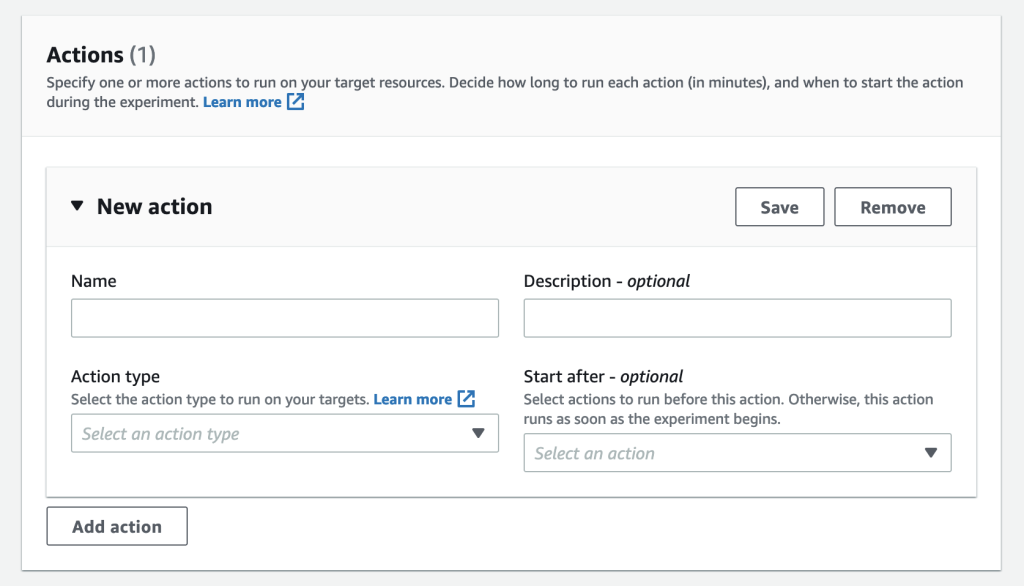
Enter a Name, a Description, and select Action type aws:rds:failover-db-cluster. Start after is an optional setting. This setting allows you to specify an action that should precede the one we are currently configuring.
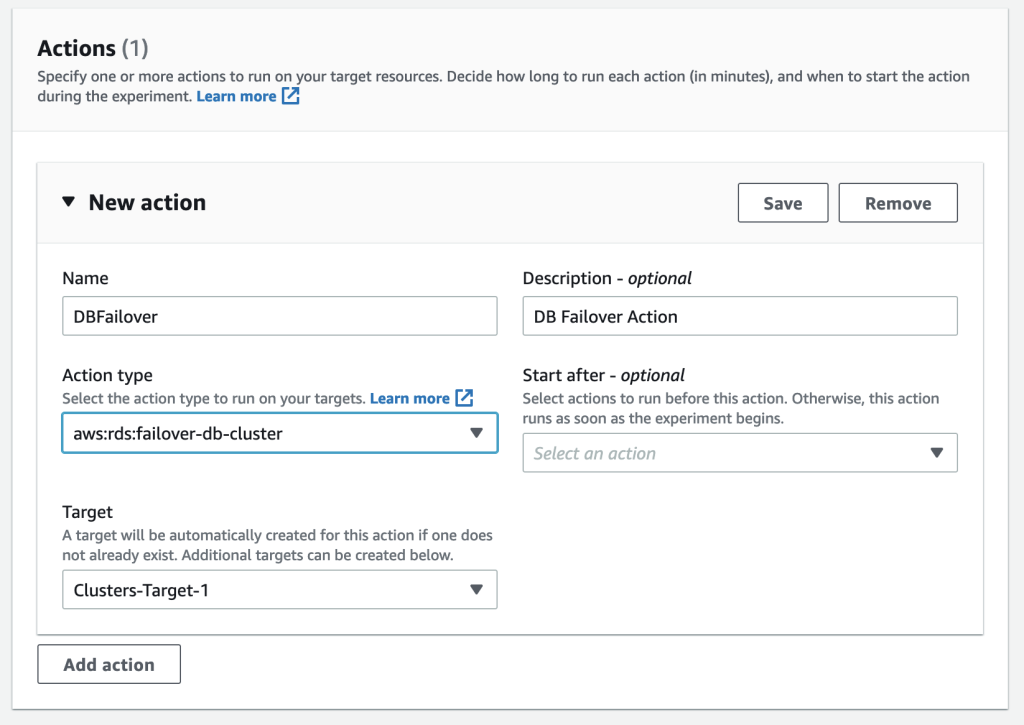
Step 6: Configure Target.
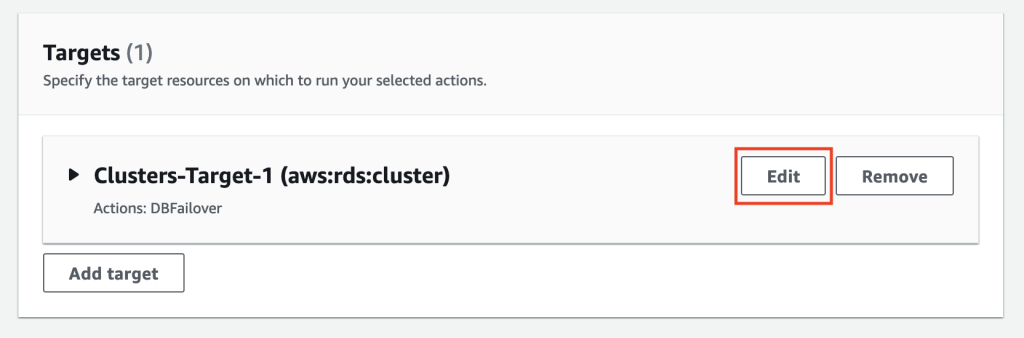
Note that a Target has been automatically created with the name Clusters-Target-1. Select Save to save the action.
Next, you will edit the Clusters-Target-1 target to select the target, i.e., the Aurora PostgreSQL cluster.
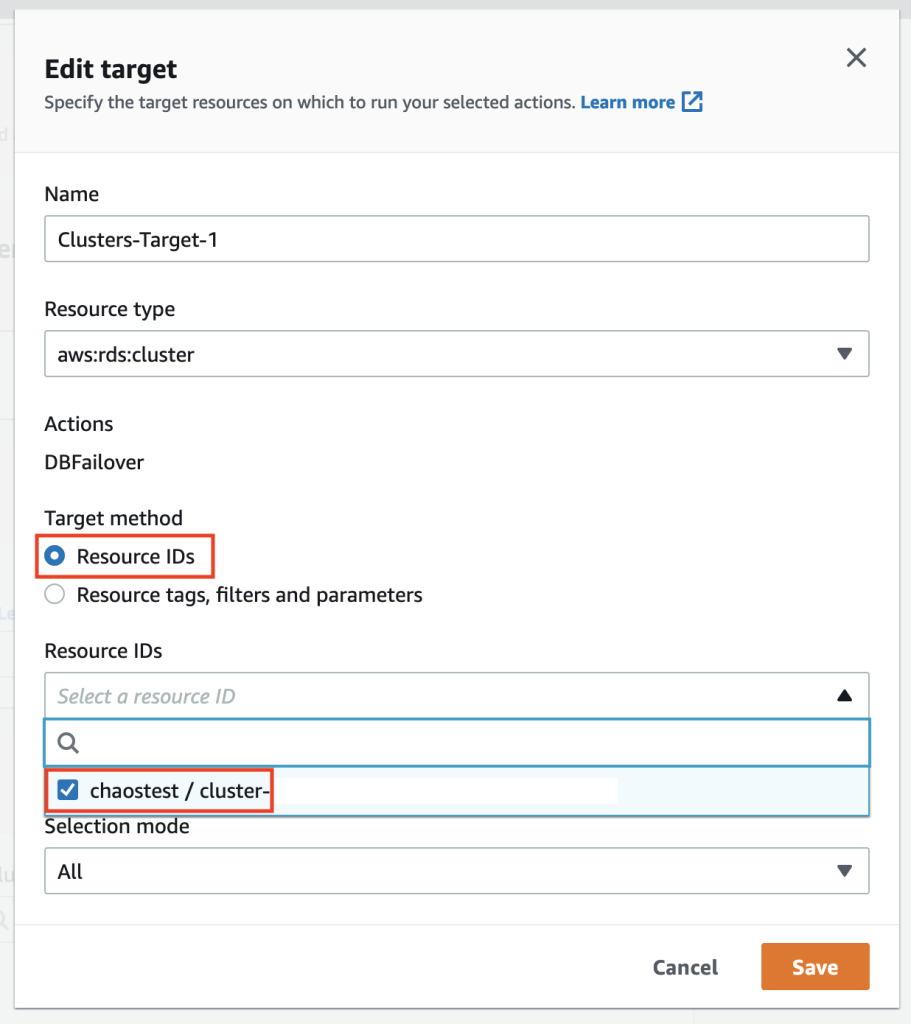
Select Target method as Resource IDs, and select the chaostest cluster. If you are interested to select a group of resources, then select Resource tags, filters and parameters option.
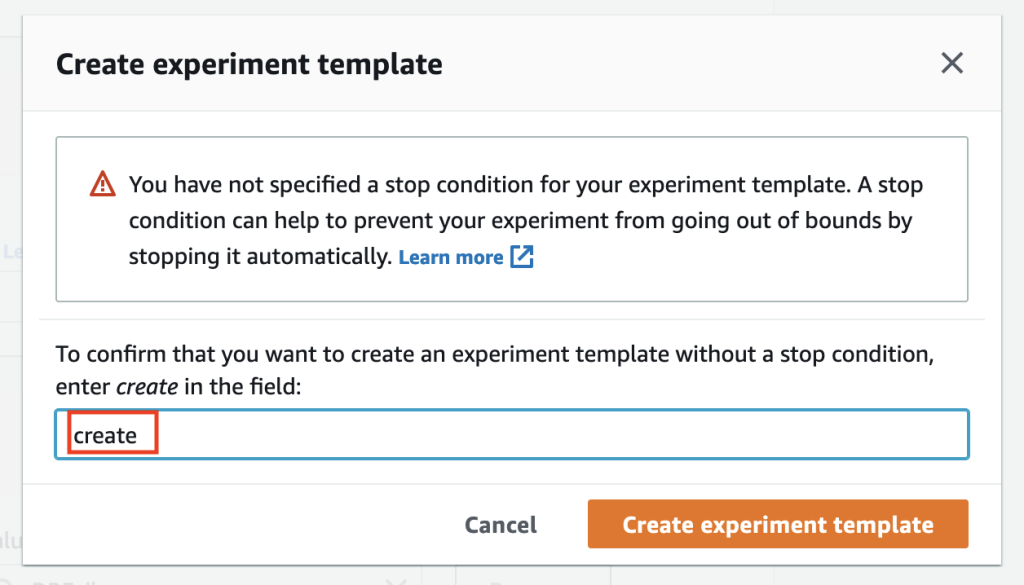
Step 7: Create the experiment template to complete this stage.
We will wrap up the process by selecting the create experiment template.

We will get a warning stating that a stop condition isn’t defined. We’ll enter create in the provided field to create the template.
We will get a success message if the entries are correct and the template will be successfully created.

Step 8: Verify the Aurora Cluster.
Before we run the experiment, let’s double-check the chaostest Aurora Cluster to confirm which instance is the writer and which is the reader.
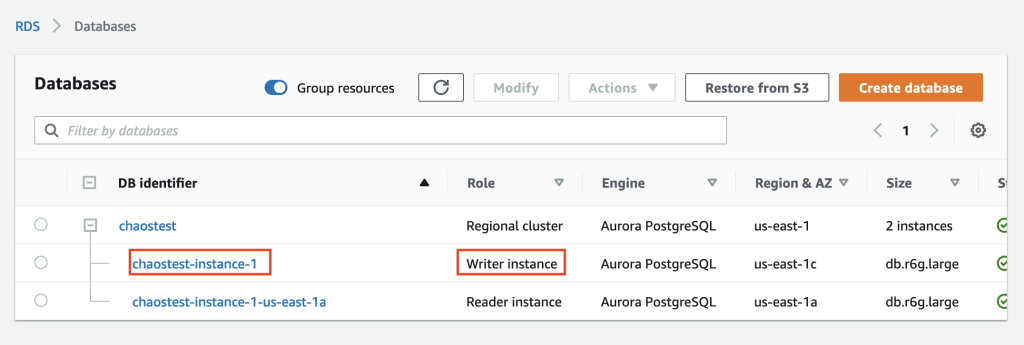
We confirmed that chaostest-instance-1 is the writer and chaostest-instance-1-us-east-1a is the reader.
Step 9: Run the AWS FIS experiment.
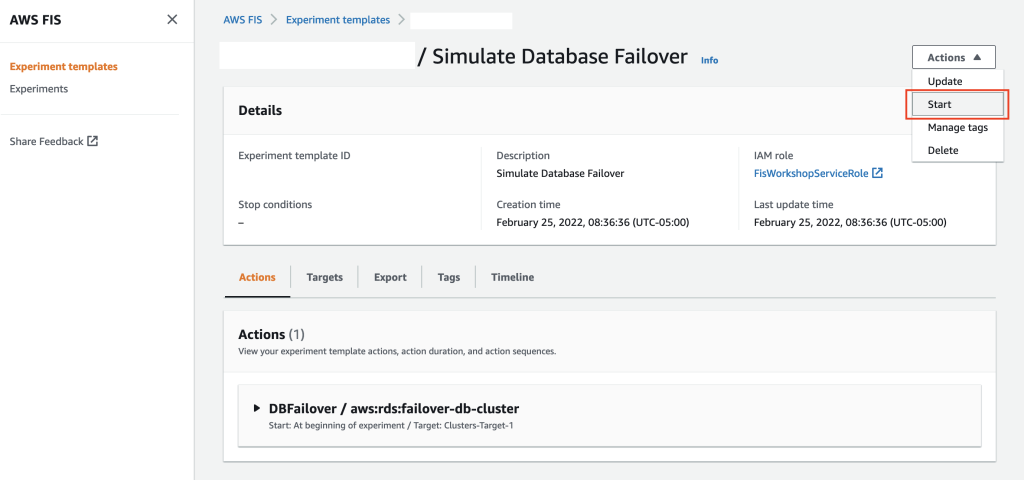
Now we’ll run the FIS experiment. Select Actions, and then select Start for the experiment template.
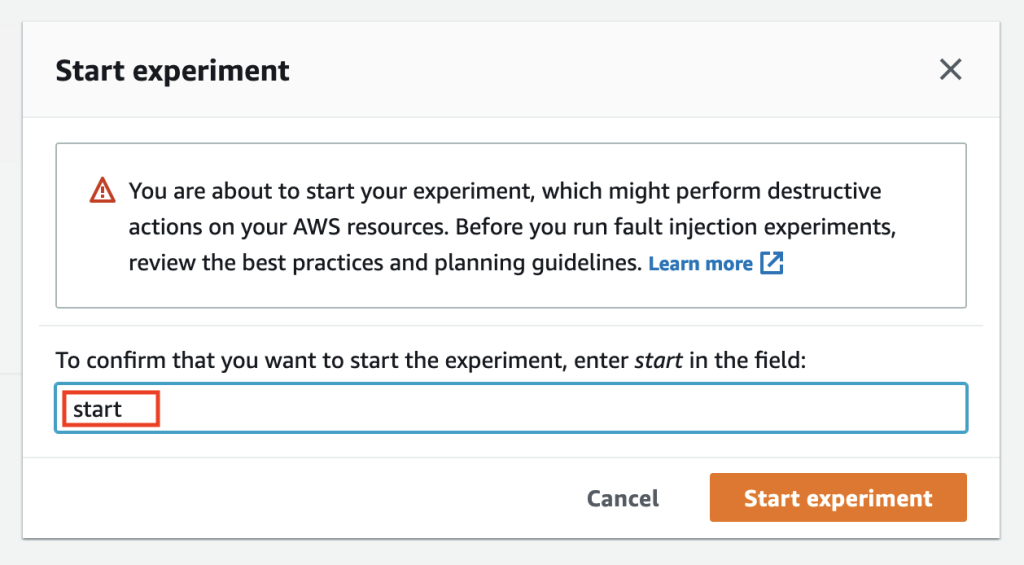
Select Start experiment and you’ll get another warning to confirm if you really want to start this experiment. Confirm by entering start say Start experiment.
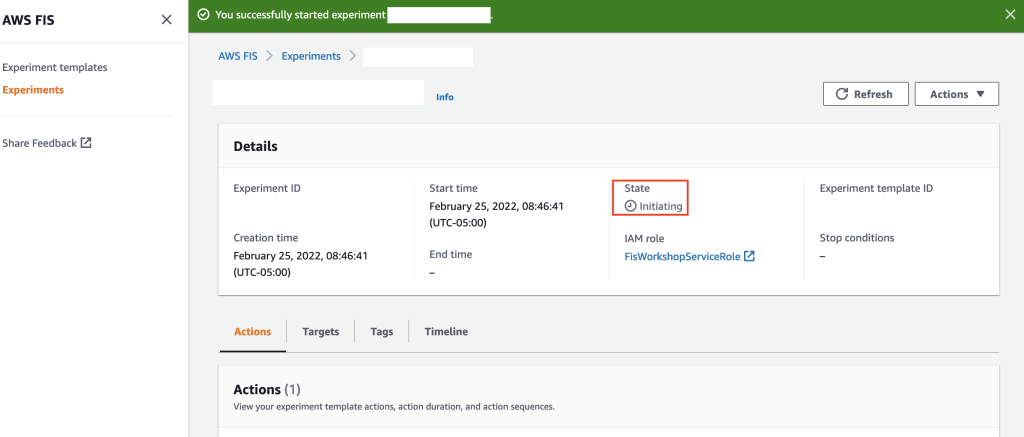
Step 10: Observe the various stages of the experiment.
The experiment will be in initiating, running and will eventually be in completed states.

Step 11: Verify the Aurora Cluster to confirm failover.
Now let’s look at the chaostest Aurora PostgreSQL cluster to check the state. Note that a failover was indeed triggered by FIS and chaostest-instance-1-us-east-1a is the newly promoted writer and chaostest-instance-1 is the reader now.

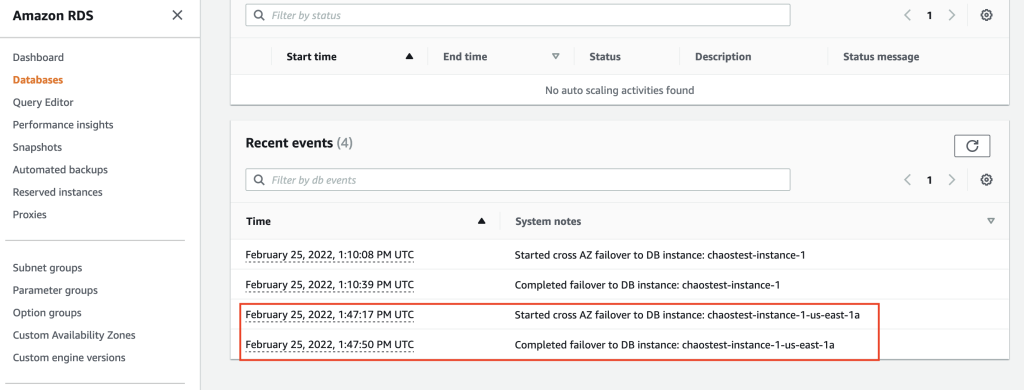
Step 12: Verify the Aurora Cluster logs.
We can also confirm the failover action by looking at the Logs and events section of the Aurora Cluster.
Clean up
If you created a new Aurora PostgreSQL cluster for this walkthrough, then you can terminate the cluster to optimize the costs by following the steps in the Deleting an Aurora DB cluster documentation.
You can also delete the AWS FIS experiment template by following the steps in the Delete an experiment template documentation.
Further Reading
You can refer to the AWS FIS documentation to learn more about the service. If you want to know more about chaos engineering, check out the AWS re:Invent session Testing resiliency using chaos engineering and The Chaos Engineering Collection. Finally, check out the FIS Workshop for a deeper dive into using FIS, this GitHub repo for additional example experiments, and how you can work with AWS FIS using the AWS Cloud Development Kit (AWS CDK).
Conclusion
In this walkthrough, you learned how you can leverage AWS FIS to inject failures into your RDS Instances. To get started with AWS Fault Injection Service for Amazon RDS, refer to the service documentation.