AWS for Games Blog
How Dream11 uses an in-house scaling platform to scale resources on AWS for efficiency and reliability
With over 190+ million users, Dream11 is the world’s largest fantasy sports platform. Their site offers fantasy cricket, football, kabaddi, basketball, hockey, volleyball, handball, rugby, American football & baseball. Dream11 is the flagship brand of Dream Sports, India’s leading Sports Technology company. They have partnerships with several national and international sports bodies and cricketers.
About Scaling in AWS
Scaling on AWS refers to the process of adjusting the resources allocated to an application to meet demand. This can be done by adding more resources, which is scaling out, or by optimizing existing resource, which is scaling in. AWS provides a range of tools and services that allow organizations to scale their applications dynamically. There are various factors that organizations must consider when scaling, such as cost, performance, availability, and complexity.
Horizontal scaling, also known as scaling out, involves adding more resources to an application, such as more servers or instances to handle increased traffic or workload. AWS provides tools such as AWS EC2 Auto Scaling and Elastic Load Balancing to automate horizontal scaling and distribute traffic across multiple resources.
Vertical scaling, also known as scale-up, involves adding more hardware to an existing machine so that you run the same workload on better specs. For example, if a server requires more processing power, vertically scaling the device would mean upgrading its CPU.
Several methods exist for managing scalability within web applications. For instance, manual scaling involves directly inputting changes through a console, command line interface (CLI), or infrastructure as code (IaC) deployment. Another option is scheduled scaling, where predefined automation scripts activate at specific times or dates, making adjustments as necessary. Dynamic scaling utilizes user-defined policies to monitor application usage and adapt to any shifts in demand. Finally, predictive scaling uses advanced analytics like machine learning algorithms to make educated estimations regarding potential surges in activity, enabling administrators to proactively reallocate resources before they become taxed.
Dynamic scaling refers to the automatic adjustment of computing resources based on specified targets or predetermined limits, helping manage infrastructure optimization and cost reduction efficiently. AWS makes this possible via various methods, such as target tracking and step scaling. With target tracking, users set a target value tied to metrics like CPU usage, and the system adds/removes resources to reach the desired level. Meanwhile, step scaling involves creating policies with action triggers linked to particular threshold breaches. Features include Auto Scaling group policies and cooldown periods to fine-tune dynamic scaling performance.
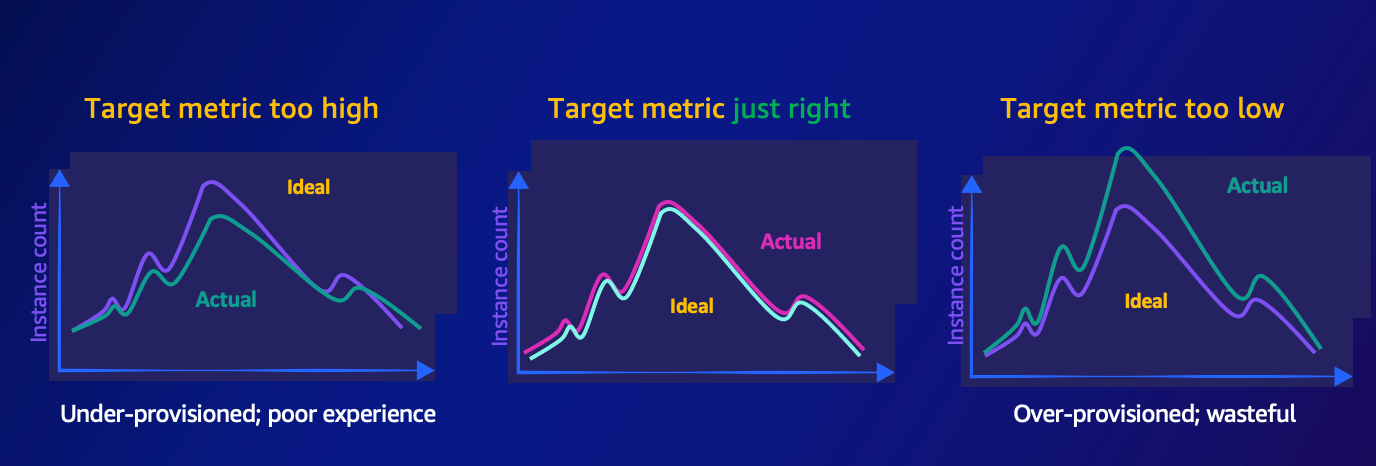
Dynamic scaling on AWS relies heavily on specifying a suitable target metric to determine the optimal quantity of resources needed to support your application’s demands. This important decision impacts the overall efficiency and cost effectiveness of your cloud infrastructure. The selected target metric is then utilized within target tracking scaling policies to continuously monitor and regulate the appropriate resource amount. Through careful consideration of relevant factors for your unique workload requirements, choosing the most effective target metric can significantly enhance your cloud environment’s functionality and cost management.
Now in their own words, Dream11 will describe their experience implementing a scaling solution with AWS.
How do we scale at Dream11 ?
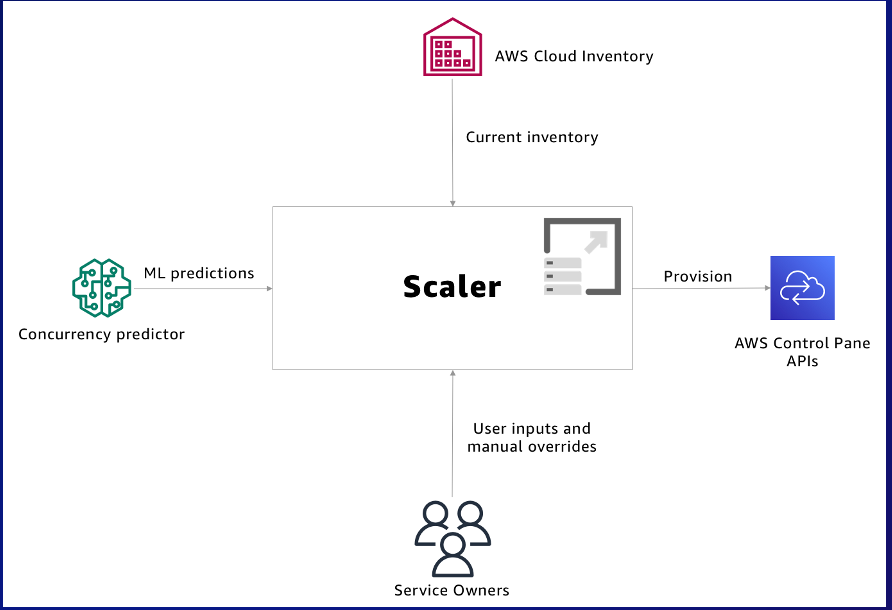
To overcome the complexities of managing traffic peaks on its platform, Dream11 developed its own tool called Scaler. As the company deals with rapid changes in user engagement, we identified the need for a better way to scale infrastructure compared to traditional AWS solutions. We had to contend with multiple phases of activity related to major sporting events, each with varying levels of concurrency among our users. Predicting user traffic proved difficult due to various influential factors such as game popularity, user interests, weather, and so on. While reactive scaling strategies helped mitigate potential issues, they often fell short given the long times associated with EC2 instance setup, software initialization, and ELB checks. Additionally, proactive capacity redistribution introduces further delay in restoring balanced backend systems. Therefore, the creation of Scaler provided a customizable answer tailored to the nuances of Dream11’s business model and user habits.
One of the significant challenges faced by Dream11 is dealing with the surge in user traffic during live sports events. Users engage in numerous activities on the platform such as creating and managing their teams, tracking scores, checking standings, and claiming rewards. These actions result in a vast number of requests made to backend services, requiring substantial computational resources.
To manage this situation effectively, Dream11 uses an auto scaling mechanism named “Scaler” to monitor vital metrics such as concurrent user count and request rates, and then allocates resources appropriately. The following diagram depicts how the peaks in user activity during a cricket match are addressed. Blue arrows represent trigger events leading to heightened activity, whereas red arrows indicate the manner in which the platform’s auto scaling mechanism adapts to the rise in demand.
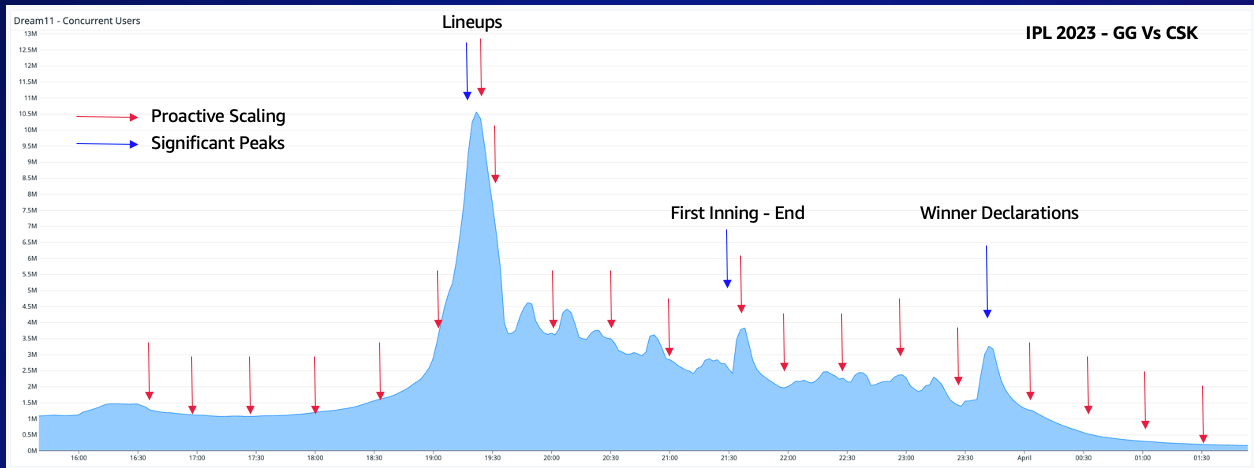
For instance, let’s consider a fixture for a contest during the Indian Premier League (IPL) that begins at 07:30 PM IST. Massive ‘Competition Days’ are hosted prior to the match, allowing users to sign up and modify their virtual sport teams until the first ball of the live match is thrown. During this timeframe, there will be a spike in participation caused by roster announcements, known as a ‘Lineup Event’. Once users enroll in a tournament, they remain engaged on the Dream11 application to review their team standings and player stats. Exhilarating plays increase user interest; for instance, a batsman hitting boundaries or a bowler taking wickets prompt additional app visitors, resulting in further resource requirements. After the opening innings and conclusion of live match, another upsurge occurs when users wish to examine their total scores and the winners.
Dream11 has successfully addressed issues pertaining to concurrency by employing several strategies, including caching mechanisms, database sharding, splitting reads/writes via different APIs, replicating data across availability-zone, parallel processing, asynchronous message queuing systems, and containerization. In summary, Dream11’s success in handling high concurrency emanates from embracing the right technology stack while leveraging effective techniques for database modeling and cache utilization.
Concurrency patterns are crucial to ensure efficient scaling in microservice architectures. While understanding those patterns is essential, it’s equally important to assess the expected concurrency to Requests Per Minute (RPM) ratio for each microservice in order to scale them correctly. The next section details a recently encountered situation that illustrates this concept.
Converting Concurrency numbers to RPM
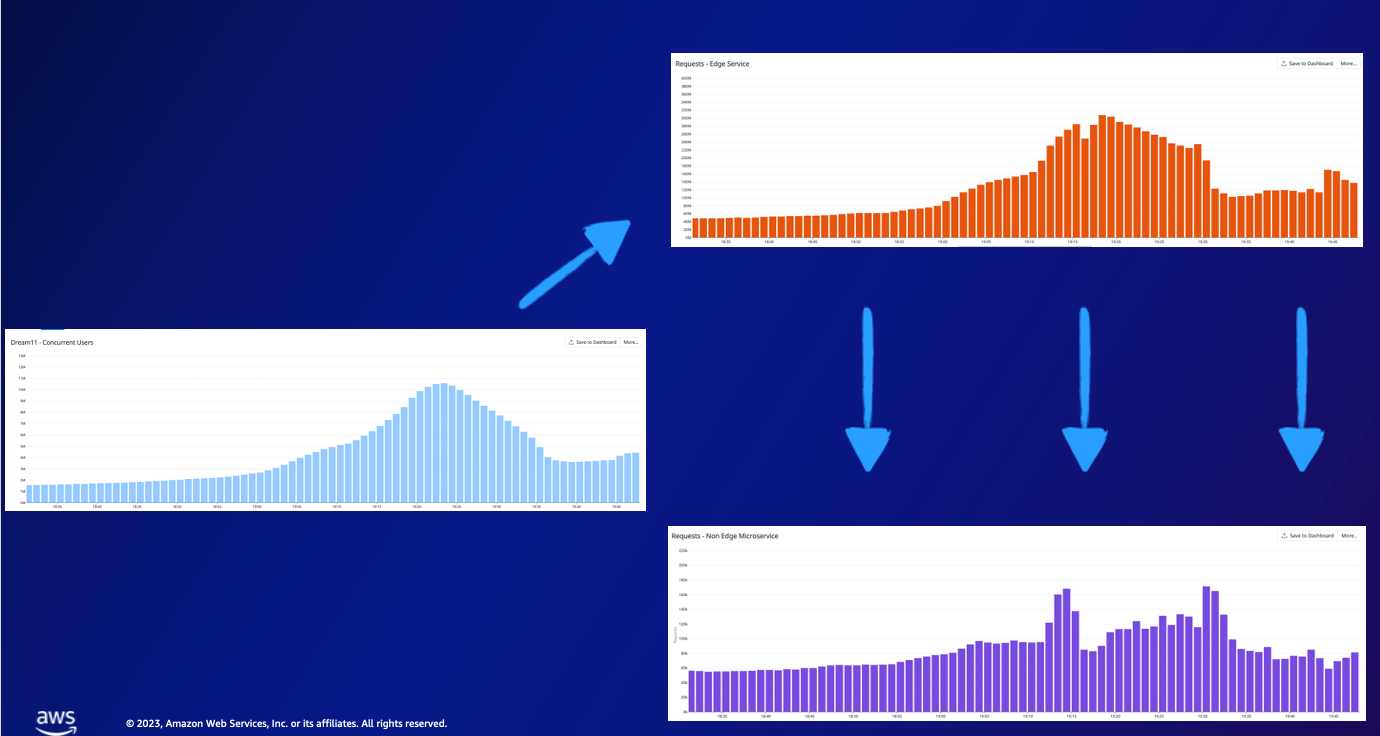
The bar chart demonstrates a sharp hike in concurrency levels, particularly within an Edge Service. As seen here, despite having comparable loads, the Edge Service experiences roughly 245 million requests per minute compared to approximately 69 million requests witnessed by a Non-Edge Service. To achieve optimal efficiency, each microservice needs individualized attention even if they face the same level of concurrency. This is why scalability becomes so vital.
Introducing Scaler – Dream11’s one-stop solution for managing capacity during over 100+ sporting events every day. Developed by our dedicated Capacity and Optimization team, Scaler streamlines the process of ensuring adequate resources during peak traffic times, leaving more room for innovation and creativity elsewhere.
By analyzing historical data, the platform correlates from history the expected concurrent accesses and corresponding Requests per Second (RPS) demands for each microservice. With these insights, system preemptively prepares infrastructural provisions tailored to meet those demands. All this happens without intervention from service owners or developers. The result? Uninterrupted functionality under extreme usage scenarios.
Fortunately, this is only the beginning. Scaler offers several remarkable features to help service owners optimize capacity management. Users simply define their desired capacity requirements and allow Scaler to handle the rest. An advanced verification mechanism then checks whether the scheduled capacities align with actual resource allocations, ensuring that services receive the correct amount of resources required. If unexpected changes occur, Scaler notifies service owners immediately, empowering quick decision-making and mitigation of potential downtime risks.
For teams looking for an easy yet robust method to schedule and allocate capacity, Scaler offers a convenient mode accessible through simple configuration files. Simply configure according to anticipated concurrent load and RPM correlation profiles, and leave the rest up to Scaler. What sets apart this convenience layer from traditional methods is Scaler’s capability to monitor concurrency versus allocated capacity using AWS control plane API call, which guarantees better visibility into overall performance metrics.
Finally, Scaler boasts an impressive alert feature that informs service owners whenever forecasted concurrency predictions diverge significantly from actual values. Should such situations arise, users can also request an override with a single click.
Scaler Use case : Point of view from the users of Scaler
As a Dreamster (an employee of Dream11) and a microservice owner, utilizing Scaler couldn’t be simpler. Here’s a step-by-step breakdown of how we benefit from Scaler’s unique offerings, with examples from the IPL season at Dream11
Preparing for the Pre-IPL Season: To integrate your Microservice with Scaler, head to the scaler portal or take advantage of the available programmatic APIs. Define your RPM to Capacity requirements to establish a baseline for your service’s performance needs during high-traffic periods.
Predicting Traffic before a big game: About five days prior to a big game, a data science model analyzes past performance indicators to forecast an estimated number of users who will access the platform during the game. You can either trust these predictions or input your own estimates, should you possess a clearer picture of user behavior.
Accurate Prediction Two Hours Before Game Time: Just two hours before the live match opener at 7:30 PM IST, an updated data science model predicts around ten million active users across all services –– almost double what was projected earlier. However, instead of panicking, sit back and let Scaler perform its magic. Based on historical usage patterns, Scaler recommends adjustments in incoming RPMs for your particular Microservice. Accept or modify the suggested changes, and Scaler generates a smart scaling plan tailored to your specific needs.
Efficient Resource Allocation: At 6:30 PM, Scaler begins allocating additional resources to support your Microservice based on the proposed scaling schedule. This process involves analyzing the impact of potential updates on other interdependent components within the larger cloud infrastructure, such as DNS configurations, load balancing strategies, and auto scaling groups. By checking for compatibility issues and determining eligibility conditions, Scaler ensures safe and optimized modifications before proceeding. Finally, Scaler communicates directly with AWS via APIs to implement the desired improvements across relevant platforms, including load balancer reconfiguration and ASGs
Scaler Architecture
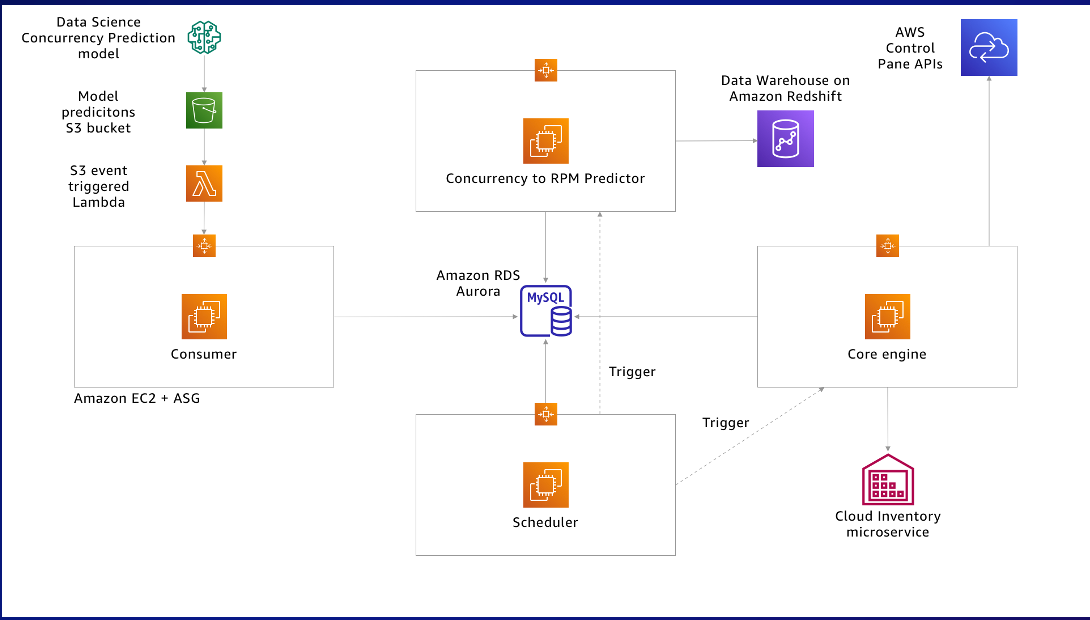
The system in place follows a well-structured approach to provide a seamless experience for users. The predictions from the data science team are received in JSON format and then stored as Amazon Simple Storage Service (Amazon S3) objects. Whenever a new object is added, it triggers an AWS Lambda function that processes the predictions. The Lambda function passes the predictions to our Consumer APIs, which saves them to the Amazon Relational Database Service (Amazon RDS) database before alerting our Scheduling APIs to review the predictions and calculate resource requirements using predefined RPM ladders. This calculation informs our Core Engine, which interacts with the cloud infrastructure management platform to reallocate resources to match demand levels. Before making any changes, the Core Engine verifies if the proposed alterations meet business needs, ensuring a smooth transition at all times. To tackle common load balancer limitations, sharding is implemented to distribute traffic through Amazon Route 53 weightings for optimal performance. By following this detailed process, the fluctuating demand can be effectively addressed while reducing costs, resulting in increased user satisfaction and loyalty.
Cloud Inventory Architecture
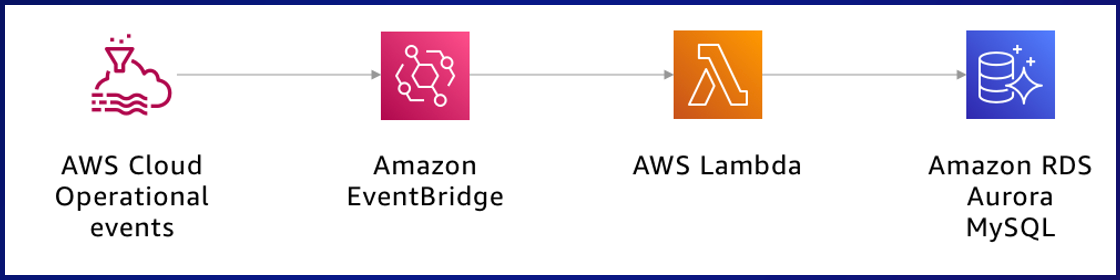
There is one more pivotal component of the highly advanced scaler system – the Cloud Inventory Microservice. It provides a comprehensive and efficient method to manage the vast array of resources interwoven throughout our intricate network of microservices and supporting infrastructure elements.
Confronted by the sheer magnitude and complexity of Dream11’s operation, there was a pressing requirement for a next-generation tool to streamline the platform’s scalable architecture. While initially employing AWS APIs for retrieving resource data at runtime served its purpose, certain limitations related to API rate quota and delayed resilience could potentially hinder performance during large-scale transitions.
To counteract these potential obstacles, a push model was implemented that allowed subscription to resource notifications through Amazon EventBridge after getting guidance from our AWS Technical Account Manager(TAM) and with collaboration of capacity team . Such a setup allowed us to harness the power of operational events emanated directly by AWS services involved in managing our infrastructure, thus circumventing reliance on control panels and minimizing the risk of encountering overuse barriers.
Moreover, frequent reconciliation with the most recent data stored securely within the trustworthy database Amazon RDS empowers swift query responses during critical scaling activities, sparing valuable time and resources alike. Furthermore, future enhancements to this microservice may eventually lead to extended applications beyond mere scaling scenarios into other areas requiring rapid access to relevant data.
About the Concurrency Prediction model
As a progressive organization, Dream11 remains committed to providing an unparalleled user experience by preparing itself for potential surges in demand. To achieve this goal, we leveraged state-of-the-art techniques such as forecasting to estimate the concurrent usage of various app features during major sporting events, including tournaments like the IPL and the FIFA World Cup. By analyzing individual player rankings and statistics during live games, accurate projections of user concurrency were generated that helped in effective allocation of resources and budgets.
The data science experts have developed a sophisticated mathematical model that evaluates the significance of every cricket match using a multi-tier structure. These tiers take into account historical trends to help plan better for current and forthcoming competitions. Additionally, several key factors were considered when estimating concurrent usage, including the number of games at different levels in a particular period, overall active users from preceding hours/days, and typical transaction volumes.
Since Dream11 has a rapidly growing user base, this data needs to be normalized to maintain accuracy across all periods. Consequently, this scenario constitutes a time series problem, so selecting Long Short Term Memory (LSTM), a powerful deep learning algorithm, proved fruitful. The LSTM architecture facilitates straightforward temporal data modeling, makes incorporating external inputs easier, and automatically extracts important features from diverse sources.
With the assistance of appropriate loss functions tailored specifically toward the operational needs, this model was further optimized. Overall, by leveraging countless intricate and dynamic factors affecting user engagement, Scaler consistently provides cutting-edge predictions that cater to customer demands efficiently and proactively.
Key Outcomes achieved by adopting scaler
The implementation of Scaler proved immensely beneficial for Dream11. The process of manually scaling over 700 Active Service Groups (ASGs) and 200 Load Balancers was once a daunting task, causing substantial operational strain. However, since introducing Scaler, Dream11 has successfully automated the entire scaling procedure. This has streamlined operations and drastically improved the scaling times. The time required for scaling decreased from multiple hours down to about five minutes. Additionally, utilizing Scaler allowed us to conduct scalable activities one hour before an event instead of three hours previously, resulting in a massive two hours saved per major match.
RPM ladder-based scaling through Scaler helped scale for precise requirements and reduced costs in comparison to previous methods. Subsequent benefits of Scaler include the ability for users to monitor critical performance indicators and concurrently track growth within their application workloads. Moreover, the self-service functionality provided by Scaler enables department heads to manage scaling processes autonomously, making it both convenient and efficient. Ultimately, Scaler has transformed the way applications are scaled at Dream11, leading to enhanced productivity, lowered expenses, and improved decision-making capabilities.
This blog was authored by:
- Sanket Raut, Principal Technical Account Manager, AWS India
- Vatsal Shah, Sr. Solutions Architect, AWS India
- Ritesh Sharma, Engineering Manager, Performance and Optimization, Dream11
- Eeshan Bembi, SDE Infrastructure Engineering, Dream11