AWS HPC Blog
Install optimized software with Spack configs for AWS ParallelCluster
 With AWS ParallelCluster, you can choose a computing architecture that best matches your HPC application. But, HPC applications are complex. That means they can be challenging to get working well. Spack configurations for AWS ParallelCluster help you install optimized applications on your HPC clusters.
With AWS ParallelCluster, you can choose a computing architecture that best matches your HPC application. But, HPC applications are complex. That means they can be challenging to get working well. Spack configurations for AWS ParallelCluster help you install optimized applications on your HPC clusters.
Today, we’re announcing the availability of Spack configs for AWS ParallelCluster. You can use these configurations to install optimized HPC applications quickly and easily on your AWS-powered HPC clusters.
Background
There are over 500 Amazon EC2 instance types, representing dozens of CPU, memory, storage, and networking options. Finding one that best meets your price/performance target can be a challenge. It can mean exploring a matrix of Amazon EC2 instance types, software versions, and compiler flags. HPC experts regularly spend weeks finding the most performant setup for one architecture. Adding more architectures can take even more time.
A growing number of people and organizations use Spack on their HPC systems. Spack is a language-agnostic package manager for supercomputers. It helps you easily install scientific codes and their dependencies. This is helpful because HPC applications typically have complex dependency chains. Spack has an extensive library of application recipes, many of which are tuned professionally by contributors from across the HPC community. Spack can help you switch compilers and libraries, which is helpful when you’re trying to optimize for specific computing architectures.
Customers have asked us for a straightforward way to optimize their applications for a specific architecture. They’ve also asked for application setups spanning a range of architectures to help make informed decisions between instance types. Hence today’s announcement.
What are Spack Configs for AWS ParallelCluster?
Spack configs for AWS ParallelCluster represent validated best practices developed by the AWS HPC Performance Engineering Team. They contain fixes and general optimizations that can increase the performance of any compiled application on a wide range of architectures. Specifically, they support the hpc6a, hpc6id, c6i, c5n, c6gn, c7g, c7gn, and soon hpc7g Amazon EC2 instance families, which are popular with HPC customers.
Importantly, the Spack configs include optimized dependencies, setups, and compilation flags for several common HPC applications. These currently include OpenFOAM, WRF, MPAS, GROMACS, Quantum Espresso, Devito, and LAMMPS. Our Spack configs improve performance of supported applications by as much as 16.6x over the original, non-tuned versions (Table 1).
| Application | Speed-up |
| OpenFOAM | N/A |
| WRF | 11.9 |
| MPAS | N/A |
| GROMACS | 1.16 |
| Quantum Espresso | 1.53 |
| Devito | N/A |
| LAMMPS | 16.6 |
There are many ways you can benefit from Spack configs for AWS ParallelCluster. If you’re trying to get an application working on AWS ParallelCluster for the first time, the extensive Spack package library can streamline that process. If you’re interested in comparative benchmarks on a variety of architectures, you can directly compare performance of the applications support via Spack configs between AWS ParallelCluster systems. Finally, if you need to run cost-effective production workloads, you can use the Spack configs as a solid foundation for accomplishing that goal.
Using Spack Configs
Spack configs for AWS ParallelCluster are available as open-source contributions to the Spack project and represent another step towards democratization of HPC.
They come with an installer script that runs on the cluster head-node. The script automatically detects the processor architecture and other relevant instance attributes, then downloads and configures Spack appropriately. Once the installer has run, you can begin using Spack commands to install HPC software that’s tailored to your cluster environment.
You can either install Spack automatically on a new cluster using AWS ParallelCluster, or you can run the installer script manually on an existing cluster.
Prerequisites
Before diving into installation, let’s discuss some recommended pre-requisites.
First, it will be helpful for you to have a working knowledge of Spack. We recommend reading through the basics section of the main documentation and the Spack 101 tutorial.
Second, the applications you need should be available in Spack. You can browse the list of over 7000 packages online to find them. However, even if they aren’t, Spack can still be helpful by providing optimized dependencies and compilers that you can use to build them.
Third, you will need to decide on an instance type for your cluster’s head node. The Spack installer script uses the head node CPU architecture to determine what compilers and optimizations to install. Thus, we recommend matching the CPU generation and architecture of your head node to the instances you will run your HPC jobs on. For example, if you’re building a cluster with hpc6id.32xlarge compute nodes, a c6i.xlarge would be an appropriate head node instance type. Be aware that Spack does not support t2, t3, or t4 family instances, which some people use for lightweight head nodes. Choose from c, m, or r instance types instead to avoid this limitation.
Finally, Spack needs a shared directory where you can install it. This helps ensure Spack and the software it can manage are accessible from every node in your cluster. If your cluster will run in a single Availability Zone, we recommend you use Amazon FSx for Lustre for shared storage. For multi-zone clusters, whether you use Amazon EFS or Amazon FSx for Lustre will depend on your workload’s latency requirements. You can learn how to add storage in the AWS ParallelCluster documentation on this topic. It’s easiest using the ParallelCluster UI.
If you’ve added shared storage, the Spack installer script will place Spack in the first shared directory it detects in your cluster configuration. For example, if your first (or only shared storage) is at /shared, Spack will be installed at /shared/spack. If you did not choose to add shared storage, Spack will be installed in the default user’s home directory (for example, /home/ec2-user/spack).
Install On a New Cluster Using AWS ParallelCluster
AWS ParallelCluster UI is the web-based interface for managing AWS ParallelCluster clusters in your AWS account. You can use it to install Spack on a new cluster (Figure 1).
Log into AWS ParallelCluster UI. Then, choose Create Cluster and select Interface to launch a cluster creation wizard. In the Head node section, once you’ve set your instance type and other node attributes, configure a custom action. Under Advanced options, in the Run script on node configured field, add the following URL:
https://raw.githubusercontent.com/spack/spack-configs/main/AWS/parallelcluster/postinstall.shThis will tell ParallelCluster to run the installer script once the head node has launched, but before the cluster is marked ready for use.
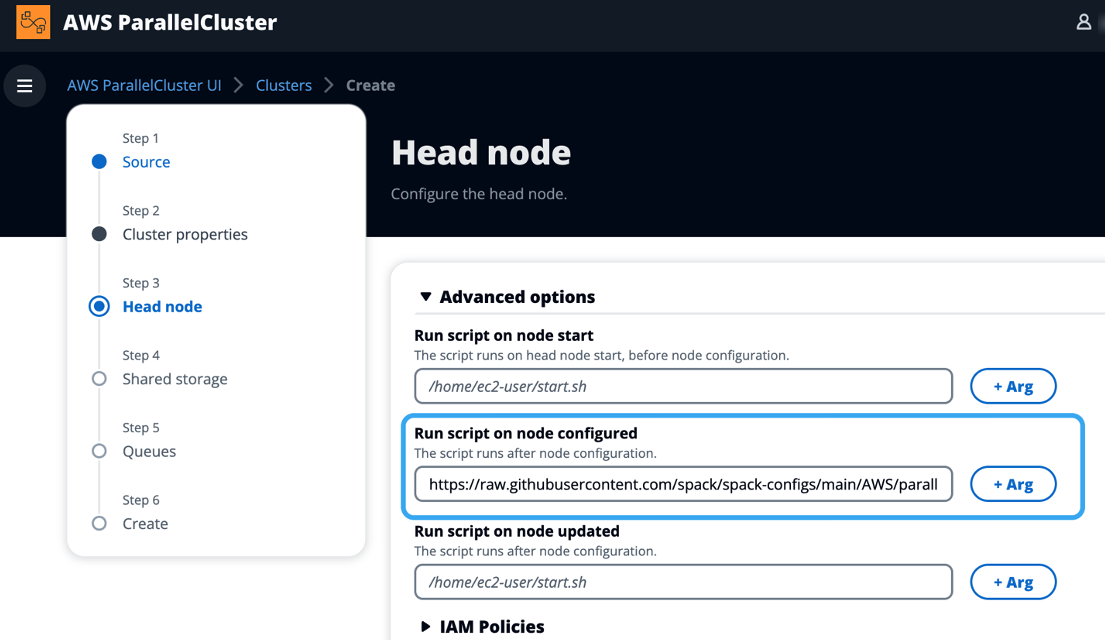
Figure 1: Installing Spack on a cluster with AWS ParallelCluster UI using a post-install script
If you intend to add shared storage as we discussed above, you can accomplish that in the Shared storage section of the creation wizard.
As an alternative to the web UI, you can use the AWS ParallelCluster CLI to install Spack. Put the URL for the install script at HeadNode:CustomActions:OnNodeConfigured:Script in the configuration YAML file and create a new cluster.
Install On an Existing Cluster
If you already have HPC cluster managed by AWS ParallelCluster, you can install Spack directly on it. Using SSH or Amazon System Session Manager (SSM), log into the cluster head node and run the following shell commands. Spack will be installed in a shared directory and integrated with the user environment and the Slurm scheduler.
$ curl -sL -O https://raw.githubusercontent.com/spack/spack-configs/main/AWS/parallelcluster/postinstall.sh
$ sudo bash postinstall.sh
Note that the installer script will return immediately and will not print anything to the screen. That’s ok because it runs in the background, as explained in the next section.
Knowing When Installation Is Complete
The Spack installer script runs as a background task. This is because downloading, configuring, and installing Spack and the relevant compilers for your cluster can take 30 minutes or longer on smaller instance types. If you’re creating a new cluster to install Spack, it’ll be ready to accept connections before Spack finishes installing. If you are installing on an existing cluster, you’ll notice that the install script goes into the background immediately.
How can you tell when the installation is done?
You can follow the progress of your Spack installation by logging onto the cluster head node and running tail -f /var/log/spack-postinstall.log to watch the end of installer’s log file. While the installer is running, this command will show a live stream of the installation process. When it has completed, the last line of the log will read ***Spack setup completed***. If the installation fails to complete, you can look for errors in the log file.
Once you see that installation has completed, log into the cluster again (or launch a new shell) and type spack find to show all packages that Spack has installed. You’ll see a response like Figure 2.
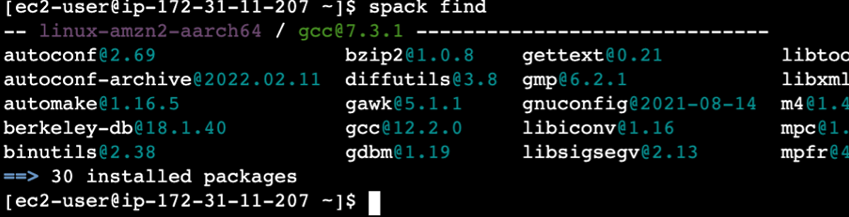
Figure 2: Example output from the Spack find command.
You can now use Spack interactively and in Slurm jobs. It’s possible to load packages directly, using spack load <PACKAGE-NAME>.
Spack also integrates with the onboard Environment Modules system. Let’s say you wanted to change compilers — if you enter module load gcc, version 12.2.0 of that compiler will activate rather than the default version 7 (Figure 3). For more information on modules, see the online documentation for Environment Modules and Spack.

Figure 3 Switching compilers using the module system and Spack
Installing Packages Using Spack
You can install thousands of software applications and libraries with Spack. To install one, login to your cluster head node and enter spack install <PACKAGE-NAME> on the command line. Spack will either download your application and its dependencies from the Spack Binary Cache or compile them from source code.
You can find out what packages (and versions) can be installed using the spack list command or by reading the online list of packages. The Spack 101 tutorial provides more detail on package installation, as well how to assemble them together into collections and integrate them with the Environment modules system.
Contributing to Spack
Spack is home to an extensive contributor community. If you find a way to improve on the Spack configs for AWS ParallelCluster or any existing Spack packages, or if you want to contribute your own package recipe, you are welcome to do so. Detailed instructions for getting started are in the Contribution Guide section of the Spack documentation.
Summary
Installing HPC applications can be challenging even for experts. Spack configs for AWS ParallelCluster make it easy to build tuned versions of several important HPC applications using best practices developed by the AWS HPC Performance Engineering Team.
You can configure your AWS ParallelCluster systems to install them automatically, or you can install them manually. Once installed, codes like WRF, GROMACS, and Quantum Espresso can run highly optimized on a variety of AWS EC2 instance types.
You can learn more about Spack by checking out the Spack project home page and documentation. We’d love to hear how Spack configs for AWS ParallelCluster are working for you. Reach out to us at ask-hpc@amazon.com.