AWS HPC Blog
Understanding the AWS Batch termination process
This blog helps you understand the AWS Batch job termination process and how you may take actions to gracefully terminate a job by capturing SIGTERM signal inside the application. It provides you with an efficient way to exit your Batch jobs. You also get to know about how job timeouts occur, and how the retry operation works with both traditional AWS Batch jobs and array jobs.
Jobs are the unit of work invoked by AWS Batch. Jobs are invoked as containerized applications running on Amazon ECS container instances in an ECS cluster. When you submit a job to an AWS Batch job queue, the job enters the SUBMITTED state and proceeds through a series of job states, as depicted in Figure 1, until it succeeds (exits with code 0) or fails (exits with a non-zero code). AWS Batch jobs can have the following jobs states:
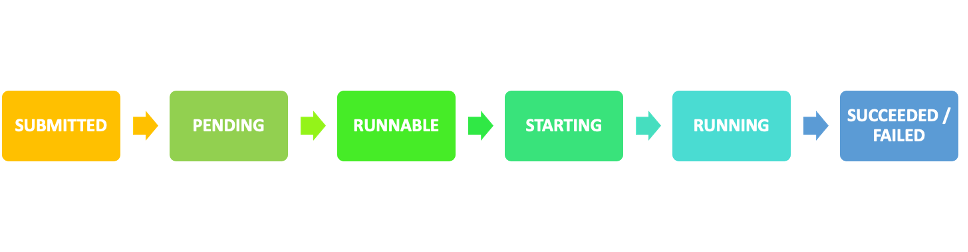
Figure 1. The available job states that a job goes through during its lifetime
The whole idea behind working with AWS Batch or batch processing workloads in general is to run workloads at scale with minimal intervention. Let’s consider an example where a customer is running a combination of both On-demand and Spot Instances in their AWS Batch compute environment to strike a balance between resource availability and higher instance cost. In this scenario, whenever an instance is taken out of service due to spot interruption, the Batch job running on the instance also gets terminated. Hence, customers are constantly looking to achieve fine grained control over their job’s termination process. This is made possible by having more information around how the job termination process mechanism works in AWS Batch.
Going ahead, we will discuss how AWS Batch handles job termination process for various job states – what goes under the hood in this managed service, how you can handle job terminations gracefully inside container application using a sample example, how timeout terminations happen, and how one can work with automated job retries.
Deep Dive – AWS Batch job termination process
AWS Batch utilizes Amazon ECS service under the hood. Every compute environment that you create in your Batch setup gets a corresponding ECS Cluster created to manage the compute resources. Similarly, for every job that is submitted to Batch, a corresponding ECS Task is run in the backend to process the workload on the containers.
Let us understand how AWS Batch handles termination for jobs in different states.
Termination of jobs in RUNNING state
When an AWS Batch job in RUNNING state is terminated (TerminateJob), the backend handler concerning the termination event invokes a termination event. This event contains metadata about the job including the JobARN. The handler fetches critical information about the job like the job status, from the service’s internal database. Batch sees that the status of the job is running, and consequently it proceeds with stopping the task with a StopTask API call.
The job details are pulled from the service datastore and the task details are pulled from the termination event.
The handler proceeds making the StopTask call with the information stored in backend database such as the ECS cluster ARN, task ID, and reason it received from the termination event. The AWS Batch service role associated with the compute environment makes the API call and the job moves to FAILED state. This API call gets logged into CloudTrail made by the user aws-batch:
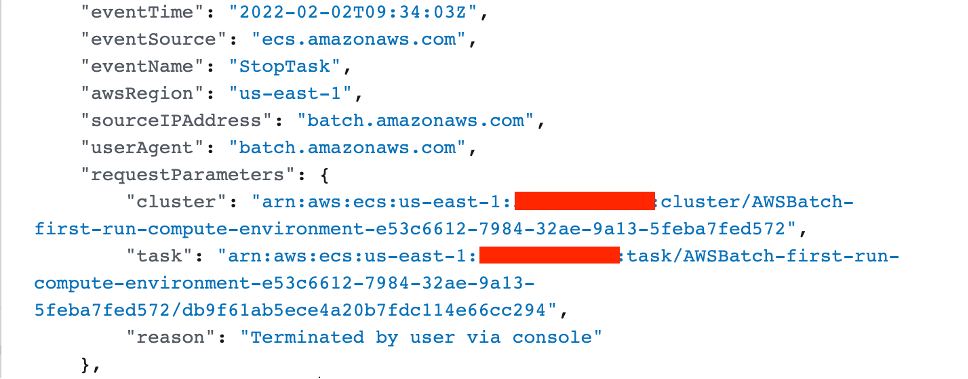
Figure 2. Snippet from the API call logged in CloudTrail
If any issue is encountered during this synchronous process, the service performs a retry logic.
Termination of jobs in RUNNABLE state
A job in RUNNABLE state is a job waiting in the job queue to be scheduled on a compute resource. Hence, it is not terminated immediately, and that is precisely the reason why users may notice that the job does not go to failed state immediately.
For a job in job queue that is in RUNNABLE state, it needs to move to the head of the job queue in order to be identified and marked for termination. Until the job moves to the head of the queue, the job continues to show up in RUNNABLE state. When it moves to the head of the queue, Batch sees that the job was ‘marked for termination’ or ‘termination was invoked’, and consequently proceeds with the termination event.
Termination behaviour of jobs with dependency
Again, when a job is dependent on another job, it stays in pending until the job on which it depends has finished execution. This job stays in PENDING status. The termination behaviour of jobs in PENDING status is similar to that of the jobs in RUNNABLE status. When the termination event is invoked, it is marked for termination. But the job does not move to failed state unless it reaches the head of the job queue.
Once it reaches the head of the job queue, Batch identifies that the termination flag is set, and it proceeds with termination of the job.
Gracefully Handling job termination inside container application
The ECS agent running on the EC2 instance or the Fargate resource picks up the change in state of the task and performs the action such as internally calling “Docker stop container-id”. This would send the signal SIGTERM to the application running inside the Docker container.
In your container, you can capture the SIGTERM signal, which allows you to perform a cleanup of resources before the container exits, or gracefully terminate by performing some other actions. You can use graceful termination to perform tasks like saving critical data or sending a notification to close all open connection before the application gets terminated.
Here is a sample Python script that you can use to capture the SIGTERM signal, and cleanly exit the program using the `sys.exit` function:
# testsignal.py
import sys, signal, time
# Python function that captures SIGTERM
def handleSigTERMKILL(signum, frame):
print("application received SIGTERM signal: " + str(signum))
print("Cleaning up resources")
# Code for cleaning up resources goes here
print("exiting the container gracefully")
# You can at this point use the sys.exit() to exit the program, or
# continue on with the rest of the code.
# sys.exit(signum)
# Assign the handler function to the SIGTERM signal
signal.signal(signal.SIGTERM, handleSigTERMKILL)
# The rest of the program
print("continue to execute the rest of the code")
time.sleep(1000)
The following figure shows the job logs on the AWS Batch console (Figure 3). The logs show that the application container received SIGTERM signal and terminated gracefully.
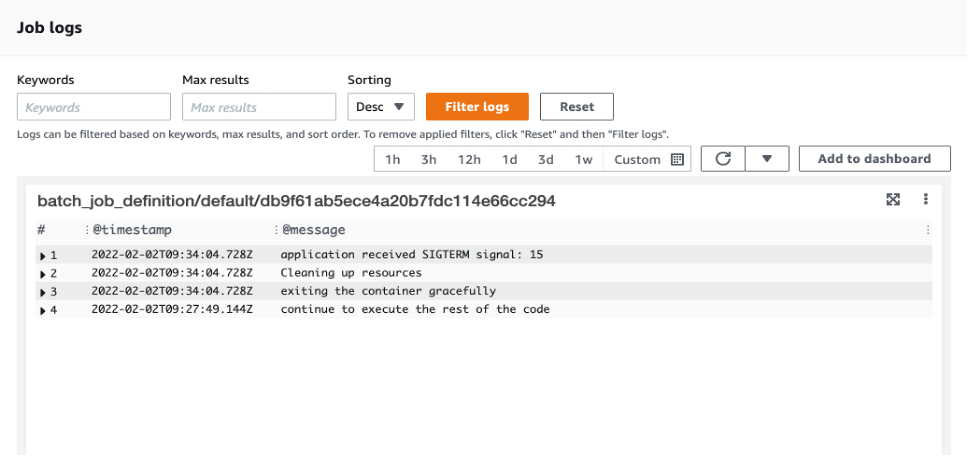
Figure 3. All logs get captured in CloudWatch
After a default timeout of 30 seconds, the ECS agent sends a SIGKILL to the Docker container. There is no way to handle a SIGKILL inside the application and the Docker container gets terminated. If you require more time to cleanup the resources after the signal SIGTERM then you would need to modify the ECS_CONTAINER_STOP_TIMEOUT variable of the ECS agent to suit your needs.
Detecting when a job is not moving forward
If your compute environment contains compute resources, but your jobs don’t progress beyond the RUNNABLE state, then something is preventing the jobs from being placed on a compute resource. However, if you have scheduled actions to be completed with Batch jobs, or if you do not have any mechanism monitoring the jobs, then your jobs might stay in any of the transit states if left unattended.
You may end up continuing forward, unaware that your job has yet to run. Eventually, when you see the jobs not progressing beyond the RUNNABLE or PENDING state, you miss the task that the job was expected to do in the given timeframe. This can result in additional time and effort troubleshooting the stuck job.
To prevent this accidental avoidance or lack of in-transit job monitoring, you can use CloudWatch Events to configure a threshold monitoring duration for your jobs so that if a job stays in SUBMITTED/PENDING/RUNNABLE longer than that, then you get a SNS notification.
CloudWatch Events becomes aware of operational changes as they occur. CloudWatch Events responds to these operational changes and takes corrective action as necessary, by sending messages to respond to the environment, activating functions, making changes, and capturing state information. You can create a CloudWatch event that would monitor the job status change for a particular queue and pass on to Lambda function to take action on it.
Following is the CloudWatch event rule which monitors the job status change for the JobQueue when the status is FAILED:
{
"detail-type": [
"Batch Job State Change"
],
"source": [
"aws.batch"
],
"detail": {
"status": [
"FAILED"
]
}
}
Once this event is captured, you can have a Lambda function to act upon the Job termination event and act as needed based on the Lambda you write. The Lambda function can check every job in transit for more than ‘X’ seconds on all compute environments since the job submission and trigger notification to subscribed users using SNS.
For example, you might have a job that you would want to proceed to the RUNNING state in approximately 15 minutes since the job submission. Sometimes a slight misconfiguration can cause the job to get stuck in RUNNABLE indefinitely. Hence, in this situation when the specified duration is crossed, Lambda function can notify you about your job staying in transit beyond your defined threshold status. You can find a tutorial on this here.
Job timeouts
In addition to handling a failure to transition to a running state, you can also specify the timeout value for every job. This comes in handy when you know your job should be taking a specific amount of time. For example, you might have a job that should only take 15 minutes to complete. However, it’s possible that sometimes your application may get stuck in a loop and runs forever, occurring unnecessary cost. Hence, you can set a timeout of 30 minutes to terminate the stuck job. You can refer Job Timeouts section for more details.
Automated job retries
You can apply a retry strategy to your jobs and job definitions that allows failed jobs to be automatically retried. When a job is submitted to a job queue and placed into the RUNNING state, that is considered an attempt. By default, each job is given one attempt to move to either the SUCCEEDED or FAILED job state. If a job attempt fails for any reason, then based on the number of retries you have specified, retry attempts will be made. The job is placed back in the RUNNABLE state.
How job retries work with Array jobs
Before we dive into the timeouts and retries in case of Array jobs, let us understand what Array jobs are. An array job is a type of Batch job that shares common parameters, such as the job definition, vCPUs, and memory. It runs as a collection of related, yet separate, basic jobs that may be distributed across multiple hosts and may run concurrently. When you have a requirement to run parallel jobs like Monte Carlo simulations, you should consider using Array jobs.
As far as the job submission is concerned, these jobs are submitted like the usual AWS Batch jobs with a specification of Array size. For example, if you submit a job with an array size of 100, one single job will run and also spawn 100 child jobs. The submitted array job becomes the reference or pointer to manage all the child jobs. This helps you to submit large parallel workload jobs with a single query.
When an array job is submitted, the parent array job gets a normal AWS Batch job ID. Every child job has the same base ID, but the array index for the child job is appended to the end of the parent ID, such as example_job_ID:0 for the first child job of the array. If an array job fails, Batch will:
- Retry the child jobs individually.
- The entire parent is not retried.
- Jobs that have been cancelled or terminated are not retried. Also, jobs that fail due to an invalid job definition are not retried.
How job termination works in Array jobs
If you cancel or terminate a parent array job, all of the child jobs are cancelled or terminated with it. However, you can cancel or terminate individual child jobs (which moves them to the FAILED status) without affecting the other child jobs.
Consider a situation where we specify the attempts to 3 for parent job, then each child job will be attempted 3 times before failing but parent job will be attempted only once. Also we have to keep in mind that if we are specifying the SEQUENTIAL option while submitting the job then only first failed child job will be retried 3 times while on other hand if we will not specify the SEQUENTIAL option while submitting the job then each failed child job will be retried 3 times.
Conclusion
Now that you have read the blog, you should have a better understanding of Batch job termination process for different job states and how to gracefully capture SIGTERM signals inside container application. We dove deeper into the best practices for avoiding unnecessary cost by configuring job timeouts. Additionally, we also discussed an automated notification mechanism using CloudWatch Events with Lambda and SNS, that makes it easier to detect and troubleshoot job transition issues during day to day operations.