AWS for Industries
Achieve Healthcare Interoperability by integrating Amazon Comprehend Medical with FHIR
Healthcare interoperability is a major initiative across all stakeholders of the healthcare ecosystem, and the Fast Healthcare Interoperability Resources (FHIR) standard has opened the doors for a modern approach to sharing such information. I have frequently heard from healthcare customers that they want to make a difference in patients’ lives by sharing the most relevant and actionable information about their patients. Any technology enabler to achieve such a goal would be valuable to the industry. According to a study published in the Nature journal, the researchers were able to build a disease trajectory model using unstructured text in electronic health records. This allowed them to predict 80% of adverse patient events ahead of time. Last year, AWS launched a service – Amazon Comprehend Medical, which enables customers to extract clinical entities from unstructured text like medical notes. The service has opened the doors for several use cases, including using medical conditions extracted from notes to identify patients for clinical trials, and assessing the effectiveness of a drug based on the medication information extracted from the notes. The power of a Natural Language Processing (NLP) engine is now available to developers using a simple API (Application Programming Interface). As a next step, customers can convert such data into an open format like FHIR and make it available to interested parties like researchers, government agencies, app developers or directly to patients. In this blog, I walk you through the approach to extract clinical entities from medical notes, map them to FHIR resource and load them to an FHIR repository. As a reference, I only focus on the Condition resource mapping but the concept can be applied to other resources as well.
Problem statement
Customers may get raw clinical notes from various sources such as their provider systems (such as Electronic Health Records, Labs, and Radiology), voice notes, scanned documents, social media feeds and transcription systems. The notes are eventually converted into some form of text-based message format like an HL7 (Health Level 7) V2 message or an FHIR document with the notes embedded in the body. HL7 V2 has been the de-facto messaging standard for clinical data exchange, but it was designed at a time when compute and storage resources were expensive and hard to procure. As a result, it is cryptic and not easily interpretable by humans. As part of this blog, I walk you through both source data scenarios – HL7V2 and FHIR.
The MDM (Medical Document Management) message is one such common HL7 V2 message type, which is used to send and receive raw clinical documents such as notes. Customers have systems that can extract the documents from such messages but need manual intervention or complex rules engine to derive relevant clinical entities. They need a way to automate such processing and generate actionable data like patient information, lab results, medical conditions, and observations. The other source of such data would be existing FHIR messages, which contain such documents. The most widely used FHIR resource to send documents is DocumentReference.
Currently, customers extract the clinical notes from such messages and simply store them as part of their EHR (Electronic Health Records) system. However, they face challenges in deriving the most relevant data, converting it to a standardized format like FHIR resources, and linking that data to patient records so that they are searchable and analyzed further.
Solution overview
Amazon Comprehend Medical, along with FHIR helps us remediate the challenge. At a high level, the solution architecture is shown in figure 1. The architecture uses serverless components to build the processing pipeline. It uses S3 events to trigger the processing. The event is captured in an SQS queue, which triggers an AWS Lambda function. The Lambda function gets the details of the uploaded file and passes it on to an AWS Step Function. The Step Function performs the orchestration of the various steps needed to extract unstructured data from an FHIR or HL7 message and then make the API calls to Amazon Comprehend Medical and the FHIR server. The credentials to make the call to an FHIR API are kept in AWS Secrets Manager. The architecture achieves scalability and high availability by relying on the self-managed capabilities of AWS Lambda and AWS Step Functions. Amazon S3 provides the high durability and availability for the storage needed for the data files. Amazon Comprehend Medical is also self-managed and serverless, which needs no provisioning of servers. All the services used as part of the solution are HIPAA eligible services and can be used to transmit and process PHI (Protected Health Information). Please refer to the AWS HIPAA eligible services page for more details on HIPAA compliance. The functional details of the flow are described in more detail in the next section.
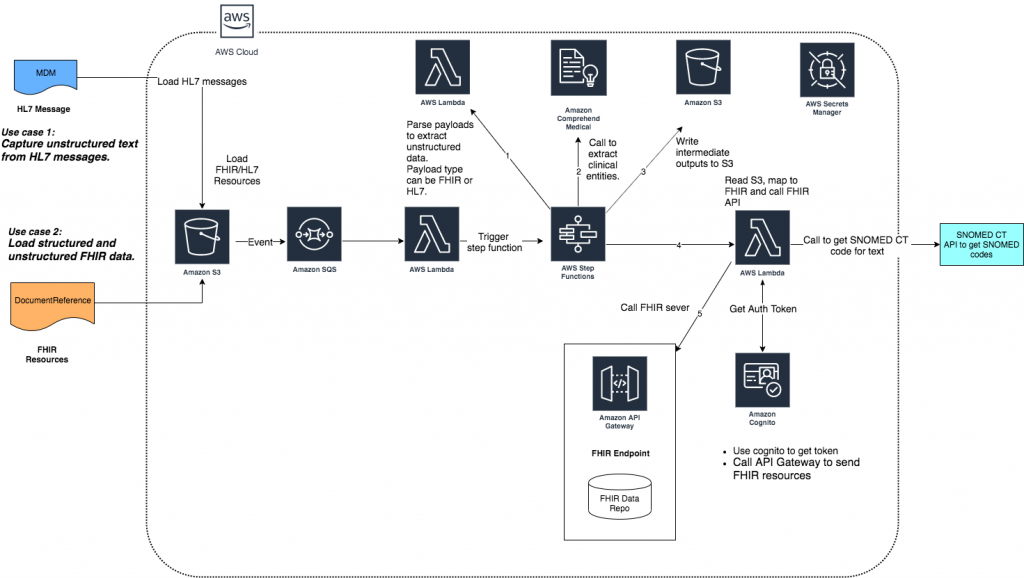
Message flow details
The solution is triggered by data sources described earlier. The first is an MDM message, and the second is a DocumentReference FHIR document. Customers may be sourcing the data through various channels but as part of this solution I am assuming that it can be placed in a S3 bucket. Let’s look at each of the message format in some more detail:
MDM message
Here is a sample of the MDM message that I used for testing. It is taken from public internet sources and modified specifically for testing.
MSH|^~\&|Epic|Epic|||20160510071633||MDM^T02|12345|D|2.3
PID|1||68b1c58d-41cd-4855-a100-8206eb1b61b5^^^^EPI||Larkin917^Monroe732^J^^MR.^||19720817|M||AfrAm|377 Kuhic Station Unit 91^^Sturbridge^MA^01507^US^^^DN |DN|(608)123-9998|(608)123-5679||S||18273652|123-45-9999||||^^^WI^^
PV1|||^^^CARE HEALTH
SYSTEMS^^^^^||||||1173^MATTHEWS^JAMES^A^^^||||||||||||
TXA||CN||20160510071633|1173^MATTHEWS^JAMES^A^^^|||||||^^12345|
||||PA|
OBX|1|TX|||Clinical summary: Based on the information provided, the patient likely has viral sinusitis commonly called a head cold.
OBX|2|TX|||Diagnosis: Viral Sinusitis
OBX|3|TX|||Diagnosis ICD: J01.90
OBX|4|TX|||Prescription: benzonatate (Tessalon Perles) 100 mg oral tablet 30 tablets, 5 days supply. Take one to two tablets by mouth three times a day as needed. disp. 30. Refills: 0, Refill as needed: no, Allow substitutions: yes
The OBX segment in the message has unstructured medical notes embedded in them. As part of the initial processing step – the data from the OBX-4 segment is extracted and processed with Amazon Comprehend Medical.
DocumentReference
The second data source is an FHIR document, which contains unstructured text. A DocumentReference object has a data node, which takes a base64 encoded payload as an unstructured text. A snippet of the file is shown below. It is shortened for readability.
The complete file can be found in the project source code. The highlighted text is a base64 encoded text for clinical notes.
The solution would extract the unstructured text from both the sources (MDM and FHIR), process it using Amazon Comprehend Medical and then map it into FHIR resource. The first step of the solution would pick the source data file from S3 bucket once it’s uploaded. The S3 upload event would send a notification event on SQS queue. The event is processed by a Lambda function, which triggers a step function. I have used Java as the programming language but customers can choose to implement the same solution in any programming language of their choice. The main section of the Lambda function is described below:
The Lambda functions extract the complete file name url from the event and passes it on to a step function. The overall flow is described in the visual representation of the function.

The first Lambda function in the step determines if the source data is an HL7 or an FHIR document. It calls a Lambda function, which then parses either the HL7 or the FHIR message. Based on the type, the unstructured text is either extracted from OBX segment or from the data node. I have used the open source HAPI (HL7 Application Programming Interface) HL7 V2 libraries to parse the MDM message and open source HAPI FHIR libraries to parse the FHIR document. Once the raw clinical notes are extracted, it is temporarily written to an S3 bucket. The next step reads the unstructured text and passes it to Amazon Comprehend Medical, which processes it and returns a JSON document, which shows the various entities that are extracted. The major section of the source code is shown as below:
The source code shows the implementation of making an API call to Amazon Comprehend Medical and getting the JSON output. A visual representation for the JSON output is shown in the picture below:

The identified clinical entities are highlighted in the picture. At this step, we have already extracted most of the relevant data, which can provide deeper insight into patients’ medical profile. For example, we see entities that highlight the diagnosis, medication as well as dosage. The next step takes this dataset and converts it into an FHIR message. In my solution, I specifically focused on medical Condition but customers can easily add their modules to extract Patient, Medication, and Observation entities that have corresponding mapping in FHIR. The picture below shows a reference mapping between the medical condition extracted and an FHIR Condition resource.

One of the main mapping elements is the text extracted in Amazon Comprehend Medical output shown on left and the display field mapping on FHIR resource shown in right. The other important element is the Systematized Nomenclature of Medicine — Clinical Terms (SNOMED CT) code for the medical condition. As part of the step that builds the FHIR resource, I used the publicly exposed SNOMED CT API endpoints to perform a search based on the text and get the resulting SNOMED CT codes. The first item in the resulting list is used to map to the FHIR. The code value is highlighted in purple in above picture. Here is main section of the code that makes the call to SNOMED CT and gets the code for mapping:
As part of this solution, I also mapped the body site for a condition. The logic to extract the body site from Amazon Comprehend Medical output can be found in the source code. The body site extracted from the text must be further converted into a SNOMED CT code. I used the same approach for getting the SNOMED CT code for body site. The solution also maps the other parts of the FHIR resource like the Patient resource based on data extracted from the source document. Patient resource is enhanced by adding the Condition resources that have been extracted. It is then sent to an FHIR server endpoint and saved into the repository. In the reference solution, I used an FHIR interface that was built using AWS serverless API’s and Amazon Cognito. However, it can be easily changed to use any publicly available FHIR endpoints. A list of publicly available FHIR servers can be found here. Please refer to the full source code on GitHub to get additional details.
The Condition resources that have been appended to the Patient resource is now searchable using FHIR APIs. It can be converted to other formats like parquet and used for triggering other analytics workflows as well as for training machine learning models. The advantages of FHIR can now be fully leveraged on data that was earlier trapped in unstructured text documents.
Conclusion
Healthcare data interoperability is not just a buzzword today, but a need. Most major technology vendors have taken pledges to make healthcare data interoperable. FHIR has enabled such sharing in the most modern and extensible way. Patient privacy and other compliance needs will drive the extent of its adoption but it has definitely seen early success. In this blog, I have shown how valuable healthcare data stored in unstructured text can be extracted using machine learning and further enhanced to an open standard like FHIR. The goal of democratizing machine learning and applying it to solve every day healthcare challenges is possible.
For more information on Amazon Comprehend Medical, check out the Introducing Medical Language Processing with Amazon Comprehend Medical blog post.