Integration & Automation
Disaster recovery: 3 failover scenarios for your Amazon Aurora global database with Terraform (Part 2)
In Part 1—Prepare for faster disaster recovery: Deploy an Amazon Aurora global database with Terraform—I (Arabinda) walked through using the Terraform Amazon Aurora module* to automate the deployment of an Amazon Aurora global database across multiple AWS Regions. I also discussed how to transition the management of an existing Aurora global database cluster using this Terraform module.
Here, in Part 2, Shayon and I discuss how you would recover such a global database after a failover event. We walk through various failover scenarios available for the Aurora global database, observe their effect on Terraform state, and discuss how to maintain the global database topology and configuration using Terraform.
*The Terraform Amazon Aurora module is in alpha state and will undergo significant changes. As of this writing, this module uses mainly the primary AWS provider. It’s expected to change to use the Terraform AWS Cloud Control Provider.
| About this blog post | |
| Time to read | ~11 min. |
| Time to complete | ~30 min. (including deployment) |
| Cost to complete | ~$2 |
| Learning level | Advanced (300) |
| AWS services | Amazon Aurora Global Database
Amazon CloudWatch AWS Key Management Service (AWS KMS) |
Prerequisites
Before you start the walkthrough in this post, complete the walkthrough in Part 1. You will have provisioned an Aurora global database across two AWS Regions using the Terraform Amazon Aurora module, resulting in the following architecture:
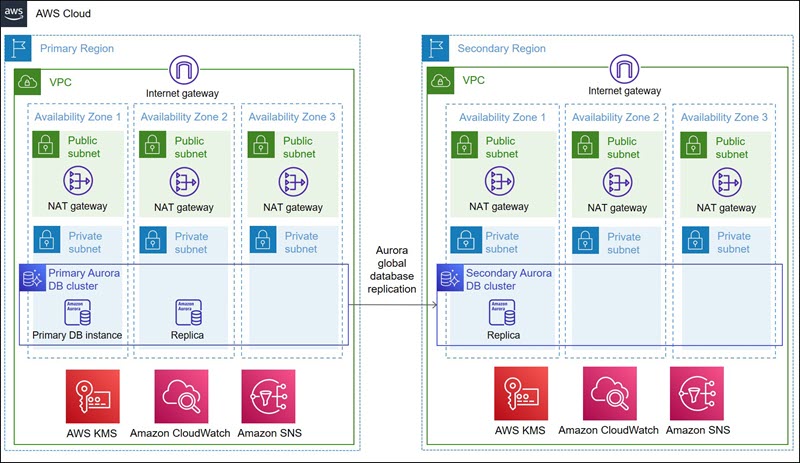
Failover scenarios in Aurora Global Database
An Aurora global database provides more comprehensive failover capabilities than a provisioned Aurora DB cluster. (For details, see High availability for Amazon Aurora.) By using an Aurora global database, you can plan for and recover from disaster relatively quickly. With an Aurora global database, there are three approaches to failover depending on the scenario:
- Scenario 1: Primary writer failover to another Availability Zone in the primary Region (same as failover capability provided by a multi-AZ-provisioned Aurora DB cluster)
- Scenario 2: Planned primary Region rotation or switch to a secondary Region (managed planned failover).
- Scenario 3: Unplanned primary Region failover to a secondary Region (detach and promote).
Scenario 1: Primary writer failover to another Availability Zone in the primary Region
This is the same failover method as provided by a provisioned Aurora DB cluster in multi-AZ mode.
When you set up an Aurora global DB cluster in multi-AZ mode by creating an Aurora replica in a different Availability Zone than the Availability Zone of the primary DB instance, the cluster becomes highly available in a single AWS Region. If the primary DB instance fails for any reason, or if the Availability Zone where the primary instance is hosted becomes unavailable, the Aurora replica is automatically promoted to become the new primary.
Scenario 2: Planned primary Region rotation or switch to a secondary Region
Use this method—known as managed planned failover—only on a healthy Aurora global database cluster where all AWS Regions are operating normally. In the unlikely case of a disaster where a Region becomes unavailable, use the unplanned failover, described in the following section.
This approach is intended for controlled environments, such as operational maintenance and other planned operational procedures. With this failover method, you relocate (or switch) the primary DB cluster of your Aurora global database to one of the secondary AWS Regions in an automated way without data loss and without affecting the topology of the global database. After the failover, the old primary DB cluster and all the other secondary DB clusters replicate data from the new primary DB cluster without any manual intervention.
Scenario 3: Unplanned primary Region failover to a secondary Region
The unplanned failover method, also called detach and promote, assumes that your current primary AWS Region is experiencing a rare extended outage and that you need to quickly failover your database to the secondary Region. You manually remove a secondary Aurora DB cluster from the Aurora global database topology, immediately stopping the replication from the primary to this secondary and promoting it as a standalone Regional cluster with full read-write capabilities. After the impacted AWS Region’s operational state returns to normal, you need to add secondary Regions to your new primary Aurora DB cluster to recreate the global database topology.
Walkthrough
In this walkthrough, you simulate the three failover scenarios on your Aurora global database cluster using the AWS Management Console and see the effects on Terraform state.
We recommend that you follow these simulations in order. This way, the Aurora global database topology (including the primary and secondary AWS Regions) ends up being exactly the same as the architecture you had initially deployed. If you do the simulations in a different order, you would have to perform a managed planned failover following an unplanned failover and recreation of the Aurora global database topology to relocate your primary Aurora cluster back to its original AWS Region.
Step 1. Simulate scenario 1 (primary writer failover to another Availability Zone in the primary Region)
- Sign in to AWS Management Console, and open the Amazon RDS console.
- Select DB Instances on the RDS dashboard page, or select Databases in the left navigation pane.
- Select the DB with the Writer instance role, and then choose Actions, Failover.

- When prompted, confirm the failover. When the simulated failover is complete, the reader instance and writer instance have switched roles, as shown in this example:

- Review the effect of role change on Terraform state by running the following commands in your terminal window. Replace <TF_STAGING_DIR> with the directory in which you cloned the terraform-aws-rds-aurora GitHub repository. Refer to Part 1 for details.
cd <TF_STAGING_DIR>/terraform-aws-rds-aurora/deploy
terraform plan
Terraform detects the DB instance role changes along with some other changes by comparing its state file with the actual state of AWS resources.

At the bottom, Terraform shows that there are no infrastructure-related changes required on AWS and provides an option to sync the Terraform state, as shown here:

Terraform relies on the contents of its state file to generate an execution plan to make changes to your AWS infrastructure. So it’s a good practice to keep your state file up to date to ensure the accuracy of the proposed changes when you change your Terraform config and apply.
- Update the Terraform state with the detected changes by running the following command in your terminal window, replacing the information in brackets.
cd <TF_STAGING_DIR>/terraform-aws-rds-aurora/deploy
terraform apply -refresh-only --auto-approve
- Verify the sync of terraform state by running the
terraform plancommand again. The following messages appear:

Step 2. Simulate scenario 2 (planned primary Region rotation or switch to a secondary Region)
- Sign in to AWS Management Console, and open the Amazon RDS console.
- Select DB Instances on the RDS dashboard page, or select Databases in the left navigation pane.
- Select the global DB cluster, and choose Actions, Fail over global database.

- Under Choose a secondary cluster to become primary cluster, choose a cluster. Then choose Fail over global database.

The status bar at the top of the console displays progress. After the failover is complete, the cluster in us-west-2 has become the new primary, and the cluster in us-east-2 has become the new secondary.

- Verify the effect of the failover on Terraform state by running
terraform plan, as earlier. Terraform detects the role changes for the DB clusters and suggests that you apply a refresh-only plan to sync its state. There are no infrastructure-related changes required on AWS.
- Run
terraform apply -refresh-only --auto-approveto sync Terraform state and ensure the accuracy of the proposed changes when a drift happens in the future.
Step 3. Simulate scenario 3 (unplanned primary Region failover to a secondary Region)
- Sign in to AWS Management Console, and open the Amazon RDS console.
- Select DB Instances on the RDS dashboard page, or select Databases in the left navigation pane.
- Remove the secondary Aurora DB cluster from the global database, as shown:

- When prompted, confirm the action. After the operation completes, the chosen secondary Aurora DB cluster in us-east-2 is promoted to a Regional standalone cluster. Replication from the primary to this secondary stops immediately.

When the outage happening in your old primary Region (us-west-2 for this blog post) is over, you will add a secondary Region (us-west-2) to your Regional Aurora cluster in us-east-2 using Terraform to restore your global database topology. Do not run terraform apply at this stage. If you do, Terraform tries to add a standalone Aurora Regional cluster to an existing Aurora global database, which is currently not supported. To avoid this, you will first delete the old primary cluster in us-west-2 for Terraform to recreate this cluster as the new secondary.
- Remove the old primary cluster in us-west-2 from the global database, as shown:

- When prompted, confirm the action. After the old primary Aurora DB cluster is detached from the global database, choose the AWS Region in AWS console (us-west-2 or Oregon for this blog post) where the DB cluster was running to be able to view the cluster and delete it.
- Delete the writer instance of the old primary cluster, as shown:

- Select the second option (I acknowledge that…), type delete me in the box, and choose Delete. (In a production environment, you should select Create final snapshot before deleting a DB instance.)

After all instances of the DB cluster are deleted, the DB cluster is automatically deleted as well. You should now have an empty Aurora global database (the size is now 0 clusters), and your Regional Aurora DB cluster is us-east-2, as shown here:
![]()
- Delete the empty Aurora global database, as shown. When prompted, confirm the action. (This is required because adding an existing Aurora DB cluster to an existing Aurora global database cluster is not supported.)

- Create a new Aurora global database cluster by using your Regional Aurora cluster in us-east-2 as the primary. To do this, run the following command in your terminal window. Use the same Aurora global database cluster name that was set up by Terraform, for example,
aurora-globaldb.
After the command executes, you should have an Aurora global database created with the primary Aurora cluster attached, as shown:

- Confirm that the
<TF_STAGING_DIR>/terraform-aws-rds-aurora/deploy/terraform.auto.tfvarsfile has thesetup_as_secondaryvariable set to false because the originalaws_rds_cluster.primaryTerraform resource still exists and is the primary Aurora cluster as it was set up originally. To confirm this, runterraform planas follows, replacing the information in brackets. (This shows that only theaws_rds_cluster.secondaryresource needs to be created along with other dependent resources.)
cd <TF_STAGING_DIR>/terraform-aws-rds-aurora/deploy
terraform plan

Certain resource arguments of the aws_rds_cluster Terraform resource—such as database_name, master_username and master_password—are applicable only when an Aurora cluster is set up as a primary. They need to be skipped when an Aurora cluster needs to be set up as secondary for a successful Terraform deployment. The setup_as_secondary variable, which is referred in the aws_rds_cluster.primary Terraform resource, controls this logic in the Aurora Terraform module. The default value for this variable is false. When the aws_rds_cluster.primary resource needs to be set up as a secondary instead of a primary, you need to set the setup_as_secondary variable value to true using the <TF_STAGING_DIR>/terraform-aws-rds-aurora/deploy/terraform.auto.tfvars file.
Now, you are ready to run Terraform to create your secondary Aurora DB cluster in the us-west-2 Region.
- Recreate the secondary Aurora cluster by running the following in your terminal window, replacing the information in brackets.
cd <TF_STAGING_DIR>/terraform-aws-rds-aurora/deploy
terraform apply --auto-approve
After the command completes, you should have the Aurora global database topology recreated, as shown:

Cleanup
Some of the AWS resources created by the Terraform Amazon Aurora module incur costs as long as they are in use. When you no longer need the resources, clean them up by following the cleanup instructions in Part 1.
Conclusion
In this post, we walked through three failover scenarios available for the Aurora global database, observed their effect on Terraform state, and discussed how to maintain the global database topology and configuration using the Terraform Amazon Aurora module, which is published by the AWS Infrastructure & Automation team.
By using infrastructure-as-code software, such as Terraform, you can save time for your AWS deployments and make sure that the resources across multiple AWS Regions are set up consistently in a repeatable and predictable manner. In the event of a Region-wide outage, your secondary AWS Region can take over the full read and write workload upon switching from your primary Region.
If you have comments or questions about this blog post, please use the comments section. To submit bug fixes or request enhancements, open a pull request or an issue in the Terraform Amazon Aurora module GitHub repository
About the authors

Arabinda Pani
Arabinda, a principal partner solutions architect specializing in databases at AWS, brings years of experience from the field in managing, migrating, and innovating databases and data platforms at scale. In his role, Arabinda works with AWS Partners to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS.

Shayon Sanyal
Shayon is a principal database specialist solutions architect at AWS. His day job allows him to help AWS customers design scalable, secure, performant, robust database architectures in the AWS Cloud. Outside of work, you can find him hiking, traveling, or training for the next half-marathon.