Artificial Intelligence
Tag: Amazon SageMaker

Accelerating LLM fine-tuning with unstructured data using SageMaker Unified Studio and S3
Last year, AWS announced an integration between Amazon SageMaker Unified Studio and Amazon S3 general purpose buckets. This integration makes it straightforward for teams to use unstructured data stored in Amazon Simple Storage Service (Amazon S3) for machine learning (ML) and data analytics use cases. In this post, we show how to integrate S3 general purpose buckets with Amazon SageMaker Catalog to fine-tune Llama 3.2 11B Vision Instruct for visual question answering (VQA) using Amazon SageMaker Unified Studio.

Introducing Disaggregated Inference on AWS powered by llm-d
In this blog post, we introduce the concepts behind next-generation inference capabilities, including disaggregated serving, intelligent request scheduling, and expert parallelism. We discuss their benefits and walk through how you can implement them on Amazon SageMaker HyperPod EKS to achieve significant improvements in inference performance, resource utilization, and operational efficiency.

Train CodeFu-7B with veRL and Ray on Amazon SageMaker Training jobs
In this post, we demonstrate how to train CodeFu-7B, a specialized 7-billion parameter model for competitive programming, using Group Relative Policy Optimization (GRPO) with veRL, a flexible and efficient training library for large language models (LLMs) that enables straightforward extension of diverse RL algorithms and seamless integration with existing LLM infrastructure, within a distributed Ray cluster managed by SageMaker training jobs. We walk through the complete implementation, covering data preparation, distributed training setup, and comprehensive observability, showcasing how this unified approach delivers both computational scale and developer experience for sophisticated RL training workloads.

Agentic AI with multi-model framework using Hugging Face smolagents on AWS
Hugging Face smolagents is an open source Python library designed to make it straightforward to build and run agents using a few lines of code. We will show you how to build an agentic AI solution by integrating Hugging Face smolagents with Amazon Web Services (AWS) managed services. You’ll learn how to deploy a healthcare AI agent that demonstrates multi-model deployment options, vector-enhanced knowledge retrieval, and clinical decision support capabilities.

Scale LLM fine-tuning with Hugging Face and Amazon SageMaker AI
In this post, we show how this integrated approach transforms enterprise LLM fine-tuning from a complex, resource-intensive challenge into a streamlined, scalable solution for achieving better model performance in domain-specific applications.

Evaluate generative AI models with an Amazon Nova rubric-based LLM judge on Amazon SageMaker AI (Part 2)
In this post, we explore the Amazon Nova rubric-based judge feature: what a rubric-based judge is, how the judge is trained, what metrics to consider, and how to calibrate the judge. We chare notebook code of the Amazon Nova rubric-based LLM-as-a-judge methodology to evaluate and compare the outputs of two different LLMs using SageMaker training jobs.

Simplify ModelOps with Amazon SageMaker AI Projects using Amazon S3-based templates
This post explores how you can use Amazon S3-based templates to simplify ModelOps workflows, walk through the key benefits compared to using Service Catalog approaches, and demonstrates how to create a custom ModelOps solution that integrates with GitHub and GitHub Actions—giving your team one-click provisioning of a fully functional ML environment.

Optimizing LLM inference on Amazon SageMaker AI with BentoML’s LLM- Optimizer
In this post, we demonstrate how to optimize large language model (LLM) inference on Amazon SageMaker AI using BentoML’s LLM-Optimizer to systematically identify the best serving configurations for your workload.
Train custom computer vision defect detection model using Amazon SageMaker
In this post, we demonstrate how to migrate computer vision workloads from Amazon Lookout for Vision to Amazon SageMaker AI by training custom defect detection models using pre-trained models available on AWS Marketplace. We provide step-by-step guidance on labeling datasets with SageMaker Ground Truth, training models with flexible hyperparameter configurations, and deploying them for real-time or batch inference—giving you greater control and flexibility for automated quality inspection use cases.
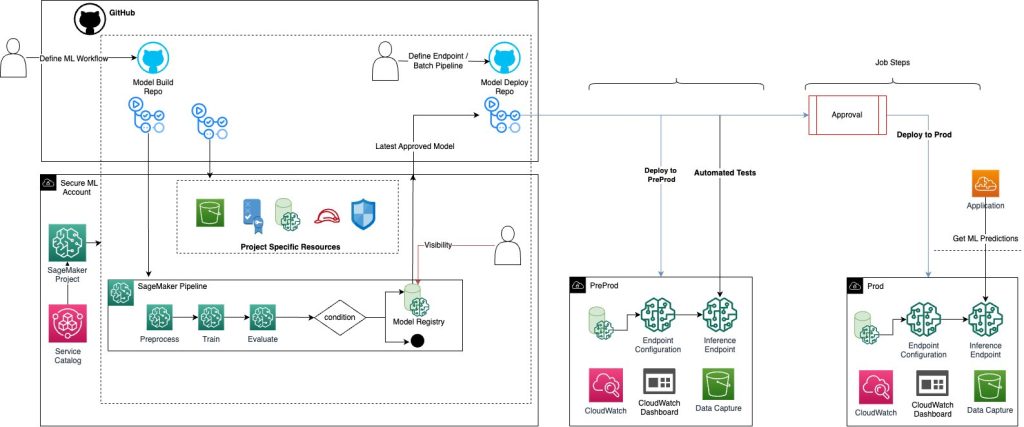
Implement a secure MLOps platform based on Terraform and GitHub
Machine learning operations (MLOps) is the combination of people, processes, and technology to productionize ML use cases efficiently. To achieve this, enterprise customers must develop MLOps platforms to support reproducibility, robustness, and end-to-end observability of the ML use case’s lifecycle. Those platforms are based on a multi-account setup by adopting strict security constraints, development best […]