Artificial Intelligence
Tag: Amazon SageMaker

Scale LLM fine-tuning with Hugging Face and Amazon SageMaker AI
In this post, we show how this integrated approach transforms enterprise LLM fine-tuning from a complex, resource-intensive challenge into a streamlined, scalable solution for achieving better model performance in domain-specific applications.

Evaluate generative AI models with an Amazon Nova rubric-based LLM judge on Amazon SageMaker AI (Part 2)
In this post, we explore the Amazon Nova rubric-based judge feature: what a rubric-based judge is, how the judge is trained, what metrics to consider, and how to calibrate the judge. We chare notebook code of the Amazon Nova rubric-based LLM-as-a-judge methodology to evaluate and compare the outputs of two different LLMs using SageMaker training jobs.

Simplify ModelOps with Amazon SageMaker AI Projects using Amazon S3-based templates
This post explores how you can use Amazon S3-based templates to simplify ModelOps workflows, walk through the key benefits compared to using Service Catalog approaches, and demonstrates how to create a custom ModelOps solution that integrates with GitHub and GitHub Actions—giving your team one-click provisioning of a fully functional ML environment.

Optimizing LLM inference on Amazon SageMaker AI with BentoML’s LLM- Optimizer
In this post, we demonstrate how to optimize large language model (LLM) inference on Amazon SageMaker AI using BentoML’s LLM-Optimizer to systematically identify the best serving configurations for your workload.
Train custom computer vision defect detection model using Amazon SageMaker
In this post, we demonstrate how to migrate computer vision workloads from Amazon Lookout for Vision to Amazon SageMaker AI by training custom defect detection models using pre-trained models available on AWS Marketplace. We provide step-by-step guidance on labeling datasets with SageMaker Ground Truth, training models with flexible hyperparameter configurations, and deploying them for real-time or batch inference—giving you greater control and flexibility for automated quality inspection use cases.
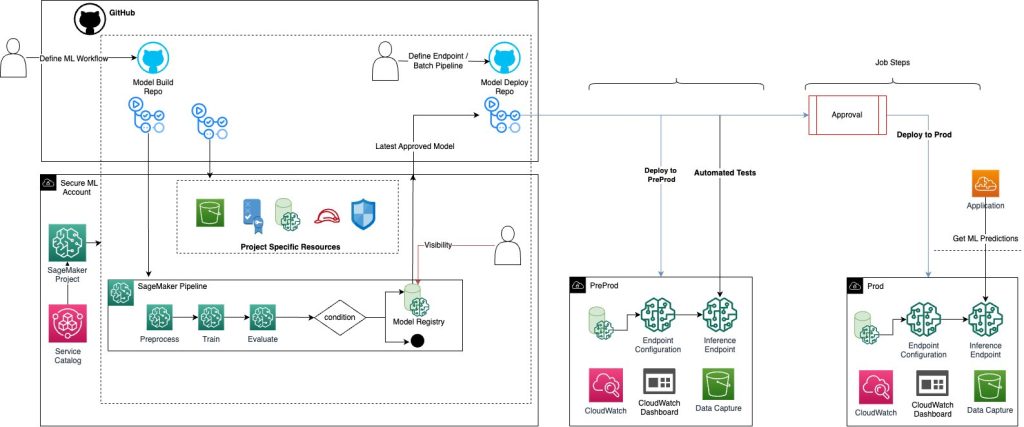
Implement a secure MLOps platform based on Terraform and GitHub
Machine learning operations (MLOps) is the combination of people, processes, and technology to productionize ML use cases efficiently. To achieve this, enterprise customers must develop MLOps platforms to support reproducibility, robustness, and end-to-end observability of the ML use case’s lifecycle. Those platforms are based on a multi-account setup by adopting strict security constraints, development best […]
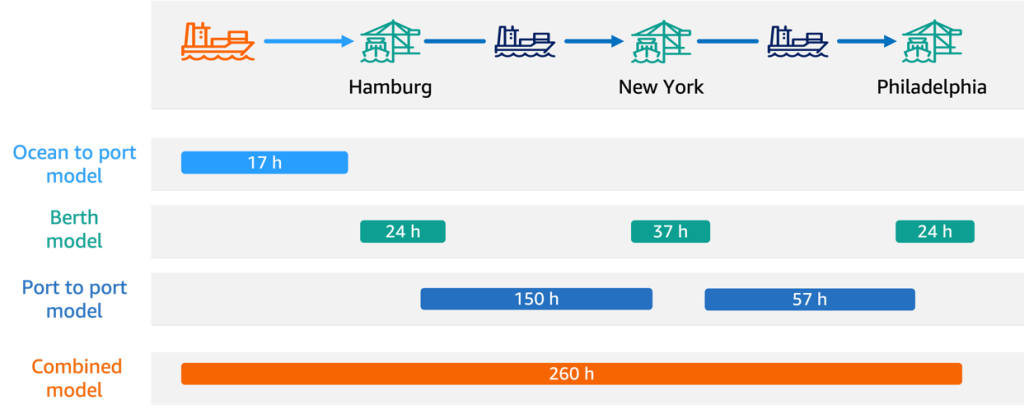
How Hapag-Lloyd improved schedule reliability with ML-powered vessel schedule predictions using Amazon SageMaker
In this post, we share how Hapag-Lloyd developed and implemented a machine learning (ML)-powered assistant predicting vessel arrival and departure times that revolutionizes their schedule planning. By using Amazon SageMaker AI and implementing robust MLOps practices, Hapag-Lloyd has enhanced its schedule reliability—a key performance indicator in the industry and quality promise to their customers.

Scale visual production using Stability AI Image Services in Amazon Bedrock
This post was written with Alex Gnibus of Stability AI. Stability AI Image Services are now available in Amazon Bedrock, offering ready-to-use media editing capabilities delivered through the Amazon Bedrock API. These image editing tools expand on the capabilities of Stability AI’s Stable Diffusion 3.5 models (SD3.5) and Stable Image Core and Ultra models, which […]
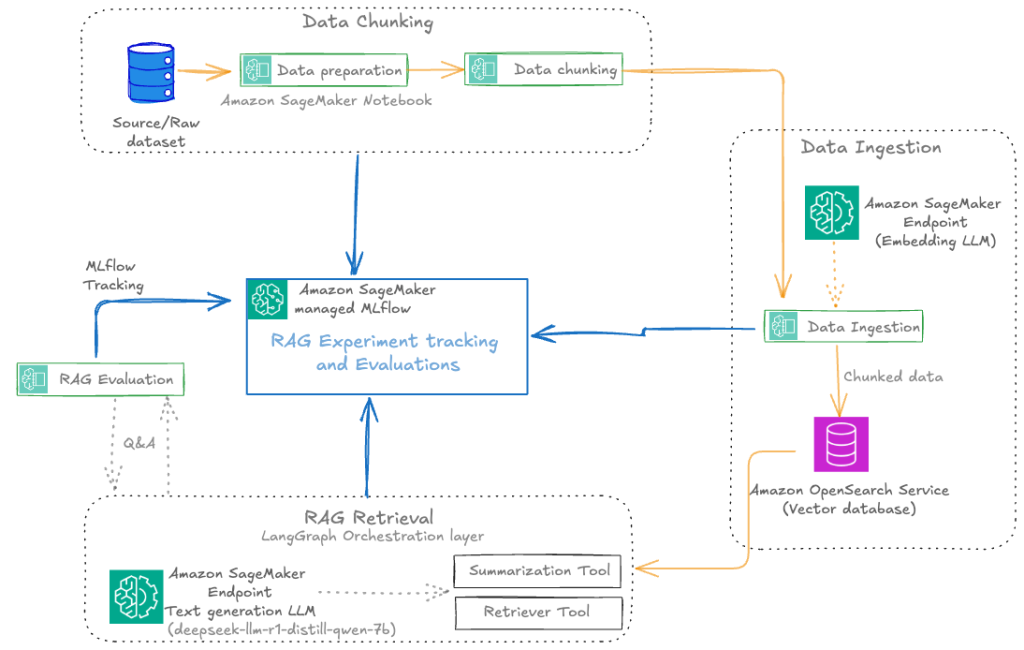
Automate advanced agentic RAG pipeline with Amazon SageMaker AI
In this post, we walk through how to streamline your RAG development lifecycle from experimentation to automation, helping you operationalize your RAG solution for production deployments with Amazon SageMaker AI, helping your team experiment efficiently, collaborate effectively, and drive continuous improvement.

Build character consistent storyboards using Amazon Nova in Amazon Bedrock – Part 1
The art of storyboarding stands as the cornerstone of modern content creation, weaving its essential role through filmmaking, animation, advertising, and UX design. Though traditionally, creators have relied on hand-drawn sequential illustrations to map their narratives, today’s AI foundation models (FMs) are transforming this landscape. FMs like Amazon Nova Canvas and Amazon Nova Reel offer […]