Artificial Intelligence
Tag: Amazon SageMaker

Build a news-based real-time alert system with Twitter, Amazon SageMaker, and Hugging Face
Today, social media is a huge source of news. Users rely on platforms like Facebook and Twitter to consume news. For certain industries such as insurance companies, first respondents, law enforcement, and government agencies, being able to quickly process news about relevant events occurring can help them take action while these events are still unfolding. […]

Use Amazon SageMaker Data Wrangler in Amazon SageMaker Studio with a default lifecycle configuration
If you use the default lifecycle configuration for your domain or user profile in Amazon SageMaker Studio and use Amazon SageMaker Data Wrangler for data preparation, then this post is for you. In this post, we show how you can create a Data Wrangler flow and use it for data preparation in a Studio environment […]

Predict types of machine failures with no-code machine learning using Amazon SageMaker Canvas
Predicting common machine failure types is critical in manufacturing industries. Given a set of characteristics of a product that is tied to a given type of failure, you can develop a model that can predict the failure type when you feed those attributes to a machine learning (ML) model. ML can help with insights, but […]

Demystifying machine learning at the edge through real use cases
October 2023: Starting in April 26th, 2024, you can no longer access Amazon SageMaker Edge Manager. For more information about continuing to deploy your models to edge devices, see SageMaker Edge Manager end of life. Edge is a term that refers to a location, far from the cloud or a big data center, where you […]

How InfoJobs (Adevinta) improves NLP model prediction performance with AWS Inferentia and Amazon SageMaker
This is a guest post co-written by Juan Francisco Fernandez, ML Engineer in Adevinta Spain, and AWS AI/ML Specialist Solutions Architects Antonio Rodriguez and João Moura. InfoJobs, a subsidiary company of the Adevinta group, provides the perfect match between candidates looking for their next job position and employers looking for the best hire for the […]

Build a mental health machine learning risk model using Amazon SageMaker Data Wrangler
This post is co-written by Shibangi Saha, Data Scientist, and Graciela Kravtzov, Co-Founder and CTO, of Equilibrium Point. Many individuals are experiencing new symptoms of mental illness, such as stress, anxiety, depression, substance use, and post-traumatic stress disorder (PTSD). According to Kaiser Family Foundation, about half of adults (47%) nationwide have reported negative mental health […]

Build, Share, Deploy: how business analysts and data scientists achieve faster time-to-market using no-code ML and Amazon SageMaker Canvas
April 2023: This post was reviewed and updated with Amazon SageMaker Canvas’s new features and UI changes. Machine learning (ML) helps organizations increase revenue, drive business growth, and reduce cost by optimizing core business functions across multiple verticals, such as demand forecasting, credit scoring, pricing, predicting customer churn, identifying next best offers, predicting late shipments, […]

Make batch predictions with Amazon SageMaker Autopilot
March 2025: This post was reviewed and updated for accuracy. Amazon SageMaker Autopilot is an automated machine learning (AutoML) solution that performs all the tasks you need to complete an end-to-end machine learning (ML) workflow. It explores and prepares your data, applies different algorithms to generate a model, and transparently provides model insights and explainability […]

Prepare time series data with Amazon SageMaker Data Wrangler
Time series data is widely present in our lives. Stock prices, house prices, weather information, and sales data captured over time are just a few examples. As businesses increasingly look for new ways to gain meaningful insights from time-series data, the ability to visualize data and apply desired transformations are fundamental steps. However, time-series data […]
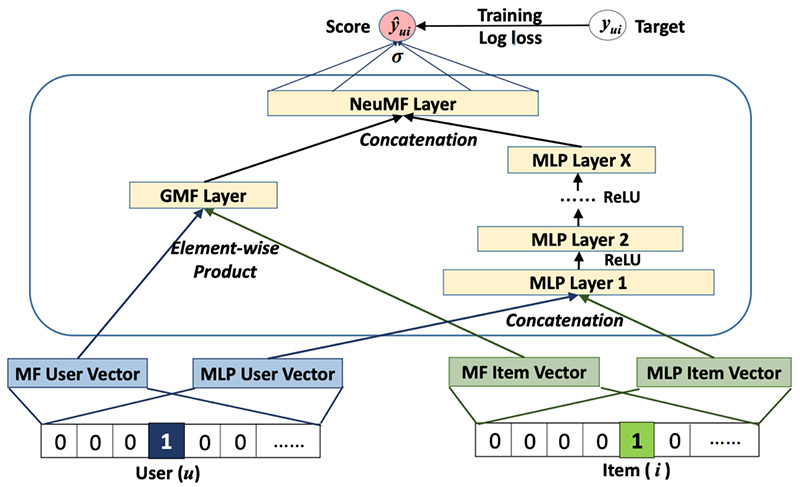
Building a customized recommender system in Amazon SageMaker
Recommender systems help you tailor customer experiences on online platforms. Amazon Personalize is an artificial intelligence and machine learning service that specializes in developing recommender system solutions. It automatically examines the data, performs feature and algorithm selection, optimizes the model based on your data, and deploys and hosts the model for real-time recommendation inference. However, […]