Front-End Web & Mobile
Building a GraphQL API with Java and AWS Lambda
Modern applications are driven by rich UI experience. GraphQL APIs are gaining popularity with developers and teams of all sizes as an alternative to REST APIs to support these applications. AWS Lambda is a serverless, event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers. AWS AppSync is a fully-managed service that makes it easy to develop GraphQL APIs by handling the heavy lifting of securely connecting to data sources, such as Amazon DynamoDB, Lambda, and more.
This post will demonstrate different options for resolving GraphQL queries using serverless technologies on AWS. In the following sections, you’ll see how Lambda can be used as a compute platform to run a fully-functional GraphQL API. We’ll compare this approach to running GraphQL API using AWS AppSync.
Sample application
A sample application that demonstrates the options laid out in this post is available at this Github location. Throughout this post and in the code samples, Java is used as a programming language. You can implement the same approach using other languages and corresponding libraries and packages available in those languages.
For the purpose of this post, we’ll use a sample GraphQL application that tracks posts and comments on those posts. The GraphQL schema for this sample application is as follows:
Option 1: GraphQL API on Lambda
In this approach, Lambda is used as a compute layer to host a fully-functional GraphQL service. The following diagram illustrates this architecture. Amazon API Gateway provides an HTTPS entry point into the GraphQL application running on Lambda. A relational database running on Amazon Aurora MySQL cluster is used to serve as the backend data store for the application. The Lambda function connects to the Aurora MySQL cluster via Amazon RDS Proxy. Amazon RDS Proxy is a fully-managed, highly available database proxy for Amazon Relational Database Service (Amazon RDS) that makes applications more scalable, more resilient to database failures, and more secure. The following diagram illustrates the architecture for this approach.

Figure 1. Architecture diagram showing Amazon API Gateway connected to AWS Lambda which is connected to Aurora MySQL using RDS Proxy
With this approach, customers must maintain code that runs the GraphQL API and are responsible for all of the complexity that comes with managing your own software, such as handling library upgrades, securely connecting to the data sources, etc.
However, this option gives you the most control and flexibility while implementing different aspects of the API. For example, you have different choices for resolving the N+1 (more on this in following sections) problem. In addition, you can implement advanced features, such as custom scalars and instument your GraphQL API calls.
GraphQL implementation
The Lambda function uses graphql-java, a popular library for implementing GraphQL with java. Data fetchers are used in graphql-java to fetch data (or do updates in the case of Mutations) for each of the fields defined in the schema. Each field is associated with a graphql.schema.DataFetcher object. By default, all of the fields are associated with graphql.schema.PropertyDataFetcher. PropertyDataFetcher uses standard patterns for fetching object values. It supports either a POJO or Map as the backing object. However, some fields may be associated with a specialized DataFetcher class that can retrieve data from other sources, such as a relational database like in the example provided.
Example code that returns a custom DataFetcher:
Option 2: AWS AppSync with lambda resolver
AWS AppSync is a fully-managed service that makes it easy to develop GraphQL APIs by handling the heavy lifting of securely connecting to multiple data sources. One of the types of data sources you can configure is a Lambda function. These Lambda functions are called Lambda Resolvers. With this option, AWS AppSync is used to host the GraphQL API. Clients interact with the API using the GraphQL endpoint exposed by AppSync. Lambda resolver functions provide only the business logic to resolve GraphQL queries and mutations.
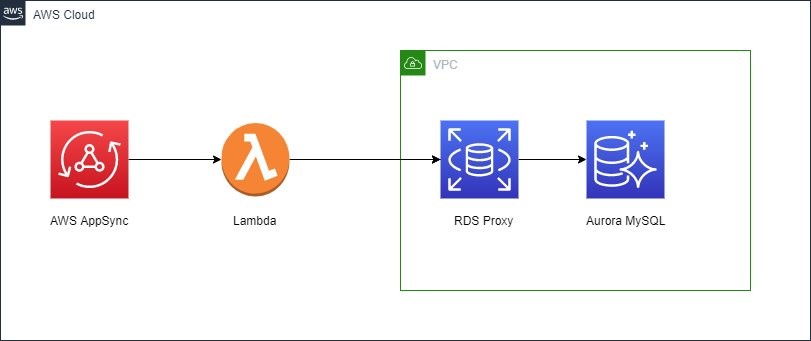
Figure 2. Architecture diagram showing AWS AppSync connected to AWS Lambda which is connected to Aurora MySQL using RDS Proxy
Example Lambda data source:

Figure 3. Screenshot showing an example Lambda Data source in AppSync Console
Once the data source is defined, it can be used to resolve Queries and Mutations in the schema. An example Query resolver looks like the following:

Figure 4. Screenshot showing Direct Lambda Resolver configuration for createPost Mutation
There’s less complexity of managing and hosting your own API. AWS AppSync fully manages the GraphQL API and Lambda resolvers encapsulate the business logic needed to resolve the GraphQL queries. Direct Lambda Resolvers let you circumvent the use of VTL mapping templates when using Lambda data sources. AWS AppSync can provide a default payload to your Lambda function as well as a default translation from a Lambda function’s response to a GraphQL type. You can choose to provide a request template, a response template, or neither, and AWS AppSync will handle it accordingly.
Additionally, you can break out your business logic into multiple Lambda functions and attach different Lambda resolvers to different fields in the schema. This leads to a more modular and microservices approach toward maintaining your business logic.
Option 3: AWS AppSync with Amazon RDS resolver
In this approach, AWS AppSync communicates with the Aurora serverless V1 database directly using Data API. The resolvers attached to the fields use an Amazon RDS data source to perform queries and mutations.

Figure 5. Architecture Diagram showing AWS AppSync integration with Aurora Serverless using Data API
Define the data source:

Field resolvers use direct SQL statements to resolve the queries and mutations. See the following example:
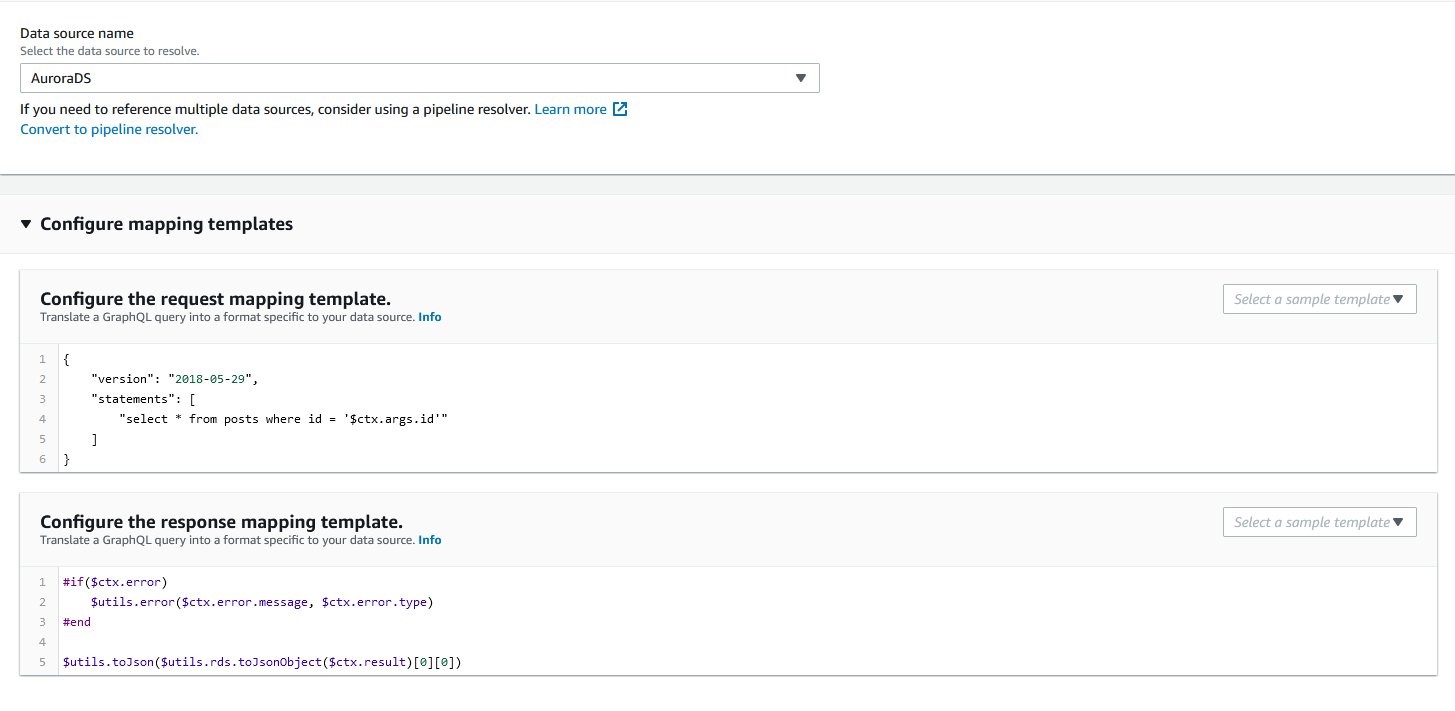
With this approach, customers have a very low burden of maintaining code compared to the other two options. They connect to a relation data store and use familiar SQL language and process the results using velocity templates.
N+1 problem and batch loading
The N+1 problem can occur in a GraphQL system when one top-level query produces N items whose type contains a field that must also be resolved. For example, in the following query, getPostsByAuthor returns N items, and each item has a comments field that must be resolved in turn. This yields N more queries for each Author returned. This problem can get more complex if there are multiple levels of nesting, and it will have a major impact on the performance of the GraphQL API.
One way to resolve this problem is by using batch loading or batching. Batching is a process of taking a group of requests and combining them into one, then making a single request with the same data that all of the other queries would have made. Let’s look at how this problem can be addressed using Options 1 and 2.
In Option 1, the graphql-java library uses dataloader to effectively solve the N+1 problem. Alternatively, note that other approaches like Field Selection can be used to solve the N+1 issue. The following code snippets show how this can be resolved using dataloader.
In Option 2, AWS AppSync with Lambda resolver batch loading is supported by enabling batching and specifying the batch size as shown in the following. You can also control the batch size by specifying the maximum batching size. AWS AppSync API will send a list of source objects as part of the payload to the backend Lambda resolver function. The backend function can use this list to batch load the required fields thus preventing multiple network calls.

Real-time GraphQL Subscriptions
Subscriptions are a GraphQL feature that allows the server to send real-time events to its clients. Many GraphQL applications like chat and messaging applications leverage this feature.
With Options 2 and 3, managing subscriptions is handled by AWS AppSync. AWS Appsync provides a real-time endpoint that can be used by WebSocket clients to subscribe to notifications. You don’t need to write any code to implement subscriptions. To enable subscriptions to the example schema above, you must modify the schema to add the following:
The clients can subscribe to the subscriptions with the following GraphQL query as an example:
In a self-managed GraphQL implementation described in Option 1 above, customers have to implement their own subscription mechanisms such as leveraging WebSocket with API Gateway. Managing subscriptions when running the GraphQL API inside of a Lambda function becomes challenging due to the ephemeral nature of Lambda functions. You must leverage external data stores such as DynamoDB to track active subscriptions.
Deploying and testing the sample application
A sample application that demonstrates the options laid out in this post is available at this Github location. The following are prerequisites for running this application:
- AWS Account
- AWS Cloud Development Kit (AWS CDK)
- Java 11 or above
- Maven
Follow the detailed instructions in the README to deploy and test the application.
Cleanup
In the sample code, navigate to the cdk-app folder and run the following to destroy the resources created for this post:
Conclusion
In this post, we’ve seen three options for running a GraphQL application on AWS using serverless technologies. The first option illustrates how to run a self-managed GraphQL application using API Gateway and Lambda services. Options 2 and 3 showcase how a fully-managed GraphQL application can be run using AWS AppSync. Although the self-managed option gives you more control over how to implement certain aspects of the GraphQL application, it also brings in the complexity of managing custom code. With AWS Appsync different aspects of implementing GraphQL API are transparent to you. You can focus on writing your business logic while AWS does the heavy lifting of running the API for you. This difference becomes more pronounced when writing applications that use advanced features such as batch loading and real-time subscriptions.
You should carefully weigh the pros and cons of the approaches laid out in this post, and you should move forward according to the characteristics of your workload and your team’s tolerance for managing code.
About the authors: