AWS Cloud Operations Blog
Analyzing Bitcoin Data: AWS CloudFormation Support for AWS Glue
The AWS CloudFormation team has been busy in the last couple of months, adding support for new resource types for recently released AWS services. In this post, I take a deep dive into using AWS Glue with CloudFormation.
About AWS Glue
AWS Glue was first announced at re:Invent in 2016, and was made generally available in August 2017. AWS Glue is a serverless extract, transform and load (ETL) service. ETL is a critical step in operationalizing data analytics, since data cleansing and reformatting is almost always necessary when creating everything from data marts, warehouses, data lakes, machine learning algorithms, metrics dashboards, operational reports, and many other data science projects.
Data science projects can be very time-consuming from an experimentation and discovery perspective. When a promising candidate project emerges, implementing the necessary production compute and storage resources can cause significant delays. It’s necessary that the business leverage the resources in a repeatable and ongoing basis.
Analyzing historical price data for bitcoin: Planning
Your company wants to pursue a new service relating to cryptocurrency analysis, and your IT team gets asked to produce a database with historical price information for bitcoin, to feed other analysis processes. Rather than require a significant upfront investment in building the database and the necessary tooling for ongoing analysis and model development, you can leverage AWS Glue and open source development tools like Apache Spark, Python and Apache Zeppelin to enable quick experimentation and further product development. Further, you want to automate the operationalization of this data analysis platform as quickly as possible, and AWS CloudFormation helps with this automation.
Start with getting historical bitcoin price data. You can choose to consume the data directly from currency exchanges, or you can find an existing dataset that includes past data. There are many sources of public data sets for such projects, as outlined in 18 places to find data sets for data science projects. One of my favorite sources for such data sets is Kaggle, where you can also learn from other scientists’ projects and findings, as well as participate in data science competitions sponsored by companies and academic institutions.
The dataset from the Bitcoin Historical Data page will fit our needs (see Figure 1 below); it includes historical data from January 2012 to today, from several exchanges.
Figure 1. A sample of the CSV data provided for the coinbase exchange.
Setting up our Bitcoin Price Database
- If you’ve never used Kaggle, you are asked to set up a free account.
- Download the data as a zip file from Bitcoin Historical Data.
- Expand the zip file locally and locate the file for the coinbase exchange.
- Set up an Amazon S3 bucket and put the file there.
Armed with this data, now get the data to a point that you can inspect it, query it, and plan for further development and experiments.
- Create a new file in your favorite editor.
- Copy and paste the following CloudFormation template into the file (see Figure 2 below).
- Save it, and create a new stack with the console (I used the US East N. Virginia region), the CLI, or the API.
---
#===============================================================================
# Template: CoinbaseCrawler.yaml
#
# Purpose: Creates resources to populate bitcoin historical data from
# the Coinbase exchange into an AWS Glue Catalog
#===============================================================================
AWSTemplateFormatVersion: "2010-09-09"
Description: "Populate Bitcoin historical data from Coinbase into AWS Glue"
Resources:
#=============================================================================
# IAM Role and Policies for AWS Glue. Reusable across other ETL crawlers
#=============================================================================
ETLRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
-
Effect: "Allow"
Principal:
Service:
- "glue.amazonaws.com"
Action:
- "sts:AssumeRole"
Path: "/"
Policies:
-
PolicyName: "root"
PolicyDocument:
Version: "2012-10-17"
Statement:
-
Effect: "Allow"
Action: "*"
Resource: "*"
#=============================================================================
# BitcoinPriceDB: May reuse it if we want to compare data from other
# exchanges, like bitflyer, coincheck, and bitstamp
#=============================================================================
BitcoinPriceDB:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: "bitcoin-price-db"
Description: "Historical Bitcoin Price Data"
#=============================================================================
# CoinbaseCrawler: Grab data from the coinbase csv into the BitcoinPriceDB
# NOTE: You MUST change the S3 Targets Path to point to your own bucket and
# folder!!!
#=============================================================================
CoinbaseCrawler:
Type: AWS::Glue::Crawler
Properties:
Name: "coinbase-crawler"
Description: "Populate table with Bitcoin historical data from Coinbase"
Role: !GetAtt ETLRole.Arn
DatabaseName: !Ref BitcoinPriceDB
TablePrefix: "coinbase_"
Targets:
S3Targets:
- Path: s3://cfnda-bitcoin-historical-data/coinbase
SchemaChangePolicy:
UpdateBehavior: "UPDATE_IN_DATABASE"
DeleteBehavior: "DEPRECATE_IN_DATABASE"
Schedule:
ScheduleExpression: "cron(0/5 * ? * MON-FRI *)"
Figure 2. The CloudFormation template for the AWS Glue crawler from bitcoin data.
You set up everything with CloudFormation early in the process, so eventually operationalizing the solution in a production environment becomes fast and repeatable. The template helps you:
- Designate S3 as the storage data lake
- Create an IAM role to use AWS Glue
- Extract the data
- Create a database
- Load the data into a table that you can query with Amazon Athena or later visualize with Amazon QuickSight.
Note the following from the template code:
- The template creates the minimal resources for setting up your database. This include the IAM role (ETLRole in the code example), the database itself, which can be used in Athena or QuickSight for further analysis, and the crawler. The crawler does the work of extracting the data from the CSV file that you downloaded and populates the table in the database.
- When creating the database (BitcoinPriceDB in the code example), ensure that you only use lowercase characters in the string for the Database Input/Name attribute (bitcoin-price-db, in the code example).
- For the crawler, specify your bucket in the Targets/S3Targets/Path attribute (s3://cfnda-bitcoin-historical-data/coinbase in the code example). Put your own bucket and folder path where you uploaded your copy of the coinbase file that you got from Kaggle in the previous steps.
- For this example, the template sets up a schedule for the crawler to run every five minutes on weekdays. For your experiment, you may either omit the Schedule/ScheduleExpression stanza and run the crawler manually from the AWS Glue console, or use your own cron expression (see some examples in Time-Based Schedules for Jobs and Crawlers,keeping in mind that you are charged per the rates on AWS Glue Pricing).
- For this quick example, it makes sense to put everything in one template, with the benefit of quickly deleting all resources by deleting the stack. For a long-term project, you may want to create these resources in separate templates, as you only need to create the role and database one time. To look at the data from the other bitcoin exchanges provided in the Kaggle dataset, reuse the crawler code in separate templates and stacks for biflyer, coincheck, and bit stamp, which are also provided in the same dataset.
After creating the stack, which should take about 40 seconds, check the AWS Glue console where your database and crawler show up on the respective lists immediately. After the crawler runs (in about 5 minutes, per your scheduled cron expression), the table also shows up. After the table creation is complete, you can view the schema from the AWS Glue console (see Figure 3), or execute SQL queries against it using the Athena console (see Figure 4).
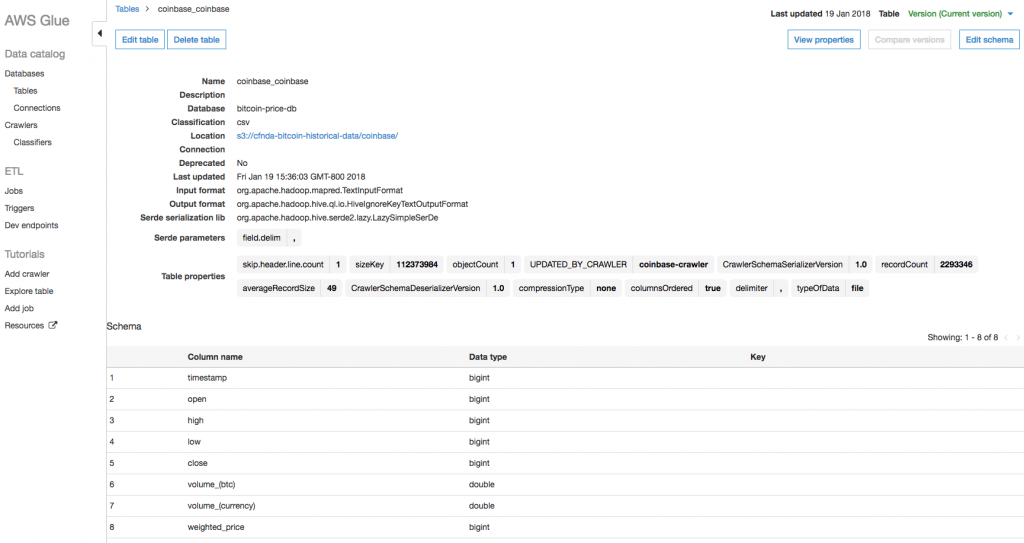
Figure 3. Schema for the coinbase historical pricing table, created with the AWS Glue crawler.

Figure 4. Sample query results from the coinbase historical pricing table, using the Athena Query Editor.
Suggested next steps
Now that you’ve figured out how to ingest the data to a place where you can query it, you can begin to compare the data with other exchanges from the dataset. You can also merge it with other data, reformat the data to make it easier to consume, and further enable data experiments.
For example, maybe you want to merge the data with other events or logs, but those events lack enough structure to build tables from them and join them with your existing tables. Using AWS Glue classifiers, you can use grok expressions to add structure to these additional data sources.
Another example that considers the current data schema would be transforming the UNIX time format field to a conventional date field. AWS Glue allows for the creation of jobs that can do such transforms on fields. It also allows you to use PySpark (Python-based Spark scripts) to do such transformations. You can later operationalize those scripts as jobs in AWS Glue, and have them run periodically or based on a trigger, perhaps to get updated data.
You can write and debug your own scripts, from your local IDE, by creating development endpoints in AWS Glue. Further, you can develop scripts and conduct experiments using Apache Zeppelin notebooks, deploying a server with the Zeppelin software ready to use. Not surprisingly, AWS Glue uses CloudFormation to deploy these Zeppelin servers. For more information about setting up your local IDE, see Tutorial: Set Up PyCharm Professional with a Development Endpoint to link your AWS Glue endpoint with JetBrains’ PyCharm Professional, or see Tutorial: Set Up an Apache Zeppelin Notebook on Amazon EC2 on how to create a Zeppelin notebook server on an Amazon EC2 instance right from the AWS Glue console, using CloudFormation to deploy the server.
Visit the CloudFormation details page and CloudFormation documentation for more information, as well as the full list of supported resources.
About the Author
 |
Luis Colon is a Senior Developer Advocate for the AWS CloudFormation team. He works with customers and internal development teams to focus on and improve the developer experience for CloudFormation users. In his spare time, he mixes progressive trance music.
|