Networking & Content Delivery
Choosing the right health check with Elastic Load Balancing and EC2 Auto Scaling
Customers frequently use Elastic Load Balancing (ELB) load balancers and Amazon EC2 Auto Scaling groups (ASG) to build scalable, resilient workloads. When configured correctly, Amazon ELB health checks help make your workload more resilient to failures in your workload components behind the load balancer. However, you may need to make tradeoffs for handling different failure scenarios depending on how you implement the health checks and whether they are added to the ASG.
This post provides prescriptive guidance on the use cases for different types of health checks and whether they should be added to the ASG. It also describes how they can make your workload more resilient to specific failure conditions, as well as the additional scenarios where you may need to build your own resilience tools to mitigate failures.
Health check strategies
By default, an ASG only uses EC2 instance status checks to determine instance health. These status checks identify failure conditions, such as a loss of network connectivity, loss of system power, exhausted memory, or an incompatible kernel. They don’t monitor what’s happening inside the instance (such as the health of the software, operating system, or file system), or its ability to interact with external dependencies. You can also add the ELB health checks to your registered Auto Scaling group. Adding a load balancer’s health checks to the ASG allows EC2 Auto Scaling to automatically replace instances that fail either their Amazon Elastic Compute Cloud (Amazon EC2) status checks or the Amazon ELB health checks.
There are three strategies to measure instance health: liveness checks, local health checks, and dependency health checks. The Amazon Builders’ Library article on Implementing health checks provides more details. Examples of liveness checks are the EC2 instance status checks and the passive health checks performed by Network Load Balancers (NLB). However, you typically want to know more about instance health than just its ability to respond to something like a ping. To get a better picture of the true health of the instance, you should configure the active ELB health checks as either local health checks, which are called shallow in this post, or dependency health checks, which are called deep in this post. Shallow health checks only make “on-box” checks that do things like make sure the critical processes and agents are running, the correct behavior of the software, or the health of the file system. Deep health checks include both shallow health checks and test interactions with “off-box” dependencies such as resolving DNS records, querying a database, or sending data to a downstream service.
The following sections evaluate the pros and cons of using shallow and deep health checks from a load balancer, the impacts of adding them to your ASG, identifying the tradeoffs of each combination, and the use cases that are best addressed by specific combinations based on your needs assessment.
Using shallow health checks
Shallow health checks monitor the health of the local instance, such as making sure that critical processes are running, file system health, and the correct behavior of the deployed software. The instance returns a successful HTTP response to the health check if everything local to that instance appears healthy. Let’s look at using a shallow health check that is added to the ASG.
Scenario 1: Using a shallow health check that is added to the ASG
In this configuration, when a local failure occurs, both ELB and EC2 Auto Scaling detect the failure, stop routing traffic to the instance, and replace it. Adding the shallow health checks to the ASG allows EC2 Auto Scaling to get a better view of the local instance health. Additionally, transient failures of dependencies won’t cause instances to be terminated in this approach. These are both good things. Generally, there’s no reason to not add shallow health checks from your load balancer to your ASG. It’s almost always beneficial and safe for EC2 Auto Scaling to have that improved observability.
However, there are tradeoffs with shallow health checks. They don’t allow the system to automatically route around failures caused by external dependencies, especially situations like single Availability Zone (AZ) gray failures. When these situations occur, the load balancer observes all of its targets as healthy even though they may be returning errors to your customers. This is the tradeoff you make between shallow and deep health checks, which is shown in the following diagram (Figure 1).

Figure 1 – Shallow health checks don’t allow ELB to route around gray failures or dependency failures
To route around instances experiencing a single AZ gray failure, you could evacuate the AZ using a service like zonal shift. For details on building the observability and mitigation patterns required for detecting and mitigating single AZ gray failures, refer to the Advanced Multi-AZ Resilience Patterns white paper. During transient dependency failures, you can implement patterns like graceful degradation or backoff and retry to mitigate their effects. Alternatively, you can implement deep health checks to help route around dependency impairments. Let’s look at how those can help, and the tradeoffs you must make.
Using deep health checks
Deep health checks check both the local instance health as well as the health of interactions with external dependencies that you define, such as databases or external APIs. When you use deep health checks, transient impairments of external dependencies can make a load balancer target appear unhealthy. This is useful for routing around instances that are impacted by the dependency’s transient failure. However, whether you add the health check to your ASG can result in different outcomes, so let’s look at both scenarios.
Scenario 2: Using deep health checks that aren’t added to the ASG
In this example, let’s imagine that a network degradation gray failure causes 20% of the queries from instances in AZ 1 to the database in AZ 2 to time out. The following diagram (Figure 2) shows how the health check flows.
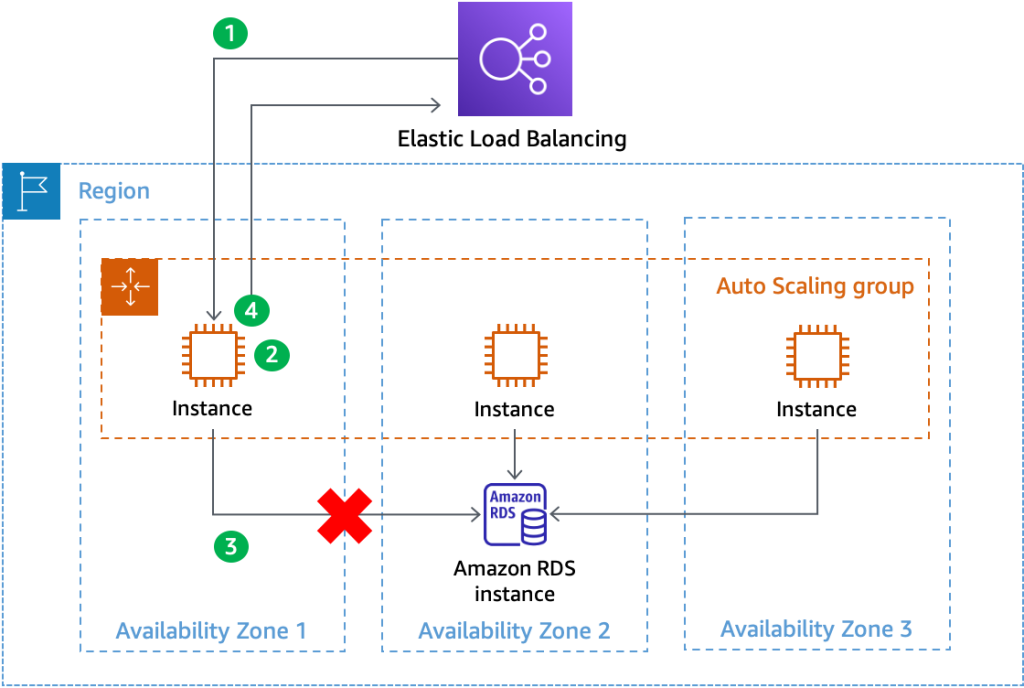
Figure 2 – Using deep health checks to route around AZ gray failures
- The ELB sends a HTTP GET request to the /health path of the instance’s web application.
- The EC2 instance receives the request and performs its local health check logic.
- The EC2 instance sends a query to the database to make sure that it can connect and retrieve data. The gray failure causes this query to timeout.
- Because the database query failed, the instance responds to the health check with an HTTP 500 response and fails the health check.
Once the instance fails enough consecutive health checks, the load balancer will identify that the EC2 instance is unhealthy and stop routing requests to it. Deep health checks help quickly weight away from the impacted AZ and mitigate any impact that customers were seeing from the impairment. This is a good outcome.
Now let’s suppose that the instance in AZ 1 experiences a local issue, such as the httpd process continually crashing due to a corrupt configuration file. Deep health checks also successfully route around this failure. However, this type of problem is unlikely to resolve itself and the instance can perpetually remain in this failed state. If there’s something systemic causing the local failure, such as a poison pill request that introduces the corruption, then this could happen on multiple instances. From the perspective of EC2 Auto Scaling, the instances are never marked unhealthy because it is only using the EC2 instance status checks. Therefore, they won’t be replaced. In the worst case, this could result in no healthy instances available to service customer requests.
Scenario 3: Adding deep health checks to the ASG
To mitigate the previously described scenario, you might consider adding the load balancer health checks to the ASG. However, this approach has a significant drawback. If there’s a transient error with a dependency, then it could cause every registered target to fail their ELB health checks simultaneously. Although the load balancer will fail open and send traffic to all registered targets, EC2 Auto Scaling sees all instances as unhealthy and begins replacing them, as shown in the following diagram (Figure 3).
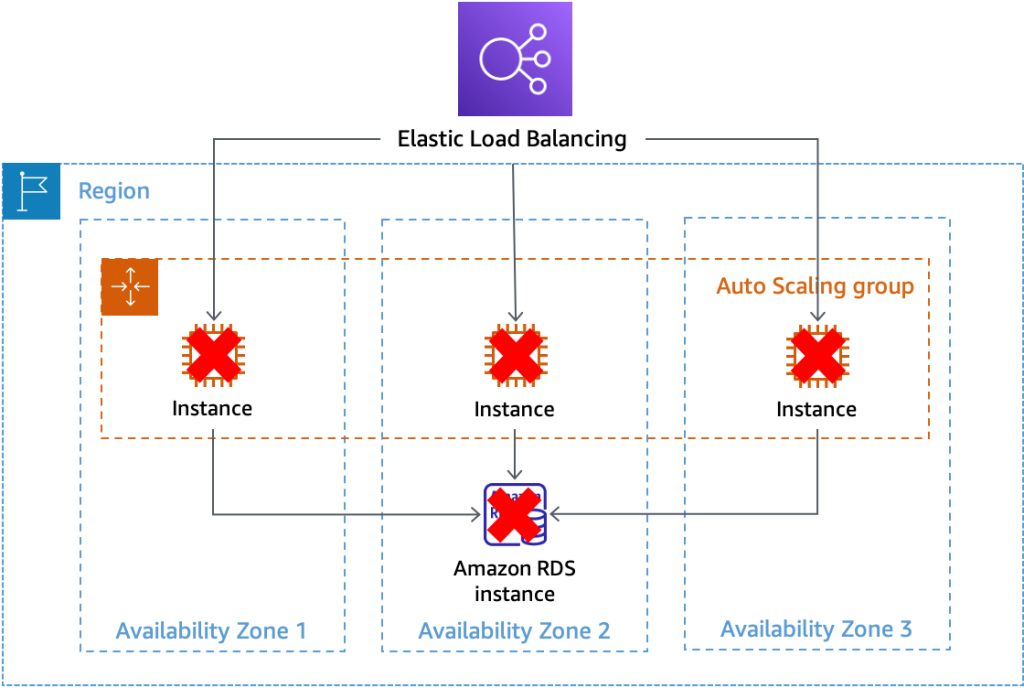
Figure 3 – Deep health checks unnecessarily cause EC2 Auto Scaling to terminate locally healthy instances
When this happens, you must wait for EC2 Auto Scaling to replace all unhealthy instances, and then wait for them to bootstrap and pass health checks before you can restore service. This could take significantly longer than waiting for the transient problem to abate. As a best practice, don’t add “deep” ELB health checks to your ASG. This will prevent the mass termination of your EC2 instance fleet during a dependency failure. This also means there’s a tradeoff: deep health checks from the ELB help route around failure quickly, but EC2 Auto Scaling can’t determine local instance health and replace instances when they’re unhealthy.
Determining local instance health when using deep health checks.
One way to solve this tradeoff and identify and respond to local health problems on instances is using a heartbeat table pattern. Whenever a health check is received from the load balancer, the instance determines local instance health and writes an entry into an Amazon DynamoDB table with the instances’ status and a timestamp. Then, a watcher process, such as an AWS Lambda function running every minute, queries the table looking for entries that either have an unhealthy status or haven’t updated their status in a certain time period, such as five minutes. Whenever an entry matching either of these conditions is found, it manually sets the instance health using the SetInstanceHealth API.
The following diagram (Figure 4) shows three instances reporting their health to a DynamoDB table. The instance in AZ 3 hasn’t reported its status in over five minutes. When the Lambda function executes at 2023-04-02T12:01:00, it observes this lapse in reporting, assumes something has gone wrong locally on the instance, and makes a SetInstanceHealth API call for instance i-5432106789cbafed2 to set it as unhealthy.

Figure 4 – Instances reporting local health to a heartbeat table and a watcher service terminating an instance that hasn’t reported in five minutes
Make sure that you implement velocity control with this type of pattern to prevent a misconfiguration, bug, or unanticipated scenario from causing the watcher service to inadvertently terminate too many instances. For example, you may only allow the watcher service to terminate one instance every minute, and if it tries to terminate more, then it sends an alert to get a human involved.
Summary
This section summarizes the tradeoffs and recommendations for deep and shallow health checks with your load balancer and whether you add them to the ASG.
|
Deep health checks |
Do not add this kind of health check to your ASG. This prevents inadvertent mass termination of your instance fleet. |
|
Quickly route around problems, like gray failures, without replacing instances. |
|
|
This requires an additional tool, like a heartbeat table, to identify instances that aren’t healthy so you can replace them. |
|
|
Shallow health checks |
Always add these to your ASG to replace unhealthy instances. |
|
Prevents replacing instances when there is a transient dependency impairment and quickly routes around instances that are impacted by that failure. |
|
|
Requires building additional mechanisms to route around problems caused by external dependencies, such as single AZ gray failures or networking impairments. |
Neither deep nor shallow health checks are right or wrong. However, each one has use cases that it doesn’t directly support. You should consider which use case is more likely to occur as compared to the cost and effort to build the alternate mechanism.
For example, let’s say you believe that local host failures are much more likely to occur than single AZ gray failures. In that case, you’d want to choose shallow health checks integrated with the ASG. You may conclude that a single AZ gray failure doesn’t present enough risk to warrant building a tool to deal with it, and you can afford to wait out the impact if one does occur. But you might also determine that building the heartbeat table solution is relatively low cost and low effort. This could solve both use cases for only a little extra investment and decide to go with the deep health check option. Finally, you may decide that using deep health checks to route around a gray failure isn’t a comprehensive enough solution, and you want to be in complete control of that mitigation. Therefore, you choose to utilize shallow health checks and build your own AZ evacuation tools.
Conclusion
This post described the differences between shallow and deep health checks that you can implement with a load balancer, the impacts of adding them to your ASG, and the remaining solutions you must create to mitigate certain scenarios. You should be intentional about which pattern you choose to implement with ELB and EC2 Auto Scaling, and understand the tradeoffs. See NLB health checks, ALB health checks, zonal shift, this Well-Architected health checks workshop, and Advanced Multi-AZ Resilience Patterns for more details about the tradeoffs and solutions described in this post.

Michael Haken
Michael is a Principal Solutions Architect on the AWS Strategic Accounts team where he helps customers innovate, differentiate their business, and transform their customer experiences. He has over 15 years’ experience supporting financial services, public sector, and digital native customers. Michael has his B.A. from UVA and M.S. in Computer Science from Johns Hopkins. Outside of work you’ll find him playing with his family and dogs on his farm.