AWS Startups Blog
1mg: Building a Patient Centric Digital Health Repository – Part 2

Guest post by Utkarsh Gupta, Lead Data Scientist, 1mg.com
1mg is an integrated health app that offers an online pharmacy, diagnostics, and consultations at scale in one place. Additionally, the app has a ton of digital health tools, including medicine reminders, digital health records, and much more to make healthcare management easier. Our goal is to provide 360-degree healthcare service in a few clicks.
In part 1 of this series, we discussed the process of setting up a unified data lake within 1mg for traditional analytical purposes. In this post, we will further discuss the usage of this pipeline for large scale machine learning applications along with the strategy to deploy these applications in production. We will conclude by bringing all the building blocks together to generate a patient centric digital health repository on top of the data collected.
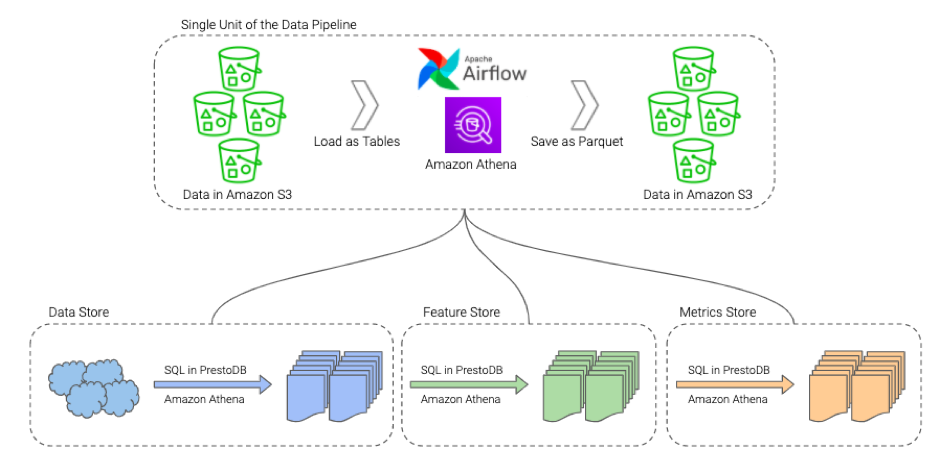
Central Feature Store – Quintessential for scalable Machine Learning
The feature store of unified data lake contains clean, processed and normalized data about various entities like users, prescriptions, conversations, vendors, etc. and is well suited to be the starting point for any data science or machine learning experiment. The feature store can be used by anyone to build and store features.
Features are aggregations of numerical dimensions over one or more facts about a certain entity or entities. Features are calculated for each entity like user or product using its data in a given time period. This means that each feature has an entity ID for which it is calculated like user_id or a product_id and a date period for which it is evaluated. This ID and time range can be used to link a feature back to the data in the data store.
The ETL process runs regularly through a scheduler, which further ensures that these features are computed and updated at a predefined frequency. Amazon Athena CTAS queries are used to compute features from the data store. The Directed Acyclic Graphs (DAGs) of Apache Airflow are used to manage the frequency of these computation queries. The computed features are again stored back in Amazon S3 in an optimized storage format.
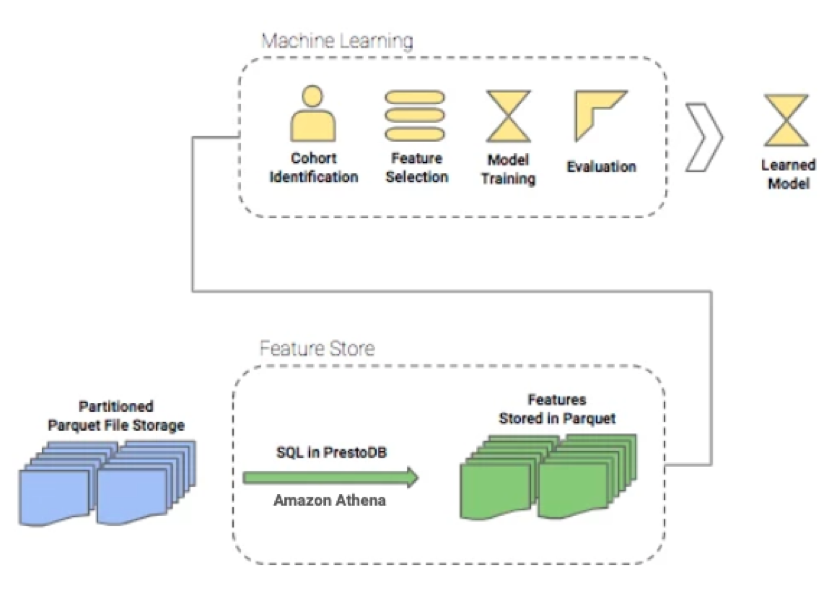
The computed features form the backbone of any machine learning strategy that is required to be implemented. The usual approach for any Machine Learning experiment is typically comprised of following components:
- Problem Identification
- Feature Selection
- Model Training
- Evaluation, and Back testing (if possible)
- Deployment
- Post Deployment Evaluation
The pace of these experiments can be significantly increased if collaboration in feature building and feature re-use for model generation is available. Having a central feature store in our unified data infrastructure allows features to be shared and used in a plug-and-play manner across all machine learning activities. Another benefit from having such a system is that the same set of features would be used in training and during inference, making it work seamlessly when deployed in production. Approved Features are either used directly for offline training & back-testing of model results or can be scheduled for calculation and load into a Cassandra database for online & real-time inferences.
Deployment Strategies
Taking a learned model to production where its predictions are used in a live setting is a data scientist’s dream. Depending on the problem at hand and the solution proposed, the choice of type of deployment may vary. However, there are primarily three types of strategies that we can choose from –
- Stand-Alone Deployment: This is the simplest form of deployment which is stateless in nature. All the feature generation requirements are fulfilled by the client service, and the model is used to make predictions in real time. There are no dependencies with any other system or services and thus it can be horizontally scaled easily.
- Deployment for Batch Inference: When model inference is slightly time-consuming and complex features need to be used, we prefer batching the inference process. This is usually the case for models like collaborative filtering, where the matrix factorization can take a lot of time. feature store is used to get required features for a batch and model inferences are done offline. These predictions are then Cached and loaded and used as it is by the client service.
- Deployment for Real Time Inference: While this concept of deploying a model is similar to stand-alone deployment, the feature requirement is fulfilled using an online feature store, which can supply the required features to the model in real time. For this, we use a Cassandra database to store the features for various entities like users, vendors, and orders, and the data can be fetched at runtime using the unique entity identifiers.

Putting it all Together to Build a Patient Repository
A typical 1mg user would have lots of raw data, which is not only relevant from an ecommerce standpoint but is also extremely valuable from the perspective of building a health profile of a particular user/patient. This has enabled us to construct a single view for patients and build a patient view over the unified data lake.
Unified data lake as the core: The starting point for this exercise is the unified data lake. We identify the relevant data-points that could be used to get facts or inferences about a user’s health. These are prescription orders, diagnostics bookings, doctor consultations, medically relevant questionnaires, pill reminders, etc.
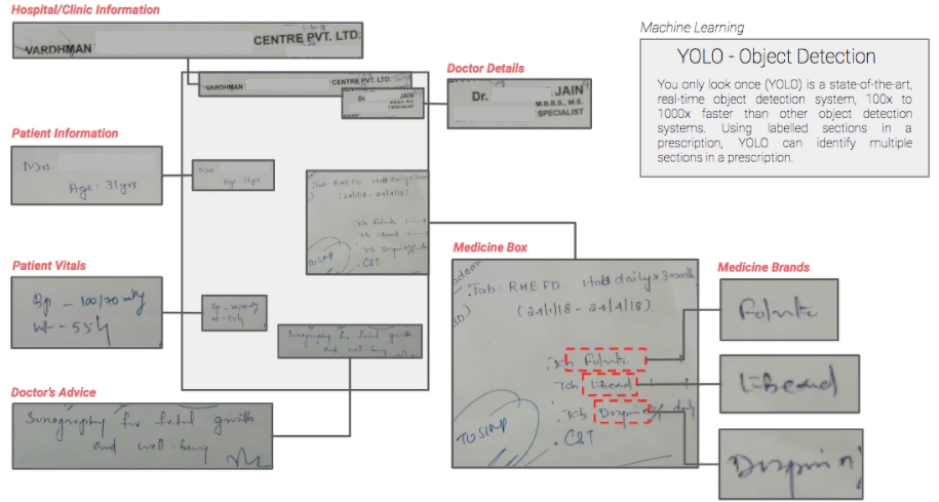
Models for Unstructured Patient Data – Health data by nature is unstructured, comprising of images and text documents. Mining the essential attributes from each type of data point, digitizing their corresponding values, and then standardizing them is something that we have built over the last few years. We have built natural language processing, image processing, and knowledge graph mapping models to extract information from prescriptions and diagnostics reports, structuring patient-doctor conversations, and more. The image below depicts the components extracted from a prescription using the YOLO object detection algorithm.
Storing and consuming information from the health repository – The identification and extraction of health data points is done on top of the data stored in the unified data lake and stored at a patient ID level in a Cassandra database. From there, the health data can be consumed for any downstream application.
Finally, the below diagram depicts how we have been able to get everything together and achieve an interface that can be queried via patient and user identifiers.
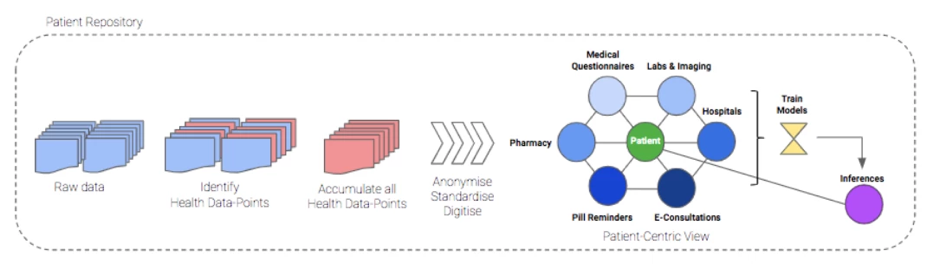
At 1mg, we process tens of thousands of prescription orders, diagnostics reports, and e-consultations between patients and doctors each day. Each of these health records are now digitized and stored in a single patient repository, which can be accessed to get a 360-degree view of a patient’s health. Having everything in a standardized form in a single place has helped in the improved clustering and cohortization of 1mg’s users. With easy identification of users who’ve interacted with one business unit like pharmacy but not with the others like diagnostics or e-consultation, we have now been able to build specific solutions aimed at enhancing cross-sell , improving customer experience and get higher conversions. Cross-selling of products and services across the multiple business units in 1mg, always seen as a missed opportunity, has now come front and center with potential growth of 50% in customers crossing over between business units.
Next steps
The patient repository is an ever-growing pipeline with enrichment by additional data sources like user surveys, behavior, and adherence data. This data is extremely relevant for each user and making it easily but securely accessible and always available is the goal of this effort. Looking ahead, our focus would be to become the first large-scale health repository for Indian patients. We plan to keep adding new and relevant information for users in this repository.