AWS Startups Blog
A Look Inside Vidora’s Globally Distributed Low-latency A.I.
![]()
Guest post by Philip West, Founder, Vidora
Artificial Intelligence (A.I.) has dominated the tech headlines throughout 2016, and it shows no signs of letting up as we kick off 2017. While the tech giants push A.I. in their own specific ways, many other businesses are looking for solutions to stay up to speed and effectively apply A.I. to optimize their organizations and meet goals. This has opened the door for many startups to enter the market as well.
At Vidora, we look forward to helping push this innovation forward as 2017 gets underway. Vidora offers a specialized A.I. platform that enables premium media, commerce, and consumer brands like News Corp, Walmart, and Panasonic to increase user retention by predicting the lifetime value of users and by automatically increasing value using 1-to-1 personalization.
Building a specialized A.I. for your own business, let alone a general one for the masses, is difficult. It’s expensive to build and maintain, it’s hard to reliably test at scale, and it takes time and patience to allow machine intelligence to learn and mature. The Vidora team has spent countless hours building and evolving our solution. One big reason that we’ve been able to make such great progress on our A.I. and adapt it to companies of large scale is the flexibility and functionality provided by AWS. In this post, we give you a peek inside how Vidora’s system works, what tools we’ve used, and how AWS has helped make this complex technology a reality.
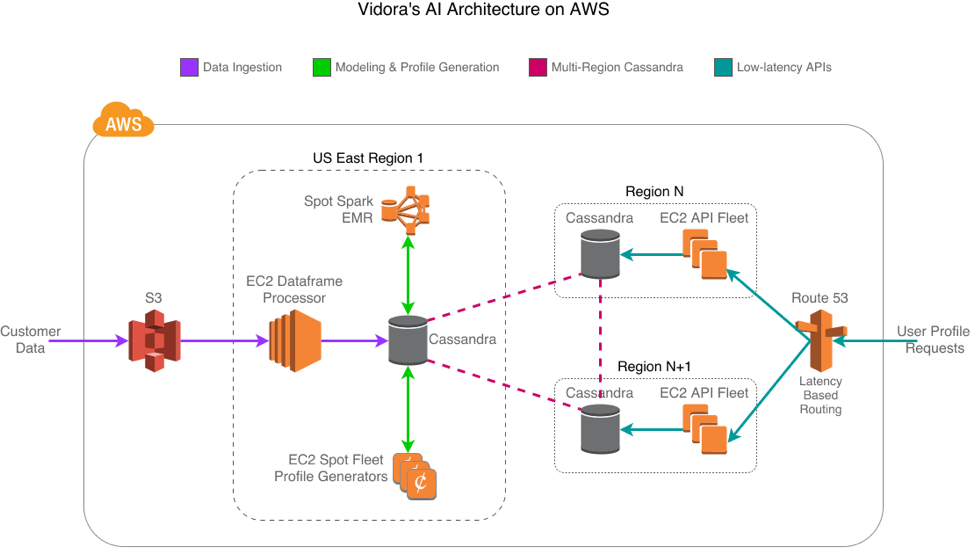
Data ingestion
Vidora’s A.I. starts with data ingestion. Sharing data with others can be a pain due to the infinite number of ways it can be structured and organized. Fortunately, AWS already provides numerous ways to share data, making the process easier. A user’s behavioral events are sent to us via a variety of methods: Vidora’s API, Amazon Kinesis, Amazon Redshift, and custom pull-based systems that pull from Amazon Simple Storage Service (Amazon S3). This data includes an anonymous but unique ID for the user, and also some information on what that user just “did,” such as read an article, clicked a link, watched a video, liked a post, etc. We translate each of these to a dataframe friendly format that gets stored in S3 every few minutes for Spark processing. As this data comes in, other various analytics get stored in both Redis and Cassandra as well.
Modeling & profile generation
Once we have the data, the next step is building our A.I. models. This lies at the heart of what Vidora does. Each of our customers has different scales of the amount of data we need to process, and varying intervals for how often the underlying A.I. models need to be updated. They also have different business goals, each with unique needs and constraints. For example, one customer might need to send weekly personalized emails, while another might need to optimize push notifications in near real-time.
Given the large amounts of data and the variations in the output required, Vidora needs a tool that provides the ability to run fast map-reduce jobs as well as a simple solution for investigatory data science. Vidora has found Spark on Amazon EMR to be a great fit. Spark interfaces nicely with Python and enables us to execute Panda’s dataframe operations at scale without having to do much around code optimization or pre-defining queries. Amazon EMR provides us a simple solution to spin up Spot clusters with Spark on various schedules and with custom parameters, and then spin them down once the jobs are finished, ultimately saving us money. By using Spot clusters, we typically see savings of 80% when compared with the on-demand price.
Once the machine learning models are generated, our queue-based processing system spins up Spot instance worker machines in Amazon EC2 that build and constantly update profiles for the most recently active users. This means we can update a user’s profile minutes after their last activity. These profiles contain information such as each user’s likelihood of returning to our customers’ products and services, what marketing channel is the most effective to reach them, when a message should be sent, and what specific content the user is most likely to engage with. Vidora has written its own machine learning algorithms to identify these characteristics of the profiles. Included in that process is a layer of information-theoretic techniques that assess the importance of each feature’s influence on user retention or any other high-level goal the customer has. This allows us to predict beforehand whether a specific action or set of content will have a positive or negative impact on the user’s loyalty, and by how much.
To manage the worker cluster that builds the profiles, we recently began using Spot fleet configurations. With Spot fleets, we now can get the best-priced computing power across a variety of instance types and Availability Zones, with no effort on our end other than the initial setup. It’s also trivial to adjust the size of our fleets using the aws-cli tool and its modify-spot-fleet-request command, which allows us to auto-scale the fleet size based on how large our processing queue is.
Multi-region Cassandra configuration
User profiles can take up a bit of space. Especially when you’re working with customers of Walmart’s or News Corp’s scale. These customers also require global coverage because many of them own multiple properties in various locations. To meet these requirements, we store our user profiles in Cassandra running in a multi-region replicated configuration, so that every user’s profile is available from a multitude of geographical locations. This allows us to do the high-cost processing in only one region.
All writes happen in the U.S. East (N. Virginia) Region, but then are seamlessly sent to the other regions via DataStax’s Ec2MultiRegionSnitch for Cassandra. To ensure our reads are as low-latency as possible, we use Cassandra’s LOCAL_ONE consistency for reads, meaning we return the first result we find from the local region without double-checking any other replicas for consistency. Using this strategy, we risk the data becoming gradually inconsistent, so we run full repairs daily to correct them in the background. We ensure the clusters have enough CPU and I/O capacity to always have a repair running without impacting latency.
Low-latency APIs
After we build and store user profiles, customers need to access them via APIs on a per-user basis, whether it’s for emails, push, or web experiences. These APIs often lie in the critical path of each user’s experience, thus demanding extremely low latency and high reliability across the world.
As mentioned earlier, we store user profiles in Cassandra across several regions, which improves the lookup times for user profiles to meet these low latency conditions. Similarly, our API servers are also deployed in the same regions, helping to decrease the time customers spend waiting for a response. We also aggressively cache much of our data with Redis to ensure even lower latency for most of our results.
Finally, we use Amazon Route 53 for DNS, specifically Route 53 latency-based routing and health checks to ensure each region is healthy. This satisfies both low latency and high availability: When everything is up, the customer talks to the nearest region for the fastest response, but if we lose a region, our Route 53 DNS failover configuration reroutes to a healthy region, providing reliability.
What’s next
While building an A.I. is difficult, AWS services dramatically simplify the architectural decisions you need to make as well as the tactical steps you need to take to manage the system. You can store massive amounts of data at very affordable rates, spin processing clusters up and down with the latest and greatest map-reduce frameworks, and address a global audience quite easily with a suite of cloud-computing services. At Vidora, we hope that our learnings from building an A.I. in the cloud can benefit others, and we look forward to hearing more about the innovative ways others decide to use AWS as we enter 2017, the year of A.I.
Please reach out to us at info@vidora.com or sign up for our talk at the AWS Loft in San Francisco to learn more!