AWS Startups Blog
Building a Hotdog Detecting App on AWS—Yes, Really

Jian-Yang discusses his hot dog app with Erlich in a scene from “Silicon Valley.” Photo courtesy of HBO.
In Season Four of the hit HBO show, “Silicon Valley,” the character Jian-Yang attempts to build an app that uses image recognition artificial intelligence (AI) to identify and label the foods in captured pictures. But there is a fairly major glitch: his app can only differentiate between hot dogs and… not hot dogs. Cue the disappointed looks and stinging comments from his fictional investors and pals.
Once I stopped laughing, the episode prompted a question that centers on my role as a Solutions Architect at AWS: How easily could I build my own hotdog identifying app? Turns out, pretty easily.
Let me walk you through what it took to build what I call Hotdog Detector.
To build Hotdog Detector on AWS I used three services: Amazon Rekognition, AWS Lambda, and Amazon API Gateway. Rekognition provides on-demand deep learning-based visual search and image classification and enables the core AI logic of the app. Lambda provides a serverless environment to test and run the app code, and serves as the backend for the app. API Gateway provides a fully managed platform to create, publish, maintain, monitor, and secure an API for the app, allowing the app front-end to interface with the back-end.
We will focus primarily on the back-end code for Hotdog Detector in this blog post, but a CloudFormation template for building the infrastructure and instructions for how to integrate it with Slack as a front-end can be found in the serverless-hotdog-detector GitHub repo.
Architecture Overview
A basic overview of how Hotdog Detector works can be seen below. Users interface with the app front-end by uploading or capturing images. Upon image upload or capture, the app front-end triggers an invocation of the Lambda back-end via a request to the app API. The Lambda back-end streams the image to Rekognition for labelling, and checks the labels to determine if the image contains a hotdog. The app front-end is then updated to reflect whether the image contains a hotdog.
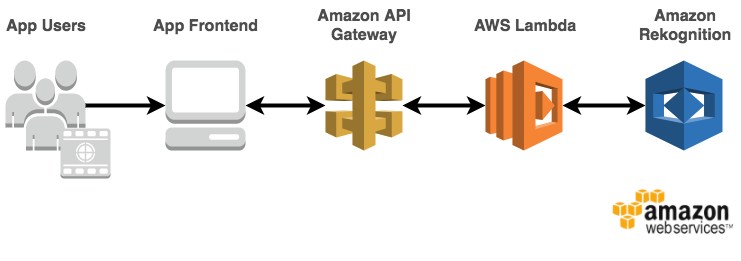
Getting Started
Before I could write my code I first needed to create a blank Lambda function with the appropriate IAM permissions to make calls to Rekognition and an API to integrate it with. If you are unfamiliar with this process the Getting Started documentation pages for Lambda and API Gateway can walk you through it, or you can use the CloudFormation template for this sample to build these components for you.
Implementing Hotdog Detector
At this point I had everything set up for the application except the code. The full Lambda function code for the app can be found in the serverless-hotdog-detector repo, but the code snippet below details how I built the core AI functionality by making calls to Rekognition.
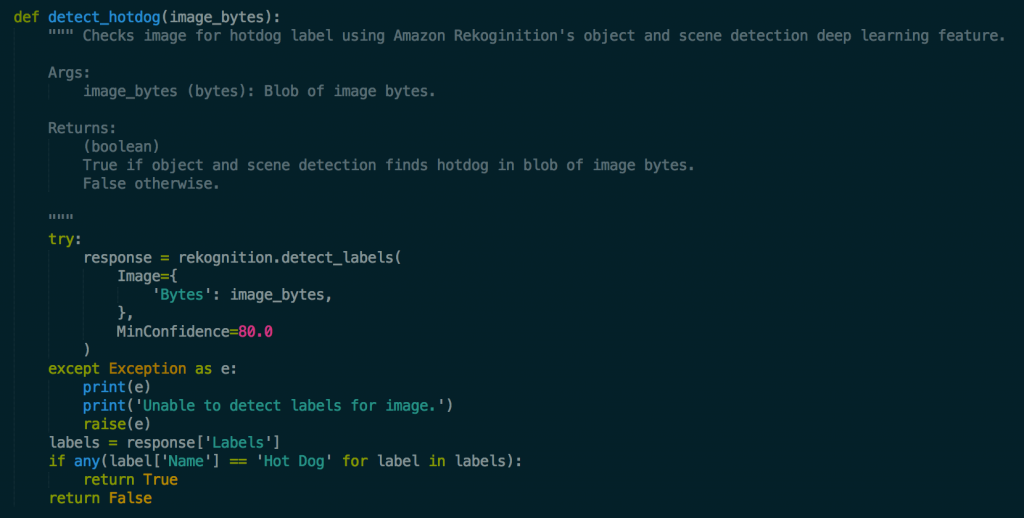
The detect_hotdog function takes the image bytes of the image uploaded by the user and streams them to Rekognition for labelling using the Boto3 wrapper for the DetectLabels Rekognition API call. The MinConfidence parameter is optional, and allows you to restrict the labels returned to only those that can be detected by the Rekognition AI to be above a minimum confidence interval. In this case, MinConfidence can be thought of as the minimum hotdog-ness that is acceptable to label an image as containing a hot dog.
The labels are returned from this API call in the form of a list of dictionaries, where each dictionary contains the keys Name and Confidence containing the name of the label and the confidence Rekognition had in labelling the image with this label respectively. If Rekognition detects the image contains a hot dog, it returns a label entry with the name “Hot Dog.” The code checks for this label and returns the Boolean value “True” if it is found in any of the label entries and “False” otherwise.
The gif below shows the example integration with Slack as a front-end for the app in action. The Lambda function code sample in the repo for this post uses a call to the Slack API to update the front-end after the hotdog detection has occurred. If the app was instead integrated with, for example, a web front-end, this would need to be implemented in the Javascript for the web layer.

Lessons Learned
I’m a huge fan of “Silicon Valley” so this was a really fun way to tie it into one of my favorite hobbies—building things. The most important thing I learned was how easy it is to leverage and build with Rekognition’s image recognition and labeling. I didn’t have to set up any infrastructure to host a model; it didn’t require any intimate knowledge of AI to build a model; nor did I have to acquire a labeled image dataset to train my model with. With Rekognition I was able to implement the core AI functionality of the app in less than an hour.
Beyond image recognition and labeling, Rekognition’s deep-learning capabilities include facial recognition, analysis, and comparison and image moderation. To see these in action check out the Image Processing module of our Wild Rydes workshop and the Image Moderation Chatbot reference architecture, respectively.
To see another example of an interesting use case for Rekognition’s image recognition and labeling functionality check out our Image Recognition and Processing Backend reference architecture.
Moving forward
In “Silicon Valley,” the whole creation of the Not Hotdog app was in service of comedy, and I suppose a commentary on what does gets built. But in some ways, that is the real point: it’s possible to build just about anything you can dream up—for laughs or not.
(And in a reality follows fiction twist, the show’s technical advisors did build the Not Hotdog app themselves.)
For me, the experience prompted the obvious next question: what’s next? What else can I build? Now that you’ve seen how easily Rekognition can be leveraged for apps like Hotdog Detector, I would love to hear your ideas for what you want to build or have already completed.