AWS Storage Blog
Building high-performance storage clusters with Veritas and Amazon EBS
Providing predictable storage performance for mission critical applications can be challenging. Doing so involves dealing with complex configurations in your storage systems to get the performance you need, such as by striping multiple disks or volumes together, or by investing in expensive storage hardware. None of these configurations are flexible, and it is hard to make changes without incurring downtime.
AWS recently announced the general availability of Amazon EBS io2 Block Express volumes, currently available with R5b instances, which deliver up to 256,000 IOPS, 4,000 MB/s of throughput, and storage capacity of 64 TiB in a single volume. One of the best things about io2 Block Express volumes is that they are designed to increase throughput performance linearly as you scale the IOPS of your volumes. This means you can enjoy great storage performance with a significant reduction in configuration complexity. Amazon EBS io2 Block Express volumes are great for systems that require higher performance to run your important applications, like SAP HANA, Microsoft SQL Server, Oracle, and Apache Cassandra workloads. For mission-critical transaction processing applications, such as airline reservation systems and banking systems, highly available scale-out storage and compute allows for consistently high performance and uptime.
Veritas has been working with AWS to provide a preview of how Veritas InfoScale can help make io2 Block Express volumes even better. In this blog, I demonstrate how InfoScale can help enable the deployment of a high-performance storage cluster with the new io2 Block Express volumes, and I also include FIO (Flexible I/O) test results.
InfoScale and AWS: Working together
Veritas InfoScale is a leader in software-defined storage and workload resiliency, abstracting applications from underlying infrastructure to enable enterprise-grade business continuity solutions. InfoScale works seamlessly with Amazon EBS by providing agents that operate with native AWS APIs to provide the same operational experience customers receive when running InfoScale on bare metal servers.
InfoScale has custom integration with AWS that provides:
- High availability for enterprise applications, including Oracle, SAP, TIBCO, Informatica, MySQL, or any generic service. InfoScale can instantly detect the state of an application and its required resources through kernel level drivers, minimizing the potential for business disruption.
- Software-defined, scale-out storage – InfoScale’s Flexible Storage Sharing (FSS) technology enables storage connected to individual servers (virtual or bare-metal) to be shared in a cluster.
- Geographic redundancy – InfoScale’s high availability and replication services allow you to build a geographically dispersed architecture, spanning between on-premises resources and AWS.
- SmartIO intelligent caching – application reads can be served from faster volumes using high-speed SSD storage while data can be persisted to a cheaper tier of storage. This approach significantly improves application performance with minimal additional cost.
While there are many solutions that provide high availability and disaster recovery (DR), InfoScale has the added tight application integration and management capability that can ensure that storage and applications are highly available and protected from disaster.
InfoScale also makes it possible to migrate applications from on-premises environments into AWS to take advantage of cutting-edge, high-performance, low-latency storage such as io2 Block Express EBS volumes with minimal disruption.
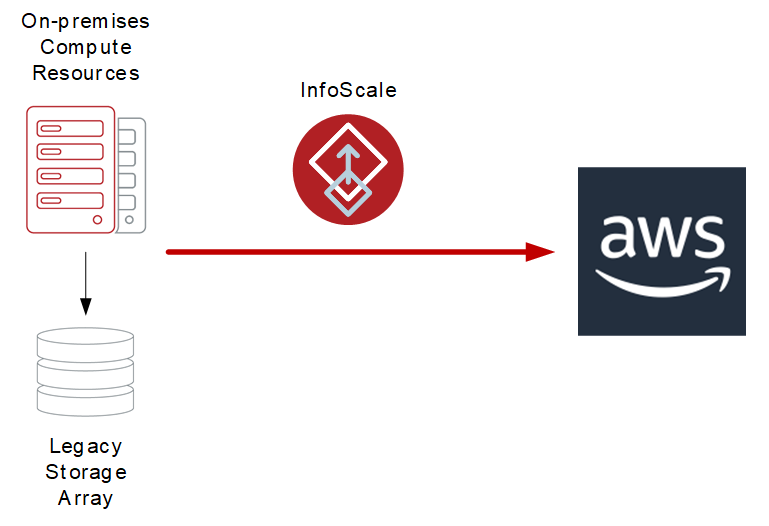
Figure 1: On-premises migration to AWS
The InfoScale cluster is an elegant solution to an old problem. How do you make multiple servers aware of each other so that they can coordinate and schedule the execution of applications without corrupting data?
A clustered application requires some method of ensuring that there is a single source of data. InfoScale provides that with a clustered file system that can be shared between compute resources and is transparent to your applications.
InfoScale (specifically Veritas Cluster Server) also ensures that an application will run on any of the nodes within the cluster, thus maximizing its availability. If a node within a cluster goes down, the application can continue to run on any remaining node. Since storage is shared between all the nodes, data consistency is preserved. InfoScale also provides a mechanism to prevent split-brain scenarios (which can cause data corruption) with I/O fencing.
The following Figure 2 is an example diagram of the InfoScale and io2 Block Express solution.
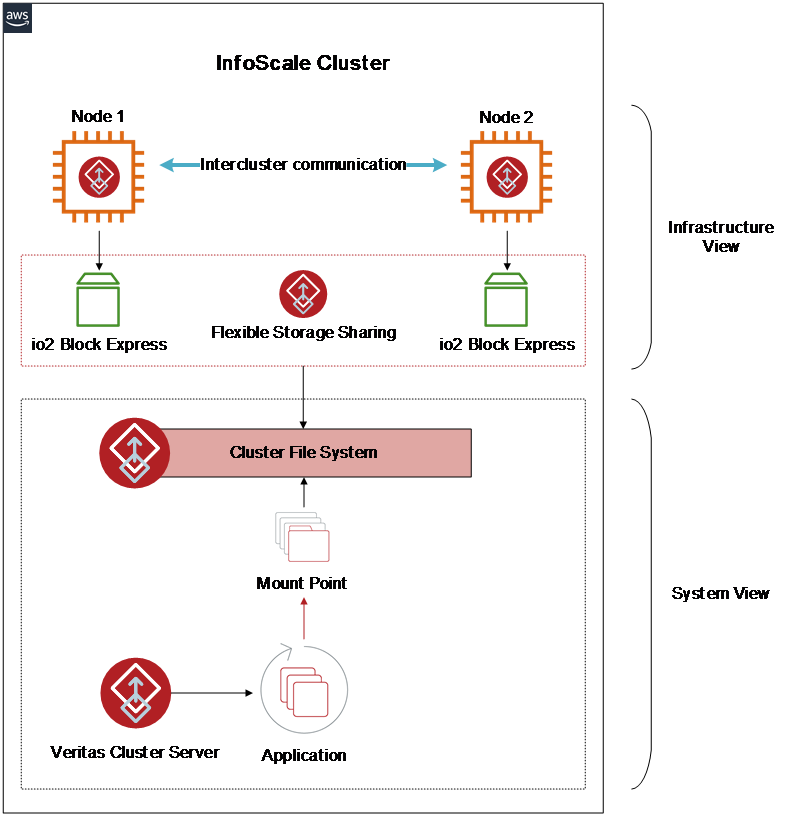
Figure 2: Test system
Testing
I started out by provisioning the test environment with two r5b.24xlarge Amazon EC2 instances, configured with Red Hat Enterprise Linux.
Figure 3: R5b instances
Each EC2 instance was provisioned with one 320-GiB io2 Block Express volume with 32,000 IOPS connected to it, in addition to the required network interfaces for the intercluster communication. The r5b.24xlarge instances have 96 vCPUs and 768-GiB RAM each.

Figure 4: io2 Block Express EBS volume
I then installed InfoScale on both nodes and shared the storage on each node with flexible storage sharing (FSS). Then I created a cluster file system from the shared storage and configured it to stripe data across the two io2 Block Express volumes attached to each node.
Results
Then I ran a FIO test, which includes four test types. Here’s the summary of results.
| Test type | Results – throughput in MB/s |
| Sequential write | 7240 |
| Sequential read | 6950 |
| Random write | 7202 |
| Random read | 6975 |
Here’s a sample of FIO test parameters.
ioengine=libaio iodepth=8 rw=randwrite bs=512k direct=1 size=2G numjobs=64 group_reporting
For each test, the same parameters were used, varying on the “rw” type (write, read, randwrite, randread).
To summarize:
- Each io2 Block Express volume supports up to 4000 MB/s in throughput.
- In each of my tests, regardless of I/O type, I managed to obtain between ~6900 MB/s to ~7200 MB/s in combined throughput for two R5b compute nodes.
- FIO ran individually on each of the two nodes in parallel.
Summary
In this blog, I covered how I deployed a high-performance storage cluster using InfoScale with the new io2 Block Express volumes. Based on this testing experience, I can confidently say that AWS io2 Block Express is an excellent option for high-performance, low-latency storage.
The combination of io2 Block Express and Veritas InfoScale makes it easy to build a clustered, highly available scale-out storage and compute platform that would be a great, cost-effective solution for applications with higher performance requirements. If you’re looking for a highly available application platform and high-performance storage to run mission-critical enterprise applications, take a look at this solution from Veritas and AWS. The ease of use and excellent performance are bound to impress.