AWS Database Blog
Streaming data to Amazon Managed Streaming for Apache Kafka using AWS DMS
Introduction
AWS Database Migration Service (DMS) announced support of Amazon Managed Streaming for Apache Kafka (Amazon MSK) and self-managed Apache Kafka clusters as target. With AWS DMS you can replicate ongoing changes from any DMS supported sources such as Amazon Aurora (MySQL and PostgreSQL-compatible), Oracle, and SQL Server to Amazon Managed Streaming for Apache Kafka (Amazon MSK) and self-managed Apache Kafka clusters.
In this post, we use an ecommerce use case and set up the entire pipeline with the order data being persisted in an Aurora MySQL database. We use AWS DMS to load and replicate this data to Amazon MSK. We then use the data to generate a live graph on our dashboard application.
Then the data will be used to generate a live graph on our dashboard application. We will also discuss about how to use a custom S3 feeder application to send the data from MSK topics to an S3 bucket.
Once the setup is completed, any new incoming orders into your Aurora MySQL database will be replicated and reflected on your dashboard graph in real time.
Solution overview
We divide this solution into two sections:
Section 1: Setting up infrastructure for your pipeline which feeds a live dashboard to showcase incoming order data.
Section 2: Consuming the data streams coming to Amazon MSK and pushing to Amazon S3 and query it with Amazon Athena.
You can find the accompanying dashboards and sample applications in the GitHub repo.
The repo contains the sample Java applications that we use in both sections in this post. It contains three modules:
- Dashboard
- A dashboard application showing incoming orders data and displaying it by states.
- This module contains a Spring Boot based Kafka listener. It shows how to build a custom application to listen to an incoming stream of data in Kafka topics and send it to a live dashboard.
- It uses a websocket connection to connect to the server and open source chartjs to build a simple graph on the data.
- Data-gen-utility
- You can use this small command line utility to generate dummy order data to feed to the source MySQL database.
- Msk-to-s3-feeder
- This independent Spring Boot application shows how you can take streaming data from Amazon MSK and implement a batch listener to club streaming data and feed it to an S3 bucket that you provide in one or more objects.
Solution architecture
The following architecture diagram shows how to replicate data in a database like MySQL to Amazon MSK in near-real time using AWS DMS.
For our ecommerce use case, data is being generated and stored in our transaction database. This data flows to the live dashboard and Amazon S3 via AWS DMS and Amazon MSK.
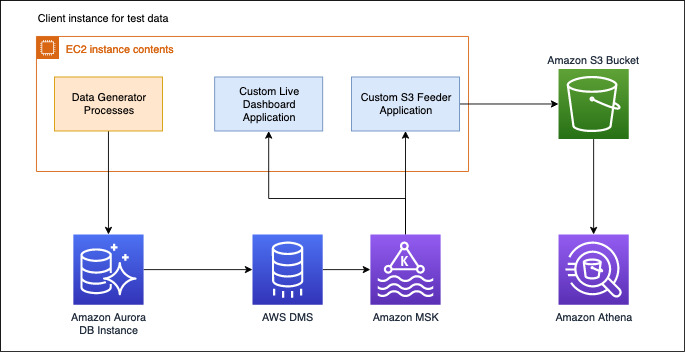
Setting up your pipeline
In this section, you setup a pipeline to feed data to the live dashboard
Creating an IAM role
If you don’t have dms-vpc-role in your account, create an IAM role named “dms-vpc-role” for AWS DMS API.
- On the IAM console, choose Roles.
- Choose Create role.
- For Choose a use case, choose DMS”.

- For Filter policies, search for dms.
- Select permissions AmazonDMSCloudWatchLogsRole and AmazonDMSVPCManagementRole.

Provisioning your resources
You create the resources for this use case with the provided AWS CloudFormation stack.
- Run the stack in the region of your choice:

The CloudFormation stack requires that you input parameters to configure the infrastructure to migrate the data into Managed streams of Kafka. A few parameters have default values filled.
- Please add two values below.
- IPCidrToAllowTraffic – An IP address to SSH to the client instance. Generally you provide your own system IP (such as x.x.x.x/32).
- KeyName – The key pair name for your client Amazon Elastic Compute Cloud (Amazon EC2) instance. You can choose an existing keypair or create a new one.
- Select the check box to allow CloudFormation to create IAM roles.
When the stack is complete, you can find the status on the AWS CloudFormation console.

The stack creates the following resources:
-
- EC2 instance: Streaming-DMS-MSK-Pipeline
- Amazon MSK cluster: MSKMMCluster1
- MySQL source endpoint
- Target Amazon MSK endpoint
- AWS DMS task (full load and CDC)
- AWS Lambda functions: CustomClusterConfigLambda, CustomKafkaEndpointLambda and TestConnLambda
- Aurora MySQL DB cluster.
Setting up source data generation
After you create your resources, complete the follow steps to set up the source data generation on the client EC2 instance.
- Login to Amazon EC2 using putty (Windows) or terminal (MacBook) with the following code:
ssh –i “<keypair.pem> ec2-user@ec2-xx-xx-xx-xx.us-east-1.compute.amazonaws.com
- Download the sample code:
git clone https://github.com/aws-samples/aws-dms-msk-demo.git
- Enter the following code to build the applications:
- Enter the following code to connect to MySQL. Replace the hostname with the Aurora MySQL DB host endpoint (writer endpoint) that was created by the CloudFormation stack. You can find it on the Amazon Relational Database service (Amazon RDS) console for the database. The default username is ‘master’ and the default password is ‘Password1’ unless you changed it in the CloudFormation stack parameters.
- At the SQL prompt, enter the following code to create the sample table ‘orders’ in the database ‘testdb’:
Ensure that the binary logs are available to AWS DMS because Amazon-managed MySQL-compatible databases purge the binary logs as soon as possible, You should increase the length of time that the logs remain available.
- To increase log retention to 24 hours, enter the following command:
- Hit cmd + z and come out of the SQL prompt.
Setting up your dashboard application:
You can now set up the sample dashboard application on your EC2 instance. You first get the Amazon MSK broker URLs
- On the Amazon MSK console, choose the cluster you created
- Choose view client information.
- Locate the broker connection details in plaintext.
You want the plaintext link and not the TLS, because TLS requires some extra configuration on the client side to work. For more information about connecting via TLS, see Client Authentication.
- Run the following code on the client EC2 Instance to launch dashboard:
- Open the application web URL in the browser.
http://<IP of the EC2 instance>:8080/
The application looks similar to the following screenshot:

This dashboard is volatile and all data is reset when you refresh your browser.
Generating data on the source engine
Now that we have the infrastructure and the pipelines set up, you can generate the data on the MySQL source engine and check the dashboard:
- Open a new SSH session to Amazon EC2.
- Use the datagen.jar utility present in the cloned GitHub repo to generate sample data in bulk of 2000 records.
- When prompted for the start index, enter 1.

The *.sql file is generated with 2000 dummy order records.
- Connect to the database again using the following command and ingest the SQL file generated. It inserts your dummy data into database.
- Start the AWS DMS task via the AWS Command Line Interface (AWS CLI) so our data starts getting replicated to MSK. You can find the task ARN on the AWS DMS console.
- Check the task logs to confirm that the task migrated the data onto the target Amazon MSK.
- Check the sample dashboard graphs that now shows the replicated data.

You can generate more sample data following these steps and migrate the data onto the target.
To test the ongoing changes and check the dashboard for replicated data, connect to the Aurora cluster and perform DML and DDL operations.
The sample dashboard graph is incremented for inserts. For updates and deletes, only the counters on the app change.
Consuming the data streams and querying the data:
In this section, you consume the data streams pushed to Amazon S3 and use Athena to query the data. You must have an S3 bucket to push the data from the MSK topics to, and an external table in Athena pointing to that bucket.
Creating your S3 bucket and consuming the data
Complete the following steps:
- Create an s3 bucket in your account to act as the destination.
- Go to the SSH session where the dashboard application was running and stop the application by pressing CTRL/CMD + C.
- Run the msk-to-s3-feeder application using the following code:
java –jar msk-to-s3-feeder.jar –aws.s3.bucketName <bucket name> --kafka.bootstrapEndpoints <broker-endpoint>:9092 --kafka.topic dms-blog
- In a separate SSH window, generate 3000 records and insert via the MySQL command line to Aurora (see the previous section for the relevant code).
- You should see some msk-to-s3-feeder application logs
- Confirm the files were delivered to Amazon S3 via the AWS CLI:
aws s3 ls s3://<bucket name>/output/ --recursive
You should see entries like the following code:
2020-06-19 17:02:42 560 output/660fff82-3501-4476-b29a-66d6028b4c841592141618007.json
Creating a table and querying the data
Create the sample table named ‘kafkajson’ in database: ‘default’ (replace the bucket name before running):
The following screenshot shows the preceding code on the console.

After you provide the required details and create the table, you can run a query and return the following result set:
SQL> SELECT * FROM “default”.”kafkajson”
The following screenshot shows your results.

Cleaning Up
To avoid incurring future charges, clean up the resources used in this post.
- On the AWS CloudFormation console, delete the CloudFormation stack.
- On the AWS DMS console, delete “dms-blog-kafka-target” AWS DMS endpoints.
- On the AWS DMS console, delete any log groups with name “Streaming-DMS-MSK” (or use the stack name if you changed it while creating the stack).
- On the Amazon S3 console, clean the folder output and delete the S3 bucket.
- On the Athena console, delete the Athena table you created.
Conclusion
In this post, we showed you how to set up a pipeline with a CloudFormation template to get data from a MySQL database and send it to Amazon MSK topics in real time. We also set up custom applications to consume the data from Amazon MSK and display dashboards based on it in real time. We pushed the data from Amazon S3 using a simple application and queried the data via Athena.
We hope this post helps you get started on building similar pipelines. Good luck and happy building!
About the authors
 Harish Bannai is a Technical Account Manager at AWS. He holds the AWS Solutions Architect Professional, Developer Associate and Solutions Architect Professional certifications. He works with enterprise customers providing technical assistance on RDS, Database Migration services operational performance and sharing database best practices.
Harish Bannai is a Technical Account Manager at AWS. He holds the AWS Solutions Architect Professional, Developer Associate and Solutions Architect Professional certifications. He works with enterprise customers providing technical assistance on RDS, Database Migration services operational performance and sharing database best practices.
 Aswin Sankarapillai is a database engineer in Database Migration Service at AWS. He works with our customers to provide guidance and technical assistance on database migration projects, helping them improve the value of their solutions when using AWS.
Aswin Sankarapillai is a database engineer in Database Migration Service at AWS. He works with our customers to provide guidance and technical assistance on database migration projects, helping them improve the value of their solutions when using AWS.
 Amandeep Bhatia works as an Architect. He is passionate about cloud technologies and focuses on building large distributed systems on cloud for various startups and enterprises. He has helped many large scale migrations to AWS as well as building cloud native architectures. In his free time he likes to learn new technologies and spend quality time with kids and family.
Amandeep Bhatia works as an Architect. He is passionate about cloud technologies and focuses on building large distributed systems on cloud for various startups and enterprises. He has helped many large scale migrations to AWS as well as building cloud native architectures. In his free time he likes to learn new technologies and spend quality time with kids and family.