AWS Database Blog
Data modeling best practices to unlock the value of your time-series data
October 2024: This post was reviewed for accuracy.
Amazon Timestream is a fast, scalable, and serverless time-series database service that makes it easier to store and analyze trillions of events per day. Timestream automatically scales up or down to adjust capacity and performance so you don’t have to manage the underlying infrastructure. When it comes to managing time-series data, traditional relational databases fall short in meeting the unique requirements of high-volume, timestamped data. Timestream emerges as the ideal solution with its purpose-built architecture designed specifically for time-series data and advanced built-in time-series analytical functions. It enables efficient ingestion, storage, and analysis of massive amounts of data, allowing businesses to effortlessly handle the scale and velocity of time-series data. With the optimized design and capabilities of Timestream, you can unlock the true potential of your time-series data and drive meaningful insights at scale, making it a superior alternative to traditional RDBMS for time-series workloads.
In this post, we guide you through the essential concepts of Timestream and demonstrate how to use them to make critical data modeling decisions. We walk you through how data modeling helps for query performance and cost-effective usage. We explore a practical example of modeling video streaming data, showcasing how these concepts are applied and the resulting benefits. Lastly, we provide more best practices that directly or indirectly relate to data modeling.
Key concepts of Timestream
Understanding the following key concepts in Timestream is vital for optimal data modeling and effective ingestion, querying, and analysis:
- Dimension – Dimensions are attributes that describe the metadata of a time-series. For instance, if we consider a stock exchange as a dimension, the dimension name could be stock exchange with a corresponding dimension value of NYSE.
- Measure – The measure represents the actual value being recorded. Common examples of measures include temperature readings, stock prices, click or video streaming metrics, and any other metrics related to manufacturing equipment, Internet of Things (IoT) devices, or automobiles.
- Measure_Name (default partition key) – The
measure_nameattribute represents an identifier of a specific measurement or metric associated with a time-series data point. It provides a way to categorize and differentiate different types of measurements within a Timestream table. This attribute acts as the default partitioning key if a customer-defined partition key is not used. - Customer-defined partition key – Customer-defined partition keys are used to distribute data across partitions for efficient storage and query performance. By choosing an attribute that has high cardinality and is often used in queries, you can optimize data organization and retrieval. Dimensions like host ID, device ID, or customer ID are often good choices for a partition key.
- Timestamp – This indicates when a measure was collected for a given record. Timestream supports timestamps with nanosecond granularity. For instance, when collecting sensor data to track patients’ vital signs, we store the timestamp of data collection in this field using the epoch format.
- Table – A table is a container for a set of related time-series (records).
- Database – A database is a top-level container for tables.
The following image shows a Timestream table containing two dimensions (device_id and location) and measure_name, time, and two measures (quality and value). Assuming that device_id has high cardinality and is often used in querying for filtering, it could be chosen as the customer-defined partition key.
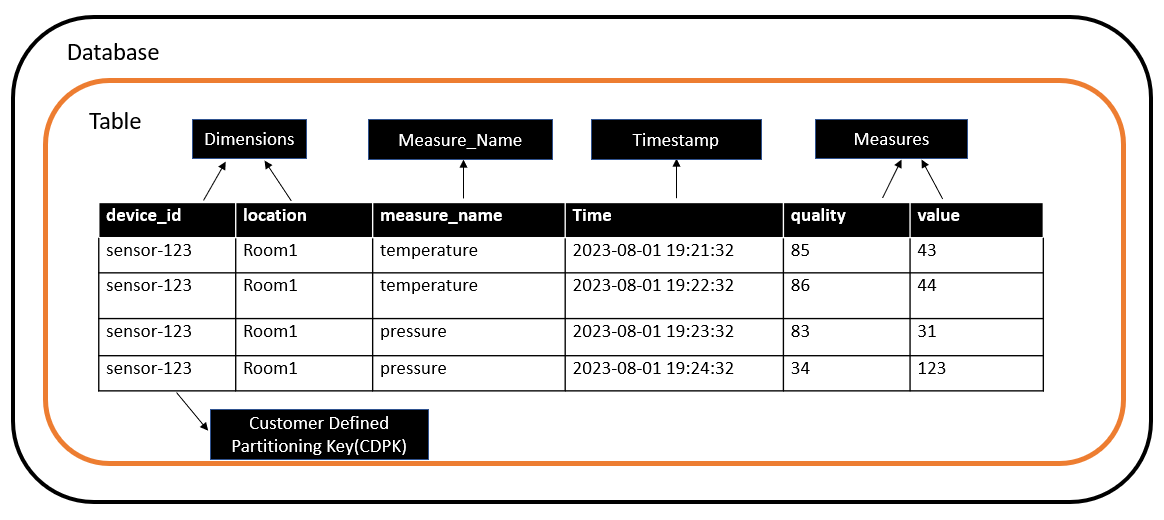
Timestream offers a flexible and dynamic schema-less structure, allowing you to adapt and modify your data model without the constraints of a rigid schema. It is schema on write, so you don’t predefine columns while creating the tables. Although Timestream is a purpose-built NoSQL database for time-series data and does not store information in relational tables, it does provide support for SQL. This allows users familiar with SQL to use their existing skills and perform analyses on time-based datasets with advanced time-series functions.
Optimal data modeling helps improve data quality, improve performance, and reduce storage costs. Effective data modeling in Timestream begins with understanding query patterns, which helps optimize performance and cost metrics. By identifying dimensions, measures, and partitioning keys, you can efficiently structure and organize data in Timestream. On top of data modeling, using the right filters for querying will help queries run swiftly and cost-effectively.
Modeling video streaming data
Let’s walk through an example of data modeling for a video streaming application using Timestream and how these factors contribute for cost and performance.
Imagine you’re collecting the following data as part of a video streaming application:
- video_id– Represents the unique identifier for each video
- viewer_id– Identifies individual viewers who interact with the videos
- device_type– Represents the type of device used by the viewer for streaming, such as mobile, web, or smart TV
- region– Specifies the geographic region where the viewer is located
- session_id– Represents a unique identifier for each streaming session initiated by a viewer
- start_time– Captures the exact time when a viewer starts watching a video
- playback_duration– Records the length of time the viewer spends watching the video
- video_resolution– Stores the resolution of the video being streamed
- playback_quality– Indicates the quality of the video playback, such as 720p, 1080p, or 4K
Before delving into queries, let’s clarify the pivotal tasks our video streaming app must accomplish and the relevant questions our data can answer to fulfill these objectives. We aim to uncover content popularity and viewer engagement by asking how often certain videos are watched and for how long. Additionally, optimizing user experiences entails determining preferred devices and assessing quality preferences. Understanding regional trends allows us to tailor strategies, while analyzing individual session duration and retention rates provides insights into viewer behavior. We also seek to identify high-engagement viewers and gain insights into video preferences. These questions guide our query selection, allowing us to unlock actionable insights from the app’s data.
Let’s assume the following is sample time-series data and queries as part of our video streaming use case, and we are storing the data in the table test under the database videostreaming.
| viewer_id | device_type | region | time | start_time | session_id | video_id | playback_quality | video_resolution | playback_duration |
| viewer_38 | tablet | Australia | 2023-05-17 20:54:39.000000000 | 2023-05-17 20:49:39.000000000 | session_87 | video_148428 | Excellent | 4K | 2820 |
| viewer_86 | computer | Australia | 2023-05-17 20:54:31.000000000 | 2023-05-17 20:49:31.000000000 | session_52 | video_5982 | Fair | 4K | 1020 |
| viewer_89 | smart_tv | Australia | 2023-05-17 20:54:30.000000000 | 2023-05-17 20:49:30.000000000 | session_96 | video_77868 | Excellent | 720p | 2340 |
| viewer_41 | computer | Europe | 2023-05-17 20:54:27.000000000 | 2023-05-17 20:49:27.000000000 | session_45 | video_21191 | Excellent | 720p | 600 |
| viewer_51 | computer | US | 2023-05-17 20:54:18.000000000 | 2023-05-17 20:49:18.000000000 | session_54 | video_115903 | Good | 720p | 420 |
Let’s take a look at some example queries:
- Query 1 – The following query uses the region dimension to filter the data and calculates the total count of videos watched in the US region in the last 1 day (with the Timestream ago() function). It provides an overall view of video consumption in the specified region.
- Query 2 – The following query groups the data based on the
device_typeand calculates the average duration of video streaming sessions for each device type in the last 1 day. By grouping the data in this way, you can analyze how the average duration varies across different devices. This information helps you understand user behavior and preferences on different devices and optimize your streaming service accordingly. - Query 3– The following query groups the data based on
viewer_idand calculates the total count of videos watched by each viewer in the last 1 day. The results are then sorted in descending order, allowing you to identify the top 1,000 viewers with the highest video counts. This information is useful for identifying power users or determining viewer engagement. - Query 4 – The following query calculates the average playback duration for each viewer in the last 7 days and identifies the top 1,000 viewers with the longest average duration. This helps you identify viewers who are highly engaged and spend more time watching videos. You can use this information for personalized recommendations or targeted advertising.
- Query 5 – The following query checks videos watched by viewer and can be used to provide recommendations based on videos history based on category.
- Query 6 – The following query groups the data based on
viewer_idand calculates the total count of videos watched by each viewer in the last 1 day. The results are then sorted in descending order, allowing you to identify the top 1,000 viewers with the highest video counts. This information is useful for identifying power users or determining viewer engagement. - Query 7 – The following query calculates the average playback duration for each viewer in the last 7 days and identifies the top 1,000 viewers with the longest average duration. This helps you identify viewers who are highly engaged and spend more time watching videos. You can use this information for personalized recommendations or targeted advertising.
Choosing the right dimensions and measures
When migrating from a traditional database to Timestream, it is often assumed that dumping tables and columns from the existing database to Timestream will work. However, the real challenge lies in knowing the query patterns and selecting the right dimensions, measures, and optionally a partition key.
Dimensions, including the record timestamp, contextualize observations, helping us identify the who, what, when, and where of a record. Dimensions are used to organize and categorize data, and to filter data as part of a query. Some good choices for dimensions in video streaming data are viewer_id, device_type and region. These dimensions allow you to filter and analyze the data from different perspectives. For example, you can use them to understand viewer preferences by device type or to uncover regional viewing patterns. By using dimensions effectively, you gain flexibility in querying and analyzing the data, unlocking valuable insights for video streaming analytics. Column’s video_id and session_id may consider has metadata of record but do not help with filtering. They also increase the cardinality (number of unique values) of the dataset, which you want to avoid. If your application requires a unique identifier for each data point, model it as a measure value instead of a dimension. This will result in significantly better query latency. Aim to keep the cardinality as low as possible. Lower cardinality means lesser time-series, which reduces the time needed to scan and identify the necessary tiles. This leads to faster data scanning and higher overall performance.
Measures are responsible for quantitative data (values that change over time). Measures provide the basis for performing mathematical calculations (computing totals, averages, differences in rate of change, and so on) and quantitative analysis on your data. Therefore, the columns (measures) start_time, playback_duration, video_resolution, and playback_quality capture important metrics related to the viewer’s streaming experience that are changing over time. These metrics enable you to perform various analyses, such as calculating the average duration of video sessions, tracking trends in video quality over time, or identifying the preferred video resolutions among viewers. Other useful measure values for a streaming use case could include rebuffering ratio, errors, network bandwidth utilization, throughput, and latency. With these measures, you can gain valuable insights into the viewer’s streaming behavior and make data-driven decisions to improve their overall experience.
Sometimes, relying solely on a dimension or measure description might not be enough. Dimensions could sometimes become measures. Therefore, beginning with query patterns aids in understanding what you’re calculating and on which attributes, helping you decide if it’s a measure or a dimension. If an attribute is used for filtering data and in calculation as well, then it becomes a measure. When making decisions on dimensions, it’s important to consider that the dimensions of a given record can’t be updated and all dimensions uniquely identify a record.
Timestream provides the ability to upsert data. An upsert is an operation that inserts a record into the system when the record doesn’t exist or updates the record when one exists. However, updates are limited to adding new measures or updating measures of an existing record by using all its dimensions in the API.
There are limits on the number of dimensions, measures (maximum measures per record, unique measures across table), and maximum size of a record. These factors should be considered when designing your data model. Often, data ingesting in Timestream originates through an event or metrics that contains additional attributes than what’s needed for time-series analysis. To prevent hitting limits, target only required attributes. When data doesn’t relate and isn’t queried together, using separate tables is better than one consolidated table.
Choosing a partition key
When it comes to partitioning in Timestream, you have the option to choose a partition key or use the default partition, which is based on the measure_name column.
We recommend selecting a partition key based on a dimension with a high cardinality column and frequently used as a predicate in queries. This helps evenly distribute data across partitions and avoid performance issues. In this video streaming use case, column with high cardinality (viewer_id) could be suitable as a partition key. However, the choice depends on the specific use case and which column is frequently used for filtering when making queries and is a high cardinality column. It’s highly recommended to use a customer-defined partition key over default partitioning.
In some cases, there is no attribute that helps distribute the data so you can’t use a customer-defined partition key. In this case, the measure_name is the default way of partitioning data. Make sure that you carefully plan the measure_name attribute design. One recommendation is, if you’re recording different measurements, use those as values. For instance, if you’re collecting pressure and temperature metrics from devices, place those in the measure_name column, as shown in the following example data. This helps evenly distribute the data.
| device_id | measure_name | Time | Quality | Value |
| sensor-123 | temperature | 2023-08-01 19:21:32 | 85 | 43 |
| sensor-123 | temperature | 2023-08-01 19:22:32 | 86 | 44 |
| sensor-123 | pressure | 2023-08-01 19:23:32 | 83 | 31 |
| sensor-123 | pressure | 2023-08-01 19:24:32 | 34 | 123 |
Each table can handle up to 8,192 distinct values for the measure_name column. Therefore, when designing, consider this limit. If you’re unable to find optimal values for the measure_name column or realize that you’ll exceed the limit during the design phase (8,192 unique values), refer to Recommendations for partitioning multi-measure records for further recommendations.
The timestamp, measure_name, and at least a single dimension and measure are mandatory columns while ingesting data into Timestream. The measure_name column is mandatory even when a customer-defined partition key is used, and acts as the partitioning key if the enforce partitioning key option in the record is disabled while creating the table.
Cost and performance optimization
Timestream pricing is usage based, and one of the costs is driven by the volume of data scanned by its serverless distributed query engine during query processing. Data is spread across multiple partitions as new timestamped data is ingested, organized by time, dimensions, and customer-defined partition key or measure_name. It’s advisable to consistently implement time filtering whenever possible (time is the first dimension in Timestream). This is because the query engine specifically scans partitions within the defined time interval, directly impacting cost reduction and performance gain.
Furthermore, in addition to the time filter, it’s recommended to use a customer-defined partition key or measure_name (if default partitioning is used) filter whenever feasible in your queries. By doing so, Timestream efficiently prunes out irrelevant partitions and scans only partitions for that particular time window and partition filter value, thereby enhancing query performance and decreasing costs. While querying, employing all dimensions (including the customer-defined partition key) and measure_name for filtering alongside the time filter can make queries up to 30% quicker.
Querying data without a partitioning key and time filters could result in scanning a larger number of partitions, leading to slower query responses and higher cost.
One of the other cost dimensions on Timestream is storage. After making decisions on dimensions, measures, and partition keys, make sure to eliminate unnecessary data to store from Timestream to save overall cost.
Storing data in Timestream
After you have defined your dimensions and measures, then next important decision that you must make as part of the data modeling exercise is to choose how you store data in Timestream.
You should choose your data types based on how they can be stored in Timestream for writes and querying.
If your application emits JSON objects, they can be converted to JSON strings and stored as VARCHAR type. It’s important to note that downstream codes or applications should be aware of this encoding and handle the decoding appropriately. However, remember that Timestream is designed for time-series data, so organizing your data with individual columns is a best practice to fully take advantage of the capabilities of the service.
For example, suppose a automobile application captures data with the following attributes: vin_number, measures (fuel_consumption, speed, longitude, latitude), and time. You should convert this JSON data into separate columns in your Timestream table.
The following is the original JSON data:
The following is the converted data for Timestream:
| car_vin_number | state | time | fuel_consumption | speed | longitude | latitude |
| 1234567 | in_motion | 2023-07-20T12:34:56.789Z | 80 | 65 | 0.01 | 3.02 |
By converting the data into separate columns, you ensure that Timestream can efficiently store and query the time-series data. Each attribute is now a dedicated column, making it easier for Timestream to perform time-based queries and aggregations.
Single-measure vs. multi-measure records
In Timestream, there are two approaches for storing records: single-measure and multi-measure.
Single-measure records contain only one measure, whereas multi-measure records can have multiple measures. The single-measure records are suitable when you capture different metrics at different time periods, or you are using custom processing logic that emits metrics and events at different time periods. In many use cases, a device or an application you are tracking may emit multiple metrics or events at the same timestamp. In such cases, you can store all the metrics emitted at the same timestamp in the same multi-measure record. Using multi-measure records allows for more flexibility and efficiency in querying data. In many use cases, multi-measure is recommended over single-measure. This approach allows for simultaneous ingestion and querying multiple measures, reducing overall costs and enhancing performance.
The following table shows an example of single-measure records.
| device_id | measure_name | time | measure_value::double | measure_value::bigint |
| sensor-123 | temperature | 2022-01-01 08:00:00 | 25.3 | NULL |
| sensor-123 | humidity | 2022-01-01 08:00:00 | NULL | 50 |
| sensor-123 | pressure | 2022-01-01 08:00:00 | 1014.2 | NULL |
| sensor-456 | temperature | 2022-01-01 08:00:00 | 23.8 | NULL |
| sensor-456 | humidity | 2022-01-01 08:00:00 | NULL | 55 |
| sensor-456 | pressure | 2022-01-01 08:00:00 | 1013.7 | NULL |
The following table shows an example of multi-measure records.
| device_id | measure_name | time | temperature | humidity | pressure |
| sensor-123 | metric | 2022-01-01 08:00:00 | 25.3 | 50 | 1014.2 |
| sensor-456 | metric | 2022-01-01 08:00:00 | 23.8 | 55 | 1013.7 |
Best practices
When modeling data in Timestream, it’s important to consider how data retention policies, encryption keys, access control, limits, query workload, and access patterns will impact the performance and cost of your application:
- Encryption keys are configured at the database level, so data with different encryption requirements should be stored in different databases.
- Data retention policies are configured at the table level, so data with different data retention requirements should be stored in different tables, but can be under the same database.
- Access controls are configured at the database and table level, so data with different access requirements should be stored in different tables.
- Query latency and ease of writing queries can be improved by storing frequently queried data in the same table. Although it’s possible to perform joins in Timestream if the tables are created within the same AWS account and Region, there can be a noticeable difference in performance when querying a single table compared to multiple tables.
Batch writing and effective utilization of CommonAttributes play a crucial role in optimizing data ingestion and achieving cost savings in Timestream. With batch writing, you can efficiently ingest multiple records with a single API call, reducing the number of requests and enhancing overall ingestion performance. This approach enables bulk data ingestion, allowing you to process and store large volumes of data more efficiently and save costs. With CommonAttributes, you can define shared attributes only one time per batch write, which reduces data transfer and ingestion costs. The maximum number of records in a WriteRecords API request is 100.
Additionally, it’s worth highlighting a few other important aspects and resources related to Timestream that will help with data modeling decisions:
- Storage tiers – Timestream offers two storage tiers: memory store and magnetic store. The memory store is optimized for high throughput data writes and fast point-in-time queries. The magnetic store is optimized for lower throughput late-arriving data writes, long-term data storage, and fast analytical queries. Timestream enables you to configure retention policies for both tiers during table creation and also allows you to modify them later. The latest timestamped data is sent to the memory store and, based on the configured retention value which is older timestamped data based on time column, will be moved to the magnetic store. Same applies to magnetic store. When data expires out of the magnetic store, it is permanently deleted. For more information about deciding on your strategy based on your data retrieval and retention requirements, refer to Configuring Amazon Timestream.
- Scheduled queries – With scheduled queries, you can automate the run of queries that perform aggregations, calculations, and transformations on your Timestream data from a source table and load it into a derived table. The scheduled query feature in Timestream is designed to support aggregation and rollup operations, making it ideal for generating data for dashboards and visualizations from the derived table (where data is already aggregated and the amount of data volume is reduced). Refer to Improve query performance and reduce cost using scheduled queries in Amazon Timestream for more information.
Additional resources
For more information, refer to the following resources:
Conclusion
In this post, we showed the key concepts of Timestream and why data modeling is important. We covered video streaming data modeling scenarios in Timestream and dived deep into how data modeling can help with cost optimization and performance. You can now try Timestream with a 1-month free trial.
About the Authors
 Renuka Uttarala is a Worldwide leader for Specialist Solutions architecture, Amazon Neptune, and Amazon Timestream data services. She has 20 years of IT industry experience and has been with AWS since 2019. Prior to AWS, she worked in product development, enterprise architecture, and solution engineering leadership roles at various companies, including HCL Technologies, Amdocs Openet, Warner Bros. Discovery, and Oracle Corporation.
Renuka Uttarala is a Worldwide leader for Specialist Solutions architecture, Amazon Neptune, and Amazon Timestream data services. She has 20 years of IT industry experience and has been with AWS since 2019. Prior to AWS, she worked in product development, enterprise architecture, and solution engineering leadership roles at various companies, including HCL Technologies, Amdocs Openet, Warner Bros. Discovery, and Oracle Corporation.
 Balwanth Reddy Bobilli is a Timestream Specialist Solutions Architect at AWS based out of Utah. He is passionate about databases and cloud computing. Before joining AWS, he worked at Goldman Sachs as a Cloud Database Architect.
Balwanth Reddy Bobilli is a Timestream Specialist Solutions Architect at AWS based out of Utah. He is passionate about databases and cloud computing. Before joining AWS, he worked at Goldman Sachs as a Cloud Database Architect.