Amazon Web Services ブログ
Category: Events

サーバーレス MLflow で Amazon SageMaker AI を使用して AI 開発を加速
2024 年 6 月に MLflow を搭載した Amazon SageMaker AI を発表して以来、弊社 […]

デジタル庁様がAWS re:Invent 2025 で登壇「ガバメントクラウドで実現した俊敏性とコンプライアンスのバランス」
米国ラスベガスで2025年12月1日-5日に開催された AWS re:Invent 2025 では、デジタル庁 […]

新しく強化された AWS サポートプランでは、専門家によるガイダンスに AI 機能が追加されました
2025 年 12 月 2 日、AWS サポートがお客様の支援方法を根本から転換し、事後対応型の問題解決から事 […]

AWS Lambda Durable Functions を使用して複数ステップのアプリケーションと AI ワークフローを構築
現代のアプリケーションでは、複数段階の支払い処理、AI エージェントのオーケストレーション、または人間の決定を […]

Amazon GuardDuty が Amazon EC2 と Amazon ECS に Extended Threat Detection 機能を追加
2025 年 12 月 2 日、Amazon Elastic Compute Cloud (Amazon EC […]
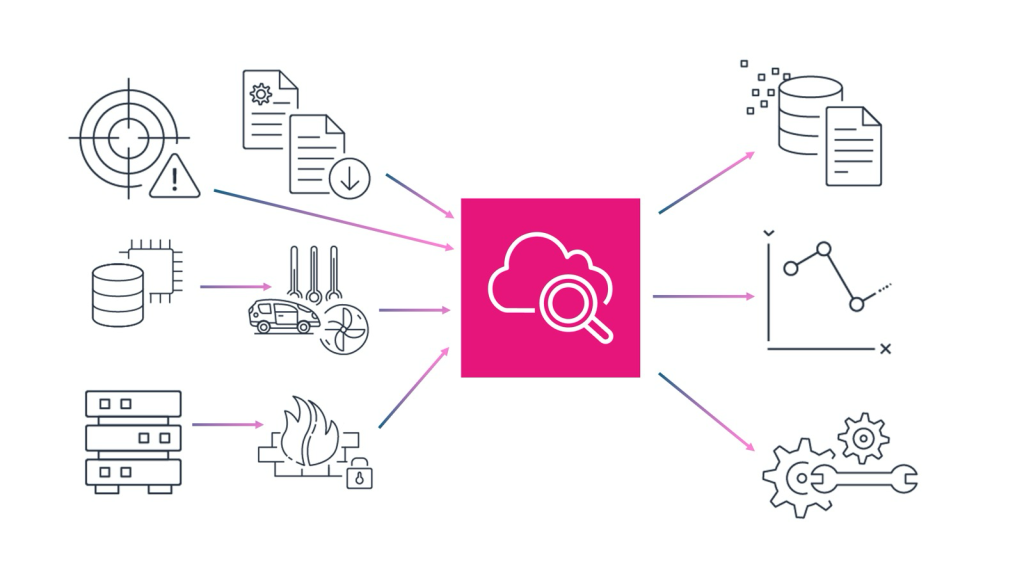
Amazon CloudWatch は、運用、セキュリティ、コンプライアンスのための統合データ管理と分析を導入します
2025 年 12 月 2 日、Amazon CloudWatch の機能を拡張して、運用、セキュリティ、コン […]

Amazon Nova 2 Sonic の紹介: 会話型 AI 向けの新しい音声変換モデル
2025 年 12 月 2 日、自然でリアルタイムな音声対話をアプリケーションにもたらす音声変換の基盤モデル […]

メモリを多用するワークロード向けの第 5 世代 AMD EPYC プロセッサを搭載した Amazon EC2 X8aedz インスタンスの紹介
2025 年 12 月 2 日、第 5 世代 AMD EPYC プロセッサを搭載した、メモリを最適化した新しい […]

新しい AWS Security Agent は、設計からデプロイ (プレビュー) までアプリケーションをプロアクティブに保護します
2025 年 12 月 2 日、開発ライフサイクル全体を通じてアプリケーションを積極的に保護するフロンティアエ […]

Amazon RDS for SQL Server と Amazon RDS for Oracle のコストを最適化し、スケーラビリティを向上させる新機能
データベース環境を管理するには、リソース効率とスケーラビリティのバランスが必要です。組織は、データベースライフ […]