AWS Database Blog
Amazon Aurora Under the Hood: Fast DDL
Anurag Gupta runs a number of AWS database services, including Amazon Aurora, which he helped design. In the Under the Hood series, Anurag discusses the design considerations and technology underpinning Aurora.
Amazon Aurora is a MySQL-compatible database that combines the speed and availability of high-end commercial databases with the simplicity and cost-effectiveness of open-source databases. In this post, let’s look at how Amazon Aurora has a taken a common data definition language (DDL) statement that typically requires hours to complete in MySQL and made it near-instantaneous. This feature is currently available in lab mode, in Aurora version 1.12 or later.
What is fast DDL, and why do I care?
Applications change—you need to change the underlying database schema in response. Query workloads change—you need to add or drop indexes. Data formats change—you need to change the datatypes for existing columns. And change can happen frequently. Some DBAs supporting Ruby on Rails applications say that they make dozens of schema changes weekly.
As any MySQL DBA knows, these schema changes can disrupt production systems. They are slow. They can take hours or days to complete. They hog system resources. They reduce the throughput of the actual application. Long-running operations can require long crash recoveries. They require write locks for portions of the DDL operation, making parts of the application unavailable. They can require a lot of temporary space and can run out of disk on smaller instances.
We’re addressing this mess, starting with the most common DDL operation we’ve seen: adding a nullable column at the end of a table.
Why is the current approach so painful?
Let’s take a look at how MySQL implements adding a nullable column at the end of a table.
Here’s the MySQL sequence of operations:
- The database takes an exclusive lock on the original table during the prepare phase of the transaction.
- It creates a new, empty table with the desired schema.
- It copies over one row at a time, updating indexes as it goes. Concurrent data manipulation language (DML) statements are logged into a temp file.
- It once again takes an exclusive lock and applies the DML operations from the temp file to the new table. If there are a lot of operations to apply, this process can take a while.
- It then drops the original table and renames the new table to be the original table.
There’s a lot of locking, a lot of overhead copying data and building indexes, a lot of I/O, and for active tables, a lot of temp space being used.
Is there a better way?
You might think that there’s little to be done about this. After all, the data format for each and every row does need to change. But there’s a lot that can be done by piggybacking this change on top of other DML (and associated I/O) operations being performed on the table. The full approach is a bit too complex for a blog post, but here’s a brief sketch.
In Aurora, when a user issues a DDL statement:
- The database updates the INFORMATION_SCHEMA system table with the new schema. In addition, the database timestamps the operation, records the old schema into a new system table (Schema Version Table), and propagates this change to read replicas.
That’s it for the synchronous part of the operation. Done.
Then, on subsequent DML operations, we check to see if the affected data page has a pending schema operation. That’s easily done by comparing the log sequence number (LSN) timestamp for the page with the LSN timestamp of schema changes. If needed, we then update the page to the new schema before applying the DML statement. This operation follows the same upgrade process for redo-undo record pages as everything else. And any I/Os are piggybacked on top of user activity.
You have to be careful about only upgrading the page on DML operations, because upgrades can cause page splits. We need to deal with upgrades on our Aurora Replicas too, and they’re not allowed to change any data. For SELECT statements, we change the memory image of the buffer being passed back to MySQL. This way, it always sees the latest schema, even though the underlying storage is a mix of old and new schema formats.
If you’re familiar with how Aurora does redo change application on reads from storage, you’ll see the approach is a similar one. However, this approach uses a table to record the changes to perform rather than a segmented redo log.
Here’s a performance comparison—you can see that Aurora is doing a constant time operation updating the Schema Version Table. In contrast, regular MySQL grows in near linear fashion with table size.
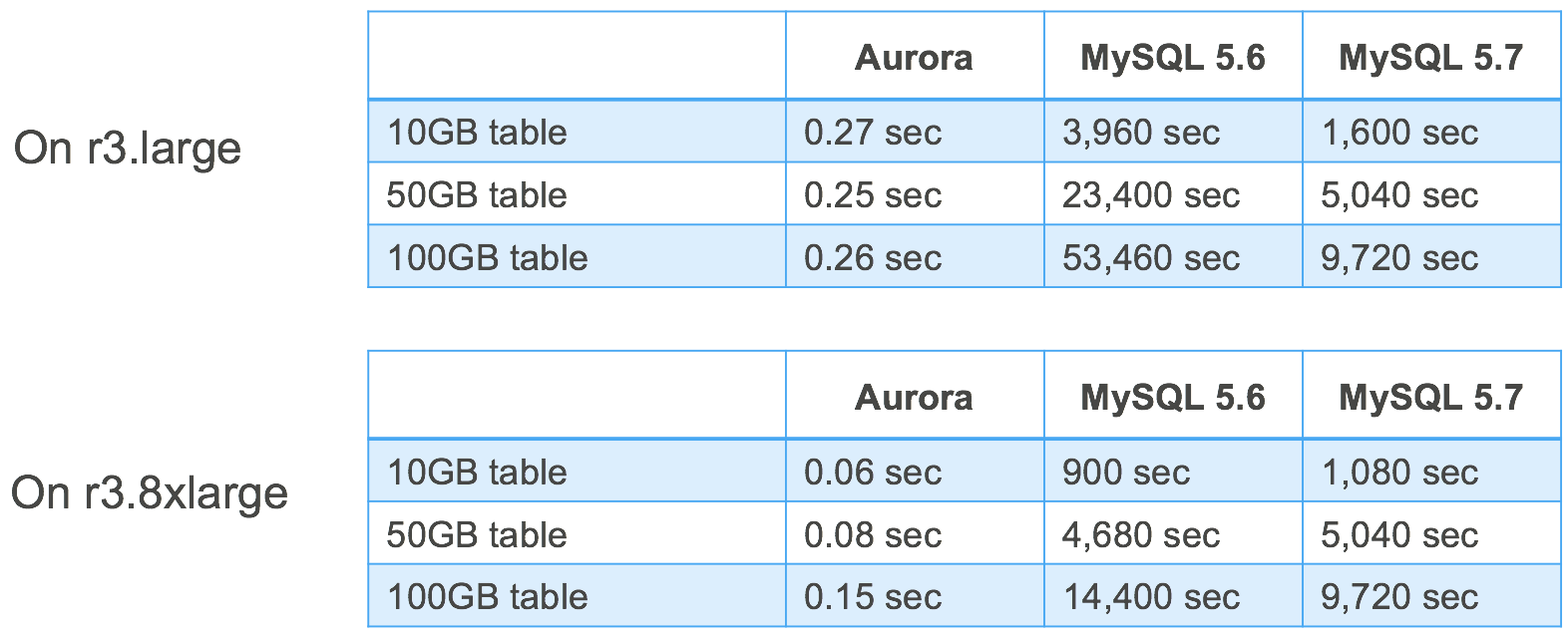
There are obviously lots of other DDL operations for us to improve, but we’re pretty sure that most can be approached the same way. This stuff matters—even if the database is up by normal definitions of availability, application usage is impaired on these long operations. Moving them to parallel, background, and asynchronous execution makes a difference.
Have follow-up questions or feedback? Ping us at aurora-pm@amazon.com, or leave a comment here. We’d love to get your thoughts and suggestions.