Category: Amazon Elasticsearch Service
Amazon Kinesis 업데이트 – Amazon Elasticsearch Service 통합, 샤드 통계 및 시간 기반 반복 기능
Amazon Kinesis는 대용량 스트리밍 데이터를 클라우드에서 손쉽게 처리할 수 있도록 도와 줍니다.
Amazon Kinesis 플랫폼은 3개의 서비스로 구성되어 있습니다: Kinesis Streams은 개발자가 자신의 스트리밍 데이터 처리 애플리케이션을 구현할 수 있습니다; Kinesis Firehose를 통해 스트리밍 데이터를 저장하고 분석하기 위해 AWS에 저장하는 기능에 초점을 맞추었습니다; Kinesis Analytics 를 통해 스트리밍 데이터를 표준 SQL을 통해 분석 할 수 있습니다.
많은 AWS 고객이 스트리밍 데이터를 실시간으로 수집 · 처리하는 방식으로 Kinesis Streams와 Kinesis Firehose을 이용하고 있습니다. 이는 완전 관리 서비스이기 때문에 사용 편의성을 높아 스트리밍 데이터 처리를 위한 인프라를 직접 관리하는 대신 응용 프로그램에 개발하는 시간에 투자를 할 수 있다는 장점이 있습니다.
오늘 Amazon Kinesis Streams와 Kinesis Firehose 관한 3개의 새로운 기능을 신규 발표합니다.
- Elasticsearch 통합– Amazon Kinesis Firehose는 Amazon Elasticsearch Service에 스트리밍 데이터를 전달할 수 있습니다..
- 강화된 모니터링 수치 제공– Amazon Kinesis는 샤드 단위 메트릭을 CloudWatch로 매 분당 보낼 수 있습니다.
- 유연성 확보– Amazon Kinesis에서 시간 기반의 반복자를 이용하여 레코드를 수신 할 수 있습니다.
Amazon Elasticsearch Service 통합
Elasticsearch
는 인기있는 오픈 소스 검색 · 분석 엔진입니다. Amazon Elasticsearch Service는 AWS 클라우드에서 Elasticsearch를 손 쉽게 설치하고, 높은 확장성을 가지고 운영할 수 있는 관리 서비스입니다. 오늘 부터 Kinesis Firehose 데이터 스트림을 Amazon Elasticsearch Service 클러스터에 배포 할 수 있게되었습니다. 이 새로운 기능은 서버의 로그 및 클릭 스트림, 소셜 미디어 트래픽 등으로 인덱스를 생성하고 분석 할 수 있습니다.
전송 받은 레코드 (Elasticsearch 문서)는 지정한 설정에 따라 Kinesis Firehose에서 버퍼링 된 후,여러 문서를 동시에 인덱스를 만들 수 있도록 벌크 요청을 사용하여 자동으로 클러스터를 추가합니다. 또한, 데이터는 Firehose로 전송하기 전에 UTF-8로 인코딩 된 단일 JSON 개체에 두어야 합니다. (관련 정보는 Amazon Kinesis Agent Update – New Data Preprocessing Feature를 참조하십시오).
이제 AWS 관리 콘솔을 통한 설정 방법을 알아보겠습니다. 대상(Amazon Elasticsearch Service)를 선택하고 전송 스트림의 이름을 입력합니다. Elasticsearch 도메인 (livedata 예제)을 선택 인덱스로 지정하고, 인덱스 주기(없음, 시간별, 매일, 매주, 매월)를 선택합니다. 또한, 모든 문서 또는 실패한 문서의 백업을받을 S3 버킷을 지정합니다 :
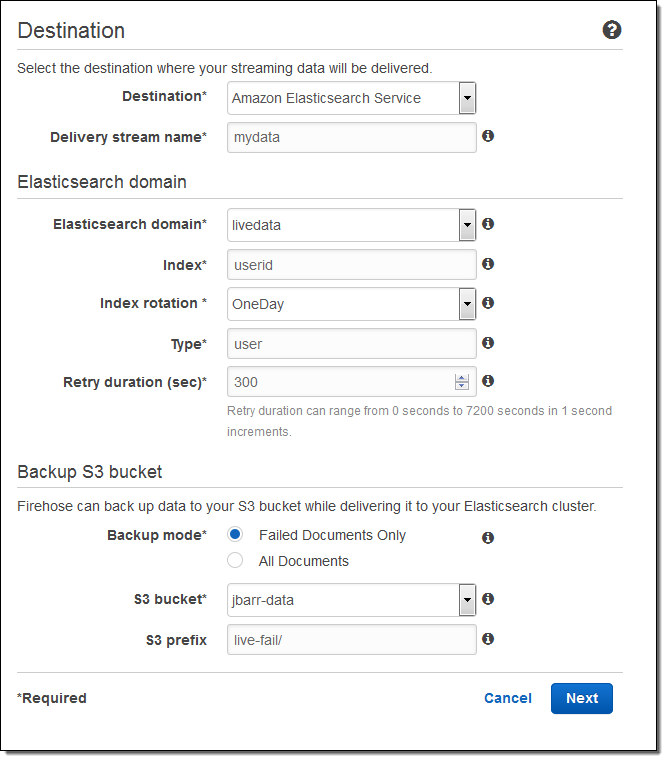
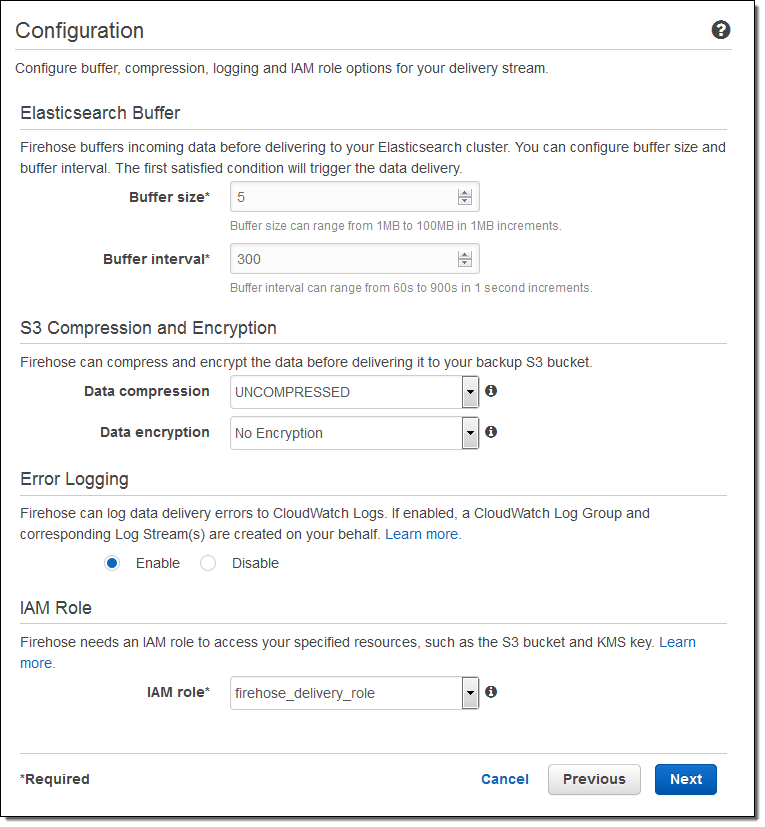
그리고 버퍼의 크기를 지정하고 S3 버킷에 전송되는 데이터의 압축 및 암호화 옵션을 선택합니다. 필요에 따라 로깅을 사용하고 IAM 역할을 선택합니다 :
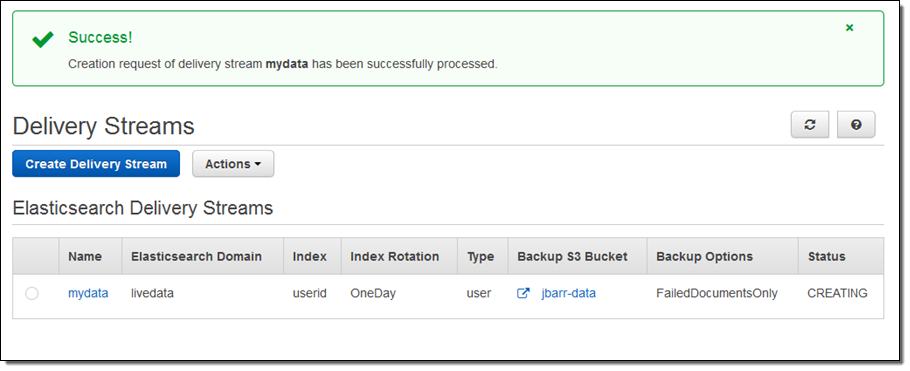
1분 정도 이후에 스트림이 준비 됩니다 :
I can view the delivery metrics in the Console:
스트리밍 데이터가 Elasticsearch에 도달 한 후에는 Kibana와 Elasticsearch 쿼리 언어에 의해 데이터 시각화를 할 수 있습니다.
즉, 통합을 통해 여러분의 스트리밍 데이터를 수집하고 Elasticsearch에 전달 하기 위한 처리 방법은 매우 간단합니다. 더 이상 코드를 작성하거나 자체 데이터 수집 도구를 만들 필요가 없습니다.
샤드 기반 통계 모니터링
모든 Kinesis 스트림은 하나 이상의 샤드로 구성되어 있으며, 모든 샤드는 일정량의 읽기 · 쓰기의 용량을 가지고 있습니다. 필요에 따라 스트림에 샤드를 추가하면 스트림의 용량은 증가합니다.
여러분은 각 샤드의 성능을 파악하기위한 목적으로 샤드 단위의 통계 기능을 활성화 할 수 있게되었습니다. 샤드 당 6개의 메트릭이 있습니다. 각 통계는 1 분에 한 번 보고되고, 일반 통계 단위의 CloudWatch 요금이 부과됩니다. 이러한 신규 기능은 특정 샤드에 부하가 편중되지 않았는지, 다른 샤드와 비교하여 확인하거나 스트리밍 데이터의 전송 파이프 라인을 통해 비효율적 인 부분을 발견 및 변경할 수 있게 됩니다.
아래에는 새로이 측정되는 수치입니다.
IncomingBytes – 샤드로 PUT이 성공한 바이트 수.
IncomingRecords – 샤드로 PUT이 성공한 레코드.
IteratorAgeMilliseconds –샤드에 대한 GetRecords 호출이 취소 된 마지막 레코드의 체류 시간 (밀리 초). 값이 0 인 경우, 읽은 레코드가 완전히 스트림에 붙어 있다는 것을 의미합니다.
OutgoingBytes – 샤드에서받은 바이트 수.
OutgoingRecords – 샤드에서받은 레코드 수.
ReadProvisionedThroughputExceeded – 매초 5 회 또는 2MB를 초과한 GetRecords 호출 수.
WriteProvisionedThroughputExceeded – 매 초 1000 기록 또는 1MB를 초과한 레코드의 수.
EnableEnhancedMetrics 를 호출하는 것으로 활성화 할 수 있습니다. 평소처럼, 일정 기간 동안 집계를 위해 CloudWatch API를 사용할 수 있습니다.
시간 기반 반복 기능
어떤 샤드에 GetShardIterator를 호출 시작점으로 지정하고, 반복 기능을 작성하여 애플리케이션에서 Kinesis 스트림 데이터를 읽을 수 있습니다. 기존의 시작점 선택 (시퀀스 번호 시퀀스 번호 뒤에 가장 오래된 기록, 가장 새로운 레코드)에 추가로 타임 스탬프를 지정할 수 있게되었습니다. 지정한 값 (UNIX 시간 형식)은 읽고 처리하려고하는 가장 오래된 레코드의 타임 스탬프를 나타냅니다.
— Jeff;
이 글은 Amazon Kinesis Update – Amazon Elasticsearch Service Integration, Shard-Level Metrics, Time-Based Iterators의 한국어 번역입니다.
Amazon Elasticsearch 및 CloudSearch 서비스 서울 리전 출시
Amazon Elasticsearch Service (Amazon ES) 및 Amazon CloudSearch 서비스가 AWS Asia Pacific (Seoul) 리전에 출시 되었습니다.

Amazon ES는 Elasticsearch 서비스를 좀 더 쉽게 개발, 배포 운영할 수 있는 매니지드 서비스이며, Amazon CloudSearch 역시 웹 애플리케이션에 대한 간편한 검색 서비스를 가능하게 해주는 클라우드 서비스입니다.
서울 리전에 대한 서비스 가격은 Amazon ES 요금표 및 Amazon CloudSearch 요금표를 참고하시기 바랍니다.
Amazon Elasticsearch Service and Amazon CloudSearch Available in Asia Pacific (Seoul) Region 참고
Amazon Elasticsearch Service 공개
Elasticsearch은 실시간 분산 검색 및 분석 엔진으로서 클라우드 환경에 잘 맞는 검색 도구입니다. 문서 지향 엔진으로 스키마(Schema)를 미리 정의할 필요가 없습니다. 정형 및 비정형 데이터 구조도 지원하고 시간 기반 쿼리 및 Kibana 같은 시각화 도구를 활용할 수도 있습니다.
오늘 Amazon Elasticsearch Service (약자로 Amazon ES) 신규 서비스를 공개합니다. 이제 여러분은 AWS 관리 콘솔에서 몇 분 만에 확장성 높은 Elasticsearch 클러스터를 실행할 수 있습니다. 각 클러스터의 클라이언트를 지정하고 데이터를 가져와서 처리하고 분석하는 서비스를 할 수 있습니다.
검색 도메인 생성
먼저 Amazon ES 도메인을 생성해 보겠습니다. AWS Command Line Interface (CLI), AWS Tools for Windows PowerShell 및 the Amazon Elasticsearch Service API를 활용할 수 도 있습니다. 시작하기 버튼을 눌러서 검색 도메인 명을 입력합니다.(my-es-cluster 선택):
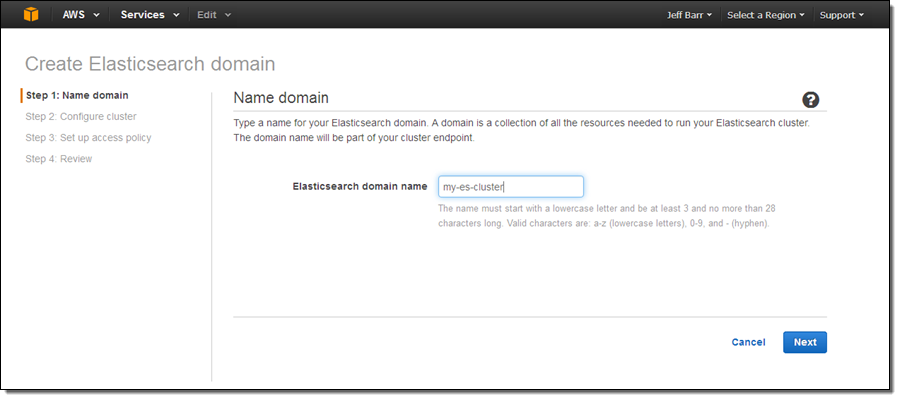
두번째로 인스턴스 타입 및 갯수를 입력합니다.(둘 다 나중에 변경 가능)
여기에 몇 가지 인스턴스 가이드 라인을 참고하실 수 있습니다.
- T2 – 개발 및 테스트 (마스터 노드로 사용하면 좋음)
- R3 – 읽기가 많거나 복잡한 쿼리를 수행 하는 경우 (e.g. nested aggregations)
- I2 – 쓰기가 많거나 대용량 데이터 스토리지가 필요한 경우
- M3 – 읽기 및 쓰기에 균형이 있는 경우
‘Enable dedicated master’을 설정하면, Amazon ES를 통해 클러스터에 대한 마스터 노드를 생성합니다. 이 옵션을 선택하고 클러스터 안정성을 위해 적어도 3개 정도의 노드를 만드실 것을 권장합니다.
만약 Enable zone awareness를 체크하시면, 노드는 다중 가용 영역(AZ)에 배포 되며 고가용성을 제공할 수 있습니다. 이를 선택하시면 Elasticsearch Index API를 통해 리플리카 설정이 필요합니다. 또한, 같은 API를 이용해야 새로운 인덱스를 만들 수도 있습니다. (더 자세히 보기).
노드용 스토리지로 EBS General Purpose (SSD)를 사용하여 데이터를 저장할 수 있으며, 다른 볼륨 형식을 선택하여도 됩니다. EBS를 사용하면 더 많은 데이터를 저장할 수 있고 더 저렴한 비용으로 인스턴스 실행이 가능합니다. 인스턴스에 연결된 스토리지라면 더 나은 성능을 보장합니다. 대량 데이터는 I2 인스턴스를 실행할 수 있으며 노드당 1.6TB의 데이터를 저장할 수 있습니다.
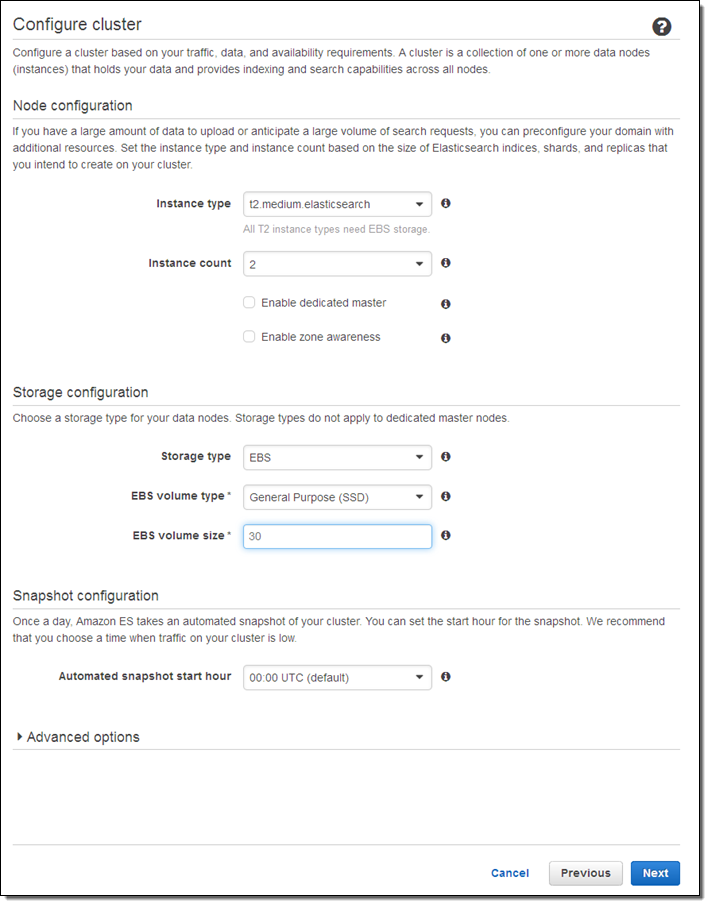
다음에는 접근 정책을 설정하는 것인데 간단한 테스트를 위한 것이므로 대부분 기능을 열어두었지만, 여러분 클러스터는 자세히 설정하시기 바랍니다. IP기반 혹은 사용자 템플릿 기반 접근 정책을 기반으로 마법사 형식으로 접근 제한 정책을 만들 수 있습니다.
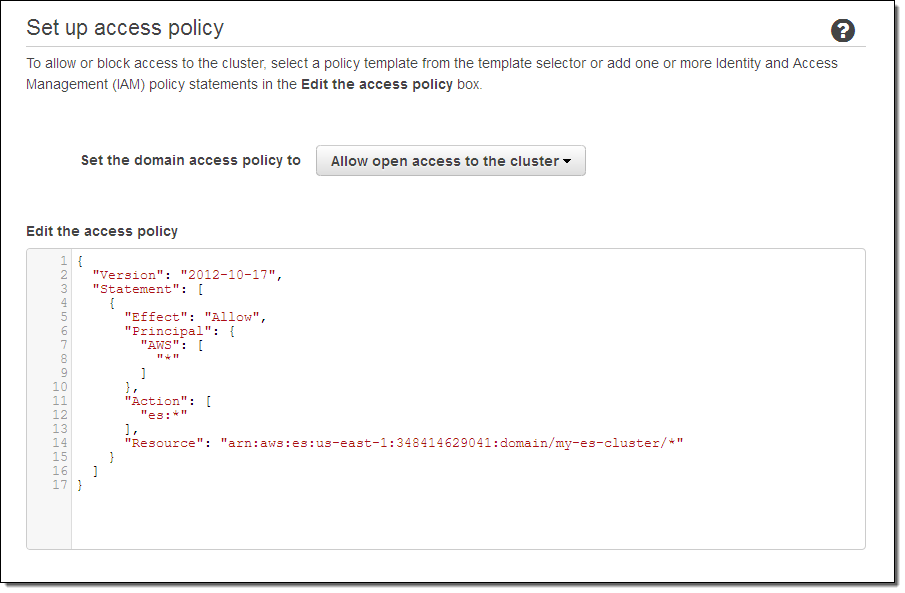
설정을 다 마친 후 Confirm and create를 선택 하시면 됩니다.
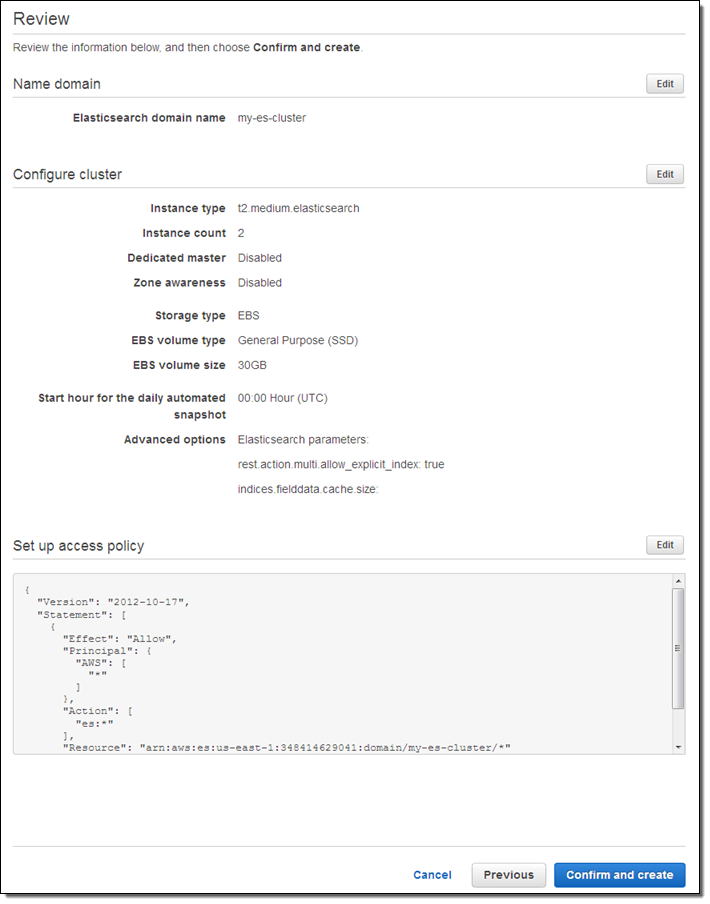
클러스터가 몇 분 안에 만들어 지면 대시보드에 나타납니다.
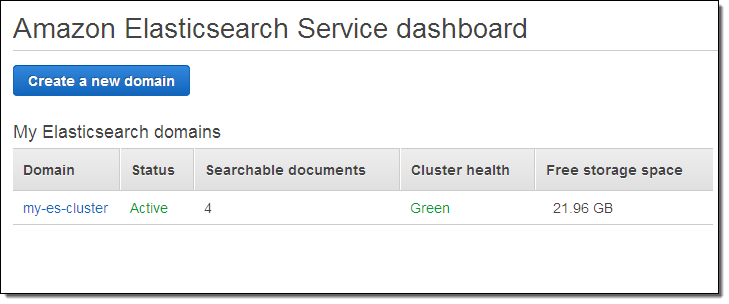
이제 기본 클러스터 설정을 완료하였습니다.
검색 문서 가져오기
다음 단계로 검색할 문서를 가져와 테스트해 보는 것인데, 처음 해보시는 분이라면 Having Fun: Python and Elasticsearch, Part 1을 따라서 해 보시길 추천합니다. Elasticsearch를 위한 Python 라이브러리를 설치한 후, 관리 콘솔에서 지정한 클러스터 엔드포인트에서 시작하면 됩니다.
제가 미리 해본 결과 잘 동작하는 것을 알 수 있었으며, 위의 블로그 글에 있는 Python 코드를 통해 샘플 데이터를 만들어 실행 해 볼 수 있습니다. 아래는 샘플 문서 가져오기 결과 스크린샷입니다.
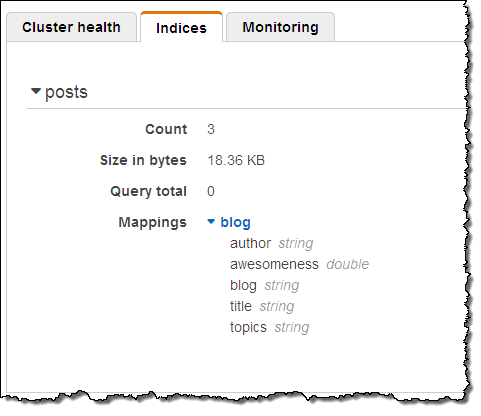
검색 문서 질의하기
샘플 데이터를 가져왔다면 이제 Kibana 링크를 눌러 보시기 바랍니다.
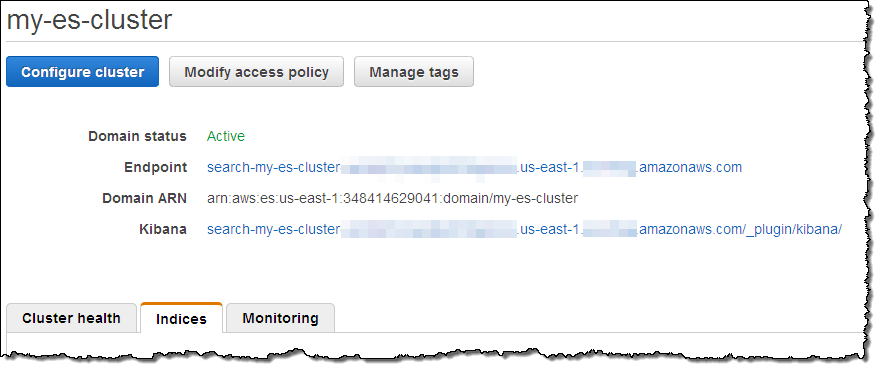
Kibana (v4)을 웹 브라우저의 다른 탭으로 열고 나서 블로그 글을 인덱스 설정을 합니다.
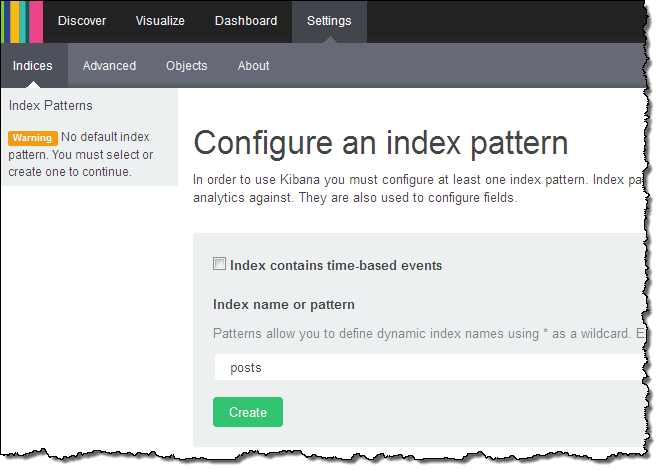
Kibana를 통해 도메인 내 항목을 설정합니다.
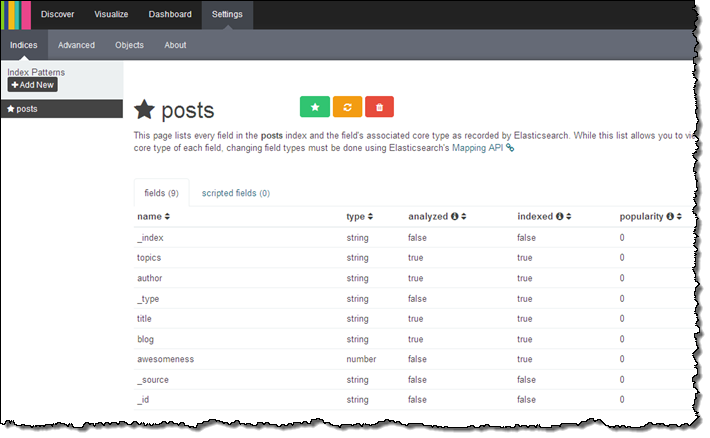
시간이 좀 지난 후, Kibana를 통해 데이터 시각화를 할 수 있습니다.
Kibana 3 역시 지원이 가능합니다. 이를 사용하려면, 클러스터 엔드포인트에 _plugin/kibana3/ 플러그인을 연결하면 됩니다.
기타 기능 알아보기
여러분이 설정한 클러스터는 CLI (aws es update-elasticsearch-domain-configuration), API (UpdateElasticsearchDomainConfig) 및 콘솔에서 접근할 수 있습니다. Amazon ES 클러스터 설정 신규 데이터 복사 등 새로운 설정을 간단하게 다운타임 없이 할 수 있습니다.
오늘 Amazon ES 서비스 공개와 아울러 CloudWatch 로그 통합도 가능합니다. CloudWatch 로그를 Amazon ES로 연결 가능한데, Amazon ES 도메인을 만든 후 Cloudwatch Logs 콘솔에서 Subscribe to Lambda / Amazon ES를 선택하기만 하면 됩니다.
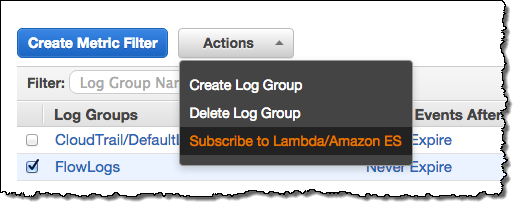
여기서 들어오는 로그의 패턴을 찾아 설정할 수도 있습니다. (패턴 설정은 선택사항이지만 로그의 스키마를 정의할 수 있습니다.) 아래에는 몇 가지 Kibana 대시보드 샘플 예제들이 있고 여러 가지 형식의 로그를 모니터링 하는데 사용할 수 있습니다. ,
- VPC Flow Dashboard – 로그 항목의 패턴을 정하는 데 필요
[version, account_id, interface_id, srcaddr, dstaddr, srcport, dstport,.
protocol, packets, bytes, start, end, action, log_status] - Lambda Dashboard – 로그 항목의 패턴을 정하는 데 필요
[timestamp=*Z, request_id="*-*", event]. - CloudTrail Dashboard – 패턴 지정 필요 없음 로그 항목에서 자동으로 JsON 형식으로 인지
Amazon ES는 ICU Analysis 및 Kuromoji 플러그인 역시 지원합니다. Elasticsearch Mapping API를 통해 정상적으로 설정이 가능합니다. Amazon ES는 아직 Shield나 Marvel 같은 상용 플러그인은 지원하지 않습니다. 이들 플러그인의 대체제로서 AWS Identity and Access Management (IAM) 및 CloudWatch기능을 활용하시면 됩니다.
Amazon ES 는 자동으로 매일 클러스터의 스냅샷을 떠서 14일동안 저장합니다. 저장한 백업에서 클러스터를 복구하시려면 저희에게 알려주시면 됩니다. “automated snapshot hour”를 통해 백업이 일어날 시점을 정할 수 있으며, Elasticsearch Snapshot API을 통해 스냅샷 백업을 가져와서 S3 버킷에 저장하거나 가져와서 클러스터 복구를 할 수 있습니다.
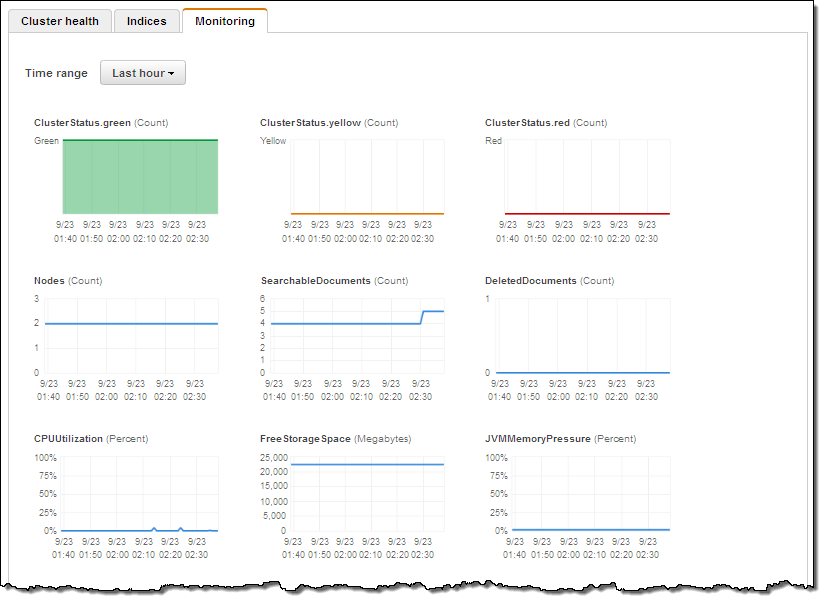
각 Amazon ES 도메인은 17개의 개별 통계치를 CloudWatch로 전송합니다. Amazon ES 콘솔의 모니터 탭을 통해 이들 정보를 살펴 보실 수 있습니다. 클러스터 상태에 대해 (초록, 노란색 혹은 붉은 색상으로) 확인하실 수 있고, 모든 샤드(Shards)가 노드에 잘 연결되어 있으면 초록색, 최소 1개 이상의 샤드가 연결되어 있지 않으면 주황색, 1개 이상의 기본 샤드(Primary Shard)가 노드에 연결되어 있지 않으면 붉은 색으로 구분됩니다. 클러스터가 싱글 노드를 가지고 있으며, 리플리케이션이 1(Logstash 기본 설정)로 설정 되어 있다면 노란색으로 표시됩니다. 이 문제를 간단히 고치려면 새로운 노드를 하나 더 추가하기만 하면 됩니다.
CPU 활용도는 (읽기 및 쓰기 같은) 요청 처리에 직접적으로 영향을 주는 지표입니다. 이 수치가 높다면 리플리케이션을 증가 시키거나 새로운 인스턴스를 노드에 추가하는 것이 추가적인 병렬 처리에 도움이 됩니다. JVM 메모리 용량이 많이 필요할 때도 인스턴스 수를 높히거나 R3 인스턴스로 바꿀 필요가 있습니다. 이러한 사항을 숙지하고, CloudWatch 수치 변화에 대해 알람을 설정하고, 10-20%의 여유 공간을 두고 CPU를 활용하시면 됩니다.
지금 사용해 보기
오늘 부터 Amazon ES 클러스터를 US East (Northern Virginia), US West (Northern California), US West (Oregon), Asia Pacific (Tokyo), Asia Pacific (Singapore), Asia Pacific (Sydney), South America (Brazil), Europe (Ireland), 및 Europe (Frankfurt) 리전에서 바로 사용해 보실 수 있습니다.
AWS 프리 티어를 활용하여 t2.micro.elasticsearch 노드를 월 750시간 무료로 사용 가능합니다. 10 GB의 EBS 볼륨 역시 무료로 사용 가능합니다.
— Jeff;
이 글은 New – Amazon Elasticsearch Service의 한국어 번역입니다.