Category: Amazon Kinesis
Amazon Kinesis Analytics – SQL 기반 실시간 데이터 분석 서비스 정식 공개
Amazon Kinesis 클라우드 내 실시간 데이터 처리를 위한 강력한 도구로서 Kinesis Stream 및 Kinesis Firehose를 통해 손쉽게 대량 실시간 데이터를 처리 및 저장하고 이를 분석할 수 있습니다.
이들 서비스로 상대적으로 쉽게 스트리밍 데이터에 대한 처리가 간편해졌지만, 개발자 및 데이터 과학자 또는 SQL을 잘아는 분석가들이 웹 애플리케이션의 클릭 데이터나 인터넷 연결 기기에서 오는 센서 데이터, 서버 로그 등을 일반적인 쿼리 언어로 분석할 수 있도록 하는 좀 더 쉬운 기능을 제공하고자 합니다.
Amazon Kinesis Analytics
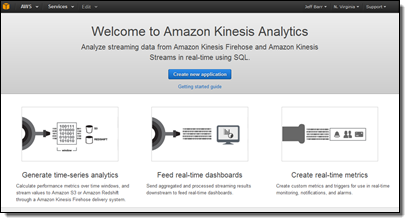 오늘 Amazon Kinesis Analytics를 정식 공개합니다. 스트리밍 데이터에 대한 SQL 질의를 통해 바로 유입되는 데이터에 대해 필터링, 변환 및 요약 등의 기능을 수행할 수 있어, 오로지 데이터와 그것의 비지니스 가치에만 집중함으로서 인프라 구축을 하는 시간 낭비를 줄일 수 있습니다. 5분 만에 SQL 질의를 통한 실시간 데이터 처리 파이프라인을 생성할 수 있습니다.
오늘 Amazon Kinesis Analytics를 정식 공개합니다. 스트리밍 데이터에 대한 SQL 질의를 통해 바로 유입되는 데이터에 대해 필터링, 변환 및 요약 등의 기능을 수행할 수 있어, 오로지 데이터와 그것의 비지니스 가치에만 집중함으로서 인프라 구축을 하는 시간 낭비를 줄일 수 있습니다. 5분 만에 SQL 질의를 통한 실시간 데이터 처리 파이프라인을 생성할 수 있습니다.
데이터베이스 테이블에 대해 SQL 질의 실행을 생각해 보면, 정적인 데이터 처리 방식(데이터 추가, 변경, 삭제)이지만 Kinesis Analytics 질의는 초당 새로운 데이터가 들어와 변경될 때 마다 지속적으로 실행됩니다. 한번 실행을 해 보면, 질의 처리 모델에 대해 쉽게 이해할 수 있습니다. 주어진 질의에 대한 처리를 할 때, 세 가지의 처리 “윈도(window)”를 지원합니다.
Tumbling 윈도는 주기적 리포팅에 사용됩니다. 시간에 따른 데이터 요약시 필요하며, 예를 들어 초당 수천에서 수백만 건의 데이터가 오는 경우, 매 분당 얼마나 데이터가 오는지 확인할 수 있습니다. 첫 텀블링 윈도가 닫히면, 다음 윈도가 시작되어 새 데이터가 쌓이게 됩니다.
Sliding 윈도는 트렌드를 감지하는 모니터링에 사용됩니다. 예를 들어, 실시간으로 평균 오류 비율을 산정하는데 활용할 수 있습니다. 데이터가 윈도에 들어가면, 그 안에 있을 때 데이터 계속 보존되고, 새로운 데이터가 들어오면 새 결과가 생성되는 식입니다. 결과를 좀 더 민감하게 얻고 싶으면 크기를 조정할 수 있습니다.
Custom 윈도는 시간과 관계 없이 적당한 그룹을 만들 때 사용됩니다. 클릭 데이터나 서버 로그를 다룰 때 sessionization이라는 방식을 통해 처리할 수 있습니다. 즉, 각 사용자에 의해 처음 또는 마지막 동작에 대한 질의를 던진다고 할 때, 들어오는 데이터에 대한 세션 인식자를 통해 처리하며 여러분의 사이트에서 보낸 시간이나 각 사용자의 방문 페이지를 알아볼 수 있습니다.
다소 복잡하게 보일 수 있으나, Kinesis Analytics에서는 들어오는 실시간 데이터를 분석해서 적당한 처리 스키마를 제안해 주게 됩니다. 제안된 모델을 따라 질의를 하거나, 실제 데이터 모델에 맞는 좀 더 나은 모델을 튜닝할 수 있습니다. 일단 스키마가 정의되면, 자체 제공 SQL 에디터를 통해 질의 문법을 체크하거나 실시간 데이터에 대해 테스트 할 수 있습니다. 질의 결과는 Amazon S3, Amazon Redshift, Amazon Elasticsearch Service나 Amazon Kinesis Stream으로 전달 할 수 있습니다.
Amazon Kinesis Analytics 시작하기
이제 Amazon Kinesis Analytics을 실제로 사용해 보겠습니다. Amazon Kinesis Analytics 콘솔에서 Create new application을 누르고, 앱 이름을 설정합니다.
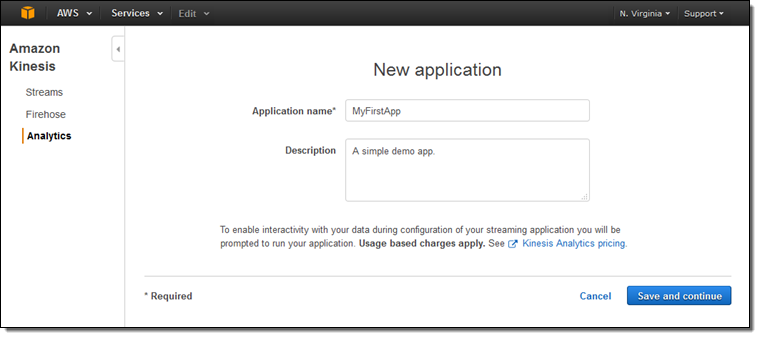
이제 데이터 소스, 질의문 및 최종 저장 위치를 정할 수 있습니다.
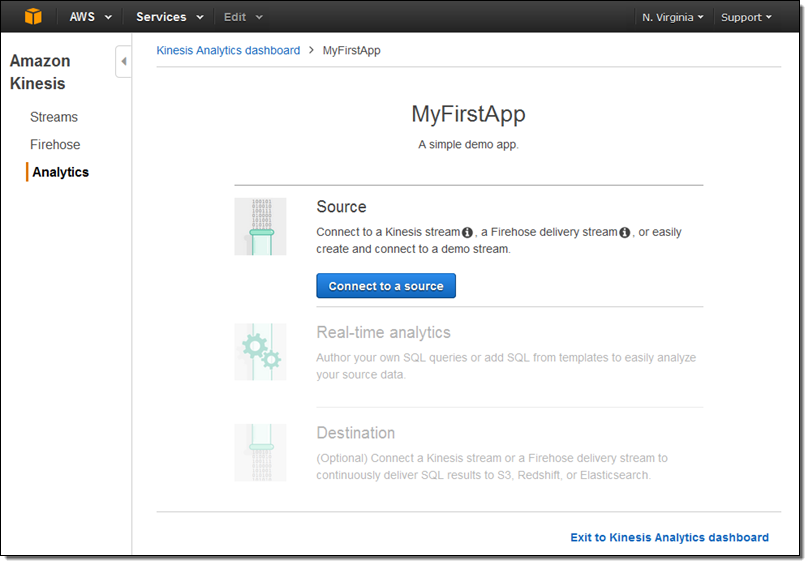
기존의 입력 스트림 중 하나를 선택합니다.
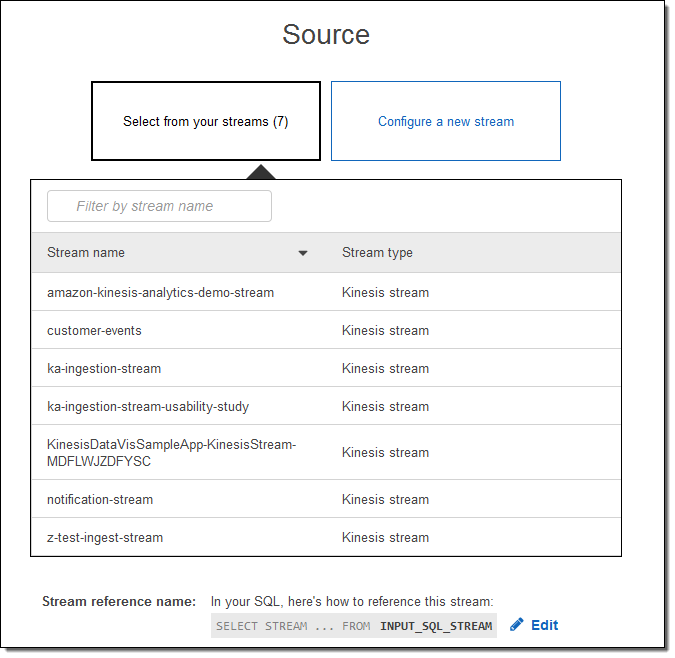
또는, 새로 만들 수 있습니다. (새로 만들어 보겠습니다.)
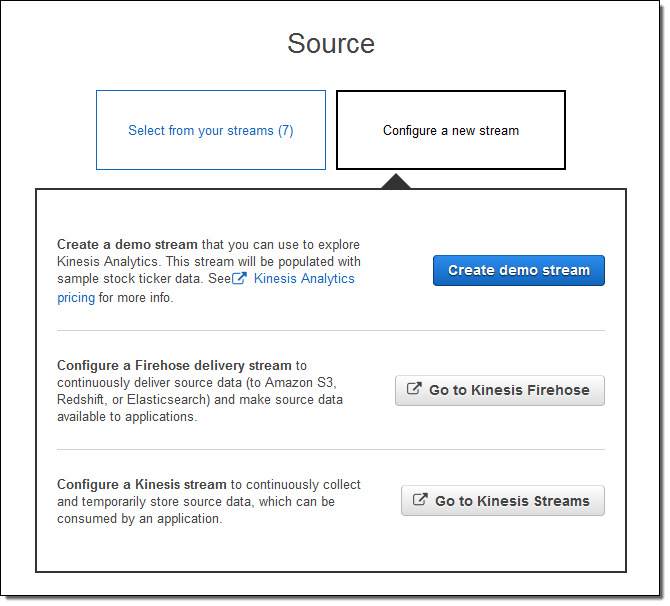
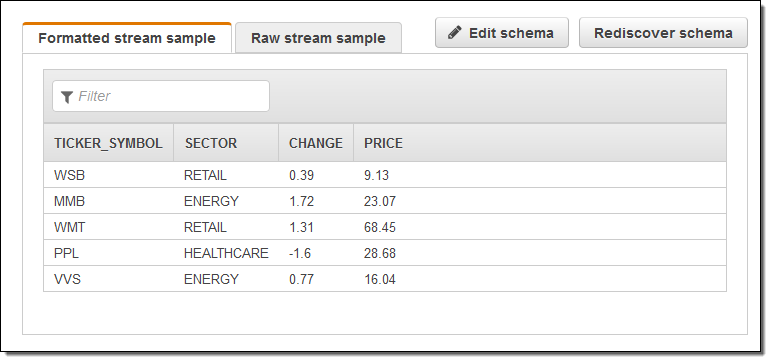
Create demo stream을 선택합니다. 데모 스트림은 샘플 증권 데이터를 실시간으로 만들어 주는 것으로 생성하는데 약 30-40초 정도 걸립니다.
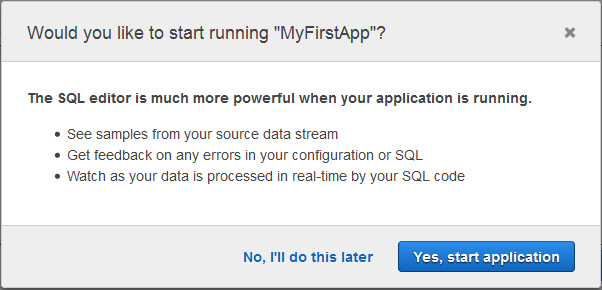
이제 SQL 에디터로 넘어갑니다. 앱을 만들기 위해 동의 버튼을 눌러 애플리케이션을 시작합니다.
아래는 SQL 에디터의 모습입니다.
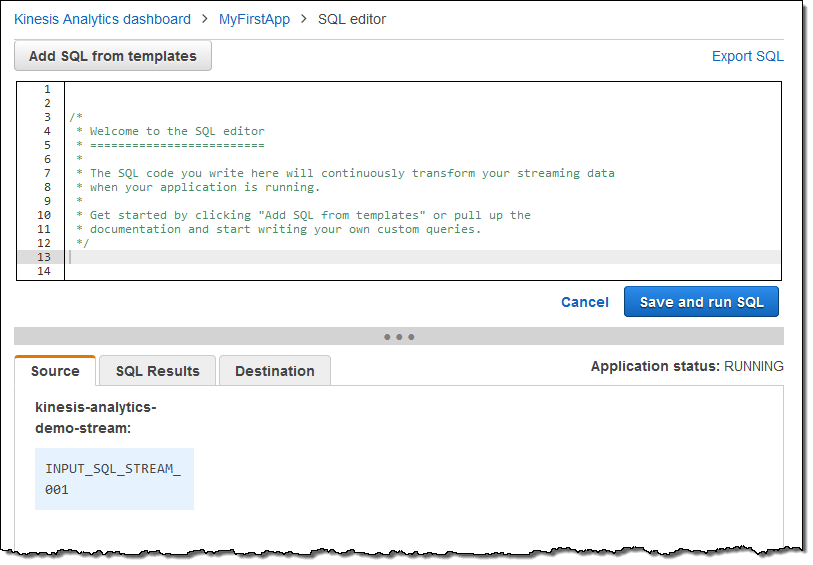
직접 SQL 질의를 만들 수도 있고, 템플릿을 이용할 수도 있습니다.
Continuous filter를 선택하면, SQL문이 보입니다.
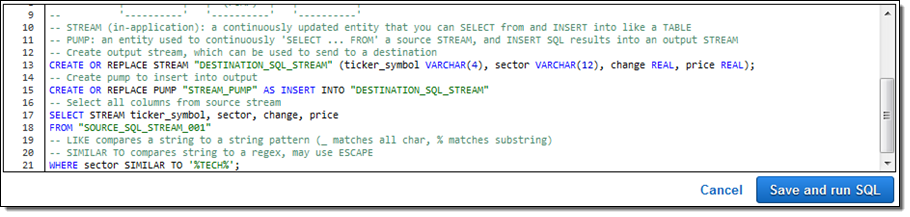
데이터 질의 결과를 검사를 한 후, Save and run SQL를 누릅니다. 몇 초 후에 콘솔에 결과가 보이기 시작합니다.
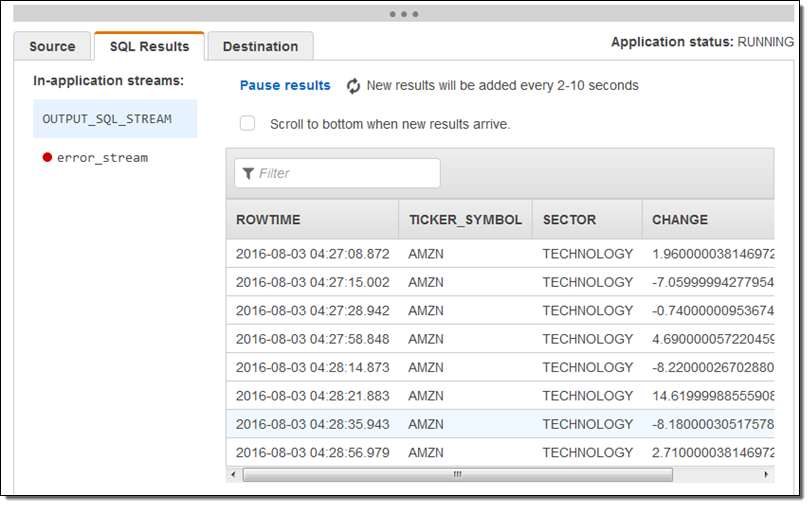
SQL 에디터를 사용해서 sector 및 price 컬럼의 데이터를 지우기 위해 질의문을 수정하고 다시 실행하였습니다.
여기 변경된 결과를 보실 수 있습니다.
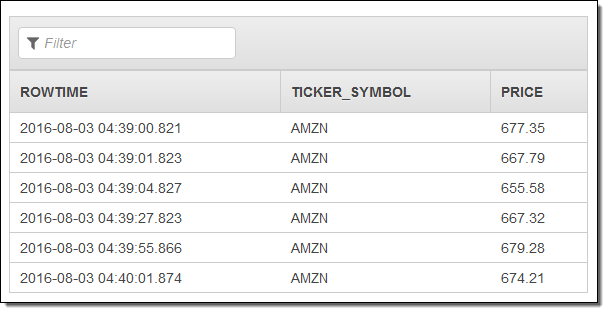
대부분의 경우, 다음 단계로 결과를 신규 혹인 기존 스트림에 저장하는 것이며, 콘솔을 통해 할 수 있습니다.
몇 번의 클릭과 타이핑만으로 Amazon Kinesis Analytics을 통해 손쉽게 증권 데이터를 처리하는 정식 서비스 수준의 앱을 만들 수 있었습니다.
더 자세히 알아보기
본 서비스에 대한 더 자세한 사항은 Writing SQL on Streaming Data with Amazon Kinesis Analytics 블로그 글을 참고하시기 바랍니다. 5분안에 따라할 수 있을 만큼 쉽기 때문에 직접 해보시길 추천합니다.
정식 공개
Amazon Kinesis Analytics는 2016년 8월 11일 현재 US East (N. Virginia), US West (Oregon), EU (Ireland) 리전에서 사용 가능합니다.
— Jeff;
이 글은 Amazon Kinesis Analytics – Process Streaming Data in Real Time with SQL의 한국어 요약본으로 AWS Summit 뉴욕 행사에서 신규 발표한 소식입니다.
Amazon Kinesis 업데이트 – Amazon Elasticsearch Service 통합, 샤드 통계 및 시간 기반 반복 기능
Amazon Kinesis는 대용량 스트리밍 데이터를 클라우드에서 손쉽게 처리할 수 있도록 도와 줍니다.
Amazon Kinesis 플랫폼은 3개의 서비스로 구성되어 있습니다: Kinesis Streams은 개발자가 자신의 스트리밍 데이터 처리 애플리케이션을 구현할 수 있습니다; Kinesis Firehose를 통해 스트리밍 데이터를 저장하고 분석하기 위해 AWS에 저장하는 기능에 초점을 맞추었습니다; Kinesis Analytics 를 통해 스트리밍 데이터를 표준 SQL을 통해 분석 할 수 있습니다.
많은 AWS 고객이 스트리밍 데이터를 실시간으로 수집 · 처리하는 방식으로 Kinesis Streams와 Kinesis Firehose을 이용하고 있습니다. 이는 완전 관리 서비스이기 때문에 사용 편의성을 높아 스트리밍 데이터 처리를 위한 인프라를 직접 관리하는 대신 응용 프로그램에 개발하는 시간에 투자를 할 수 있다는 장점이 있습니다.
오늘 Amazon Kinesis Streams와 Kinesis Firehose 관한 3개의 새로운 기능을 신규 발표합니다.
- Elasticsearch 통합– Amazon Kinesis Firehose는 Amazon Elasticsearch Service에 스트리밍 데이터를 전달할 수 있습니다..
- 강화된 모니터링 수치 제공– Amazon Kinesis는 샤드 단위 메트릭을 CloudWatch로 매 분당 보낼 수 있습니다.
- 유연성 확보– Amazon Kinesis에서 시간 기반의 반복자를 이용하여 레코드를 수신 할 수 있습니다.
Amazon Elasticsearch Service 통합
Elasticsearch
는 인기있는 오픈 소스 검색 · 분석 엔진입니다. Amazon Elasticsearch Service는 AWS 클라우드에서 Elasticsearch를 손 쉽게 설치하고, 높은 확장성을 가지고 운영할 수 있는 관리 서비스입니다. 오늘 부터 Kinesis Firehose 데이터 스트림을 Amazon Elasticsearch Service 클러스터에 배포 할 수 있게되었습니다. 이 새로운 기능은 서버의 로그 및 클릭 스트림, 소셜 미디어 트래픽 등으로 인덱스를 생성하고 분석 할 수 있습니다.
전송 받은 레코드 (Elasticsearch 문서)는 지정한 설정에 따라 Kinesis Firehose에서 버퍼링 된 후,여러 문서를 동시에 인덱스를 만들 수 있도록 벌크 요청을 사용하여 자동으로 클러스터를 추가합니다. 또한, 데이터는 Firehose로 전송하기 전에 UTF-8로 인코딩 된 단일 JSON 개체에 두어야 합니다. (관련 정보는 Amazon Kinesis Agent Update – New Data Preprocessing Feature를 참조하십시오).
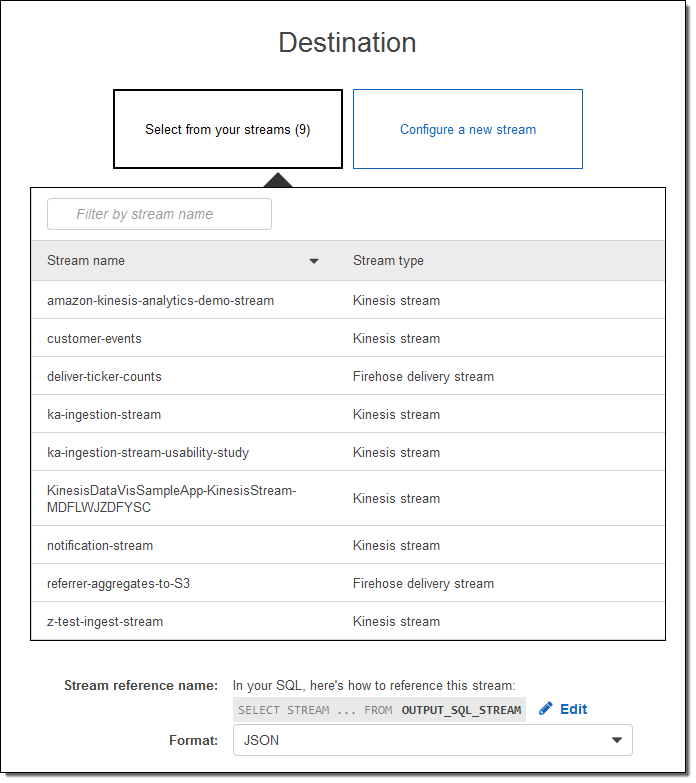
이제 AWS 관리 콘솔을 통한 설정 방법을 알아보겠습니다. 대상(Amazon Elasticsearch Service)를 선택하고 전송 스트림의 이름을 입력합니다. Elasticsearch 도메인 (livedata 예제)을 선택 인덱스로 지정하고, 인덱스 주기(없음, 시간별, 매일, 매주, 매월)를 선택합니다. 또한, 모든 문서 또는 실패한 문서의 백업을받을 S3 버킷을 지정합니다 :
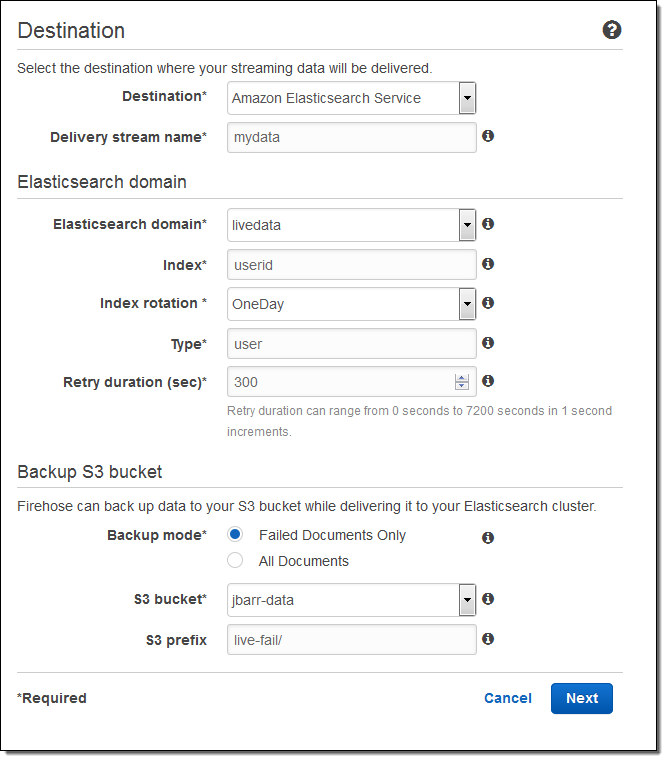
그리고 버퍼의 크기를 지정하고 S3 버킷에 전송되는 데이터의 압축 및 암호화 옵션을 선택합니다. 필요에 따라 로깅을 사용하고 IAM 역할을 선택합니다 :
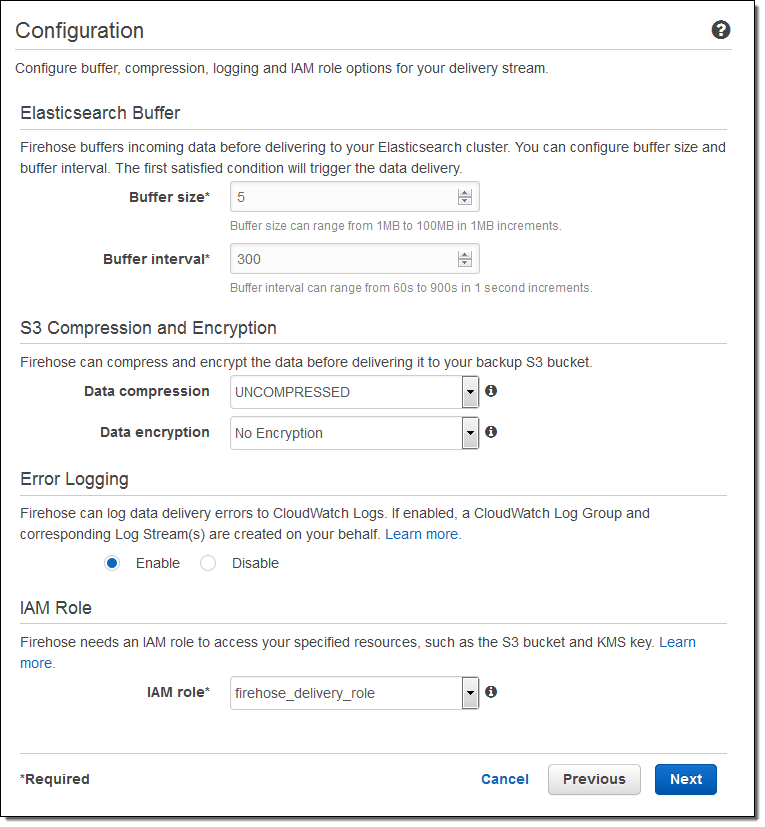
1분 정도 이후에 스트림이 준비 됩니다 :
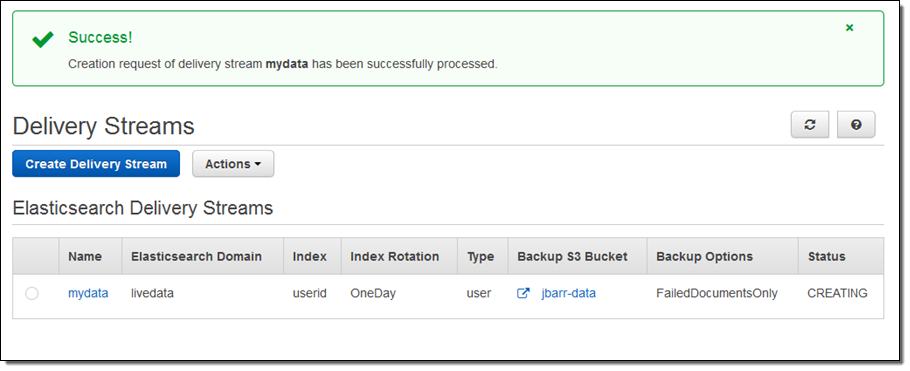
I can view the delivery metrics in the Console:
스트리밍 데이터가 Elasticsearch에 도달 한 후에는 Kibana와 Elasticsearch 쿼리 언어에 의해 데이터 시각화를 할 수 있습니다.
즉, 통합을 통해 여러분의 스트리밍 데이터를 수집하고 Elasticsearch에 전달 하기 위한 처리 방법은 매우 간단합니다. 더 이상 코드를 작성하거나 자체 데이터 수집 도구를 만들 필요가 없습니다.
샤드 기반 통계 모니터링
모든 Kinesis 스트림은 하나 이상의 샤드로 구성되어 있으며, 모든 샤드는 일정량의 읽기 · 쓰기의 용량을 가지고 있습니다. 필요에 따라 스트림에 샤드를 추가하면 스트림의 용량은 증가합니다.
여러분은 각 샤드의 성능을 파악하기위한 목적으로 샤드 단위의 통계 기능을 활성화 할 수 있게되었습니다. 샤드 당 6개의 메트릭이 있습니다. 각 통계는 1 분에 한 번 보고되고, 일반 통계 단위의 CloudWatch 요금이 부과됩니다. 이러한 신규 기능은 특정 샤드에 부하가 편중되지 않았는지, 다른 샤드와 비교하여 확인하거나 스트리밍 데이터의 전송 파이프 라인을 통해 비효율적 인 부분을 발견 및 변경할 수 있게 됩니다.
아래에는 새로이 측정되는 수치입니다.
IncomingBytes – 샤드로 PUT이 성공한 바이트 수.
IncomingRecords – 샤드로 PUT이 성공한 레코드.
IteratorAgeMilliseconds –샤드에 대한 GetRecords 호출이 취소 된 마지막 레코드의 체류 시간 (밀리 초). 값이 0 인 경우, 읽은 레코드가 완전히 스트림에 붙어 있다는 것을 의미합니다.
OutgoingBytes – 샤드에서받은 바이트 수.
OutgoingRecords – 샤드에서받은 레코드 수.
ReadProvisionedThroughputExceeded – 매초 5 회 또는 2MB를 초과한 GetRecords 호출 수.
WriteProvisionedThroughputExceeded – 매 초 1000 기록 또는 1MB를 초과한 레코드의 수.
EnableEnhancedMetrics 를 호출하는 것으로 활성화 할 수 있습니다. 평소처럼, 일정 기간 동안 집계를 위해 CloudWatch API를 사용할 수 있습니다.
시간 기반 반복 기능
어떤 샤드에 GetShardIterator를 호출 시작점으로 지정하고, 반복 기능을 작성하여 애플리케이션에서 Kinesis 스트림 데이터를 읽을 수 있습니다. 기존의 시작점 선택 (시퀀스 번호 시퀀스 번호 뒤에 가장 오래된 기록, 가장 새로운 레코드)에 추가로 타임 스탬프를 지정할 수 있게되었습니다. 지정한 값 (UNIX 시간 형식)은 읽고 처리하려고하는 가장 오래된 레코드의 타임 스탬프를 나타냅니다.
— Jeff;
이 글은 Amazon Kinesis Update – Amazon Elasticsearch Service Integration, Shard-Level Metrics, Time-Based Iterators의 한국어 번역입니다.
Amazon Kinesis Firehose – 확장성 높은 데이터 처리 서비스
2년 전 Amazon Kinesis을 소개하였고 이제 Amazon Kinesis Streams이라 부르며 고대역폭의 스트리밍 데이터를 수집, 처리 및 분석할 수 있는 애플리케이션을 만들 수 있습니다. 더 이상 데이터 수집 서버를 만들 필요가 없고 모니터링 및 확장성 및 신뢰성 있는 배포를 걱정할 필요가 없습니다.
Amazon Kinesis Firehose는 AWS에서 스트리밍 데이터를 좀 더 쉽게 처리하기 위해 만들어졌습니다. 간단히 Amazon Simple Storage Service (S3) 버킷으로 옮기거나 Amazon Redshift 테이블로 (1000 KB까지) 스트림 데이터를 기록할 수 있습니다. Firehose는 모니터링, 확장성 및 데이터 관리를 도와 주게 됩니다.
이를 통해 인프라가 아닌 여러분의 애플리케이션에 더 집중할 수 있는 시간을 얻을 수 있습니다.
Firehose 내부 보기
이를 간단하게 하기 위해 Firehose는 자료(raw data)를 따로 해석하거나 처리하지 않습니다. 간단히 데이터를 전달하고 기록하는 일만 합니다. 압축(client-side) 및 암호화(server-side)후에 데이터를 원하는 S3 버킷에 기록하게 됩니다. AWS의 James Hamilton는 다른 말로 “그냥 간단하다!”라고 표현합니다. 버퍼 사이즈 및 버퍼 간격 등을 제어할 수 있습니다.
만약 Firehose로 데이터를 보내기 전에 클라이언트 코드를 통해 개별 논리적 기록을 처리하려면 구분자를 추가할 수 있습니다. 일단 클라우드에 데이터가 있으면, 나중에 저장된 내역을 확인할 수 있습니다.
만약 여러분 데이터가 S3에 저장되어 있으면 여러분은 분석이나 처리하는데 여러 가지 옵션이 있습니다. 예를 들어 AWS Lambda 함수를 통해 버킷에 데이터가 저장되거나 객체로 올때 처리 가능합니다. 또는 Amazon EMR 작업을 통해 버킷의 데이터를 처리할 수 있습니다.
이제 Firehose를 통해 데이터를 Amazon Redshift 클러스터로 보낼 수도 있습니다. Firehose를 통해 S3 객체로 저장이 된 후에 Redshift COPY 명령어를 실행할 수 있습니다. 이 명령어를 통하면 보다 유연하게 다양한 형식으로 데이터를 가져올 수 있습니다.(예: CVS, JSON, AVRO 등) 또한, 특정 선택 컬럼을 따로 저장하거나 다른 형태로 변환하는 것도 가능합니다.
Firehose 관리 콘솔 사용하기
이제 AWS 관리 콘솔, the AWS Command Line Interface (CLI) 및 Firehose API를 사용할 수 있습니다.
Firehose 콘솔에서 스트리밍 전달을 한번 설정해 보겠습니다. 먼저 Create Delivery Stream를 선택합니다. 이름을 정하고 S3 버킷을 선택 (혹은 추가)한 후 버킷에 쓰기가 가능하도록 IAM 역할을 정하면 됩니다.
스트림 전달시 압축이나 지연을 설정할 수 있습니다. 또한 AWS Key Management Service (KMS) 키를 통해 암호화도 가능합니다.
스트림이 만들어졌으면 이제 콘솔에서 볼 수 있습니다.
스트림 게시하기
아래는 특정 데이터를 스트림으로 게시하는 자바 코드입니다.
PutRecordRequest putRecordRequest = new PutRecordRequest();
putRecordRequest.setFirehoseName("incoming-stream");
String data = "some data" + "\n"; // add \n as a record separator
Record record = new Record();
record.setData(ByteBuffer.wrap(data.getBytes(StandardCharsets.UTF_8)));
putRecordRequest.setRecord(record);
firehoseClient.putRecord(putRecordRequest);CLI를 통해서도 가능합니다.
$ aws firehose put-record --firehose-name incoming-stream --record Data="some data\n"리눅스에서 구동하는 에이전트 프로그램도 배포하게 됩니다. 이를 통해 로그 파일을 쉽게 Firehose로 전달할 수 있습니다.
Kinesis Firehose 스트림 모니터링
CloudWatch를 통해 콘솔에서 스트림 데이터를 모니터링 할 수 있습니다.
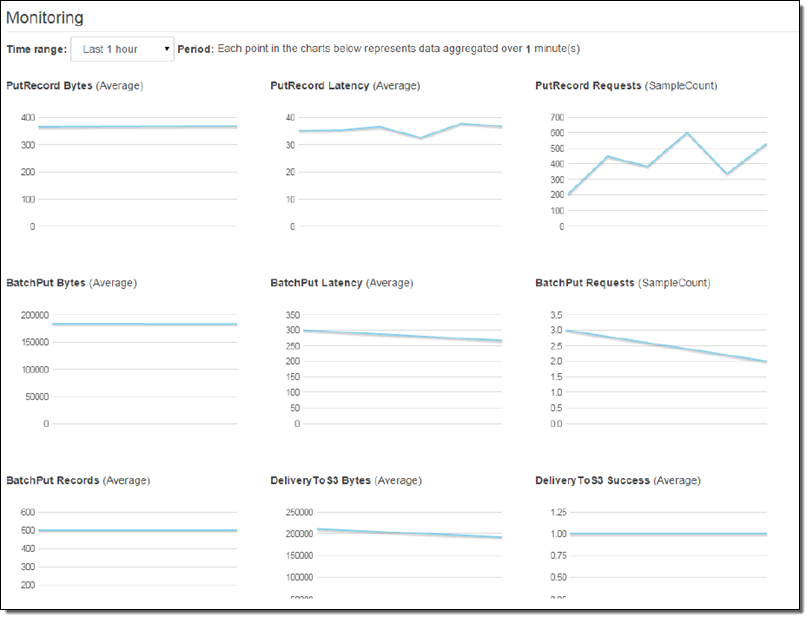
By the Numbers
개별적인 데이터 스트림은 시간당 수 기가 바이트의 다중 데이터를 처리할 수 있습니다. 기본값으로 각 스트림을 초당 2500 호출을 보낼 수 있으며, AWS 계정당 5개까지 스트림을 PutRecord 또는 PutRecordBatch로 보낼 수 있습니다.
이들 기능은 오늘 부터 사용 가능하며, 가격은 데이터 수집 수량에 따라 정해집니다.
— Jeff;
이 글은 Amazon Kinesis Firehose – Simple & Highly Scalable Data Ingestion의 한국어 번역이며, re:Invent 2015의 신규 서비스 소식입니다.
CloudWatch Logs Subscription Consumer + Elasticsearch + Kibana를 통한 데이터 시각화
최근 여러개의 AWS 서비스를 결합하여 만드는 흥미로운 사례를 자주 소개하고 있습니다. 이 글도 그 중에 하나로 오늘은 모니터링을 위한 서비스 조합을 소개해 드리고자 합니다. 먼저 사용하는 서비스에 대해 간단하게 소개하겠습니다. (아직 AWS에 익숙하지 않는 분들을 위해서입니다.)
- Amazon Kinesis는 실시간 데이터 스트림을 처리하기 위한 관리형 서비스입니다. 자세한 사항은 Amazon Kinesis – Real-Time Processing of Streaming Big Data를 참고하세요.
- Kinesis Connector Library를 사용하면 다른 AWS 서비스 또는 AWS 이외의 서비스에서 Kinesis에 연결하는 데 도움이 됩니다.
- AWS CloudFormation 템플릿을 사용하여 AWS 리소스를 정의하고 관리하는 데 도움이 됩니다.
- CloudWatch Logs를 사용하면 운영 체제, 응용 프로그램 및 사용자 정의 로그 파일을 저장하고 모니터링 할 수 있습니다. 자세한 내용은 Store and Monitor OS & Application Log Files with Amazon CloudWatch를 참고하십시오.
- AWS Lambda는 이벤트 기반 클라우드 함수(현재 Node.js와 Java)를 실행합니다. 컴퓨팅 자원에 신경 쓸 필요가 없고 단순히 프로그래밍 코드 개발에 집중할 수 있습니다. 자세한 내용은 AWS Lambda –클라우드 기반 함수 실행을 참고하십시오. 많은 개발자들은 AWS Lambda을 Amazon API Gateway와 함께 이용하여 확장성이 뛰어난 마이크로 서비스(MicroServices)를 구축 할 수 있습니다.
- VPC Flow Logs를 사용하여 VPC와 VPC 서브넷 또는 Elastic Network Interface 관련 네트워크 트래픽에 접근할 수 있습니다.
- 마지막으로 AWS CloudTrai 계정의 AWS API 호출을 기록하고 로그 파일로 저장합니다. 자세한 사항은 AWS CloudTrail – Capture AWS API Activity을 참고하십시오.
위의 마지막 세가지는 매우 중요한 속성으로 각각 효율적으로 저장된 데이터를 시각화하기 위하여 이벤트 데이터의 방대한 스트림을 만들 수 있습니다.
이벤트 데이터 시각화
오늘은 Kinesis와 CloudWatch Logs Subscription Consumer의 이용 방법에 대해 소개합니다. CloudWatch Logs Subscription Consumers는 특정 Kinesis Stream을 받아줍니다. Elasticsearch와 S3를위한 내장 커넥터가 포함되어 있어 다른 방식의 확장도 가능합니다.
우리는 EC2에 Elasticsearch 클러스터를 구축하고, 이벤트 데이터를 Elasticsearch로 제공되도록 하여 Kibana 및 시각화 도구를 사용하여 대시 보드까지 구축 하는 CloudFormation Template을 만들었습니다. VPC Flow Log, Lambda, CloudTrail을 통한 대시 보드도 설정합니다. 필요에 따라 사용자 정의 혹은 자신의 CloudWatch Logs 로그 그룹에 새 계정을 만들 수도 있습니다.
이 템플릿을 통해 필요한 모든 자원을 만드는 데 약 10 분이 소요됩니다. 완료되고 나면, CloudFormation 콘솔의 Output 탭에 대시 보드 및 관리 도구의 URL이 표시됩니다.
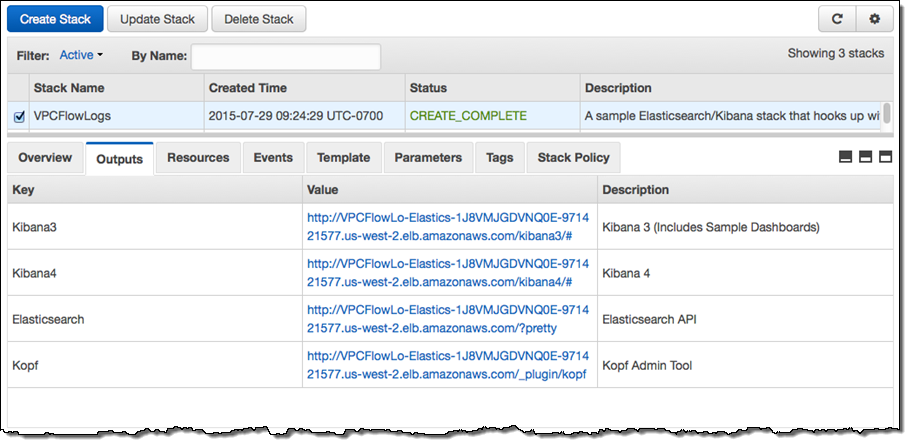
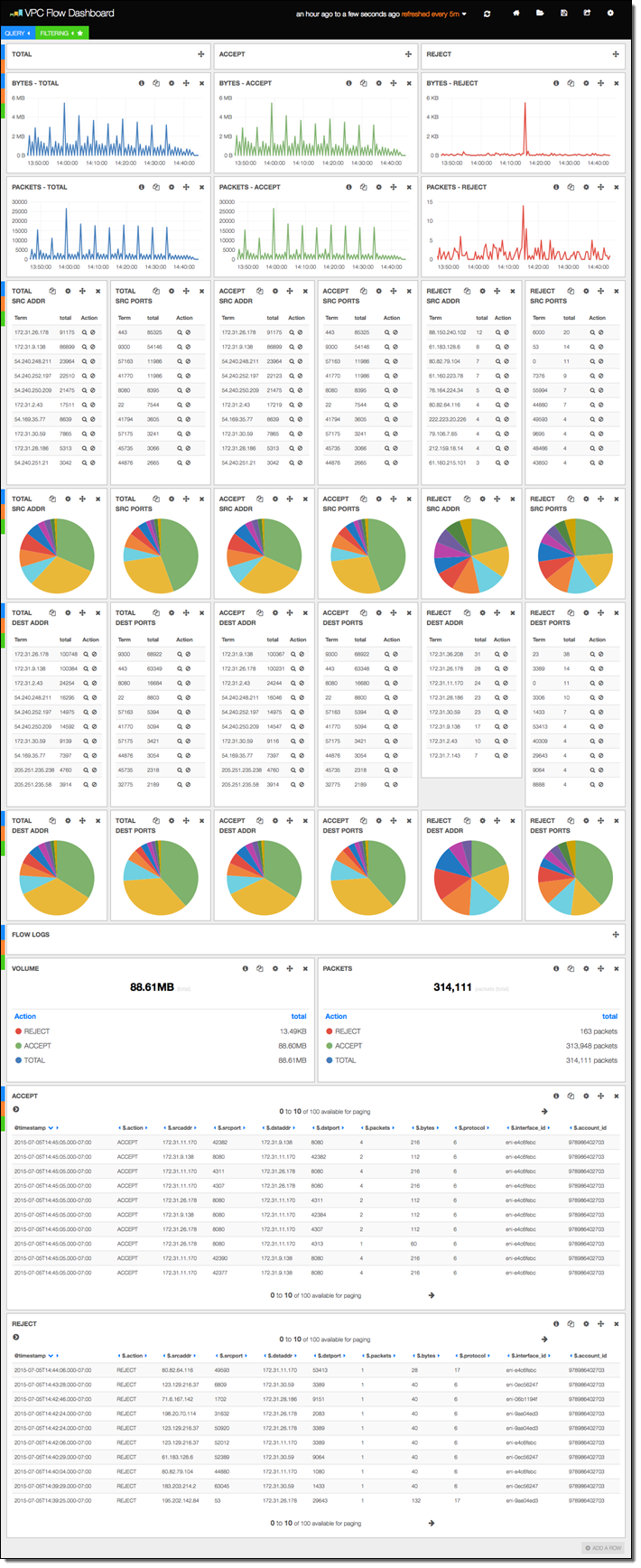
현재 스택은 이전 버전의 샘플 대시 보드와 함께 Kibana 3.0 및 4.0으로 구축됩니다 (Kibana 4.0를 사용하는 경우는 약간 수동 설정을 해야 합니다). 첫 번째 샘플 대시 보드는 VPC Flow Log가 표시됩니다. 보시다시피 상당한 양의 정보가 포함되어 있습니다.
다음 예제는 람다 함수 자체에 의해 생성 된 Lambda Function 실행 정보가 표시되어 있습니다.
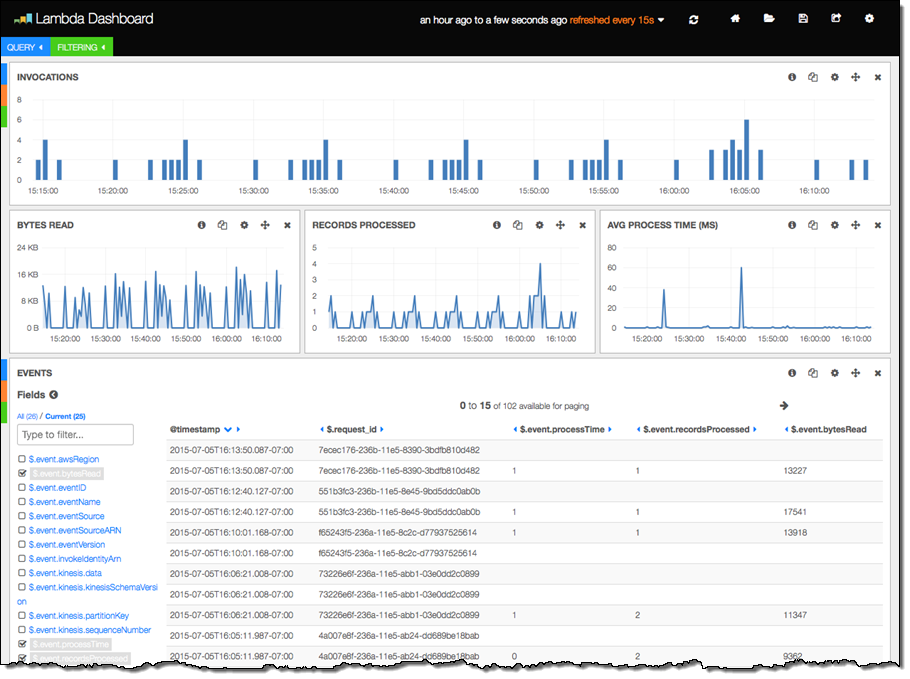
마지막 세 가지 열은 아래의 Lambda Function 코드로 작성되었습니다. Function에서 Kinesis 스트림을 처리 후 각 호출에 대한 정보를 로그에 기록합니다.
exports.handler = function(event, context) {
var start = new Date().getTime();
var bytesRead = 0;
event.Records.forEach(function(record) {
// Kinesis data is base64 encoded so decode here
payload = new Buffer(record.kinesis.data, 'base64').toString('ascii');
bytesRead += payload.length;
// log each record
console.log(JSON.stringify(record, null, 2));
});
// collect statistics on the function's activity and performance
console.log(JSON.stringify({
"recordsProcessed": event.Records.length,
"processTime": new Date().getTime() - start,
"bytesRead": bytesRead,
}, null, 2));
context.succeed("Successfully processed " + event.Records.length + " records.");
};여기에는 약간 재미있는 것이 있습니다. 유효한 JSON 객체임을 판단하고 ElasticSearch 각각 값에 인덱스를 붙입니다. 이것은 매우 편리하고 간단한 방식으로, 디자인 패턴에 대해 연구하는 분은 여러분 시스템에 활용해 보실 수 있습니다. 더 자세한 것은 awslabs Github의 CloudWatch Logs Subscription Consumer를 참고해 보시기 바랍니다.
— Jeff;
이 글은 CloudWatch Logs Subscription Consumer + Elasticsearch + Kibana Dashboards의 한국어 번역글입니다.
AWS Lambda – 클라우드에서 코드 실행
AWS는 클라우드에서 실행되는 응용 프로그램의 실행을 더욱 쉽게 하여 개발자들이 코드에만 집중할 수 있게 될 뿐만 아니라 확장성, 신뢰성 및 런타임 효율이 충분히 높은 클라우드 중심의 개발 환경이 필요하다고 생각해 왔습니다.
 이를 위해 AWS Lambda미리보기를 오늘 출시합니다. AWS Lambda는 클라우드에서 애플리케이션을 실행하는 새로운 플랫폼으로서 기존 프로그래밍 및 AWS 지식을 활용할 수 있습니다. Lambda를 이용하여 간단하게 Lambda function을 만들고 특정 AWS 리소스에 대한 권한을 주고 Lambda function을 AWS 리소스에 연결할 수 있습니다. Lambda는 Amazon Simple Storage Service (S3) 버킷에 업로드된 파일에 대한 변경이나 Amazon Kinesis 스트림에의 특정 데이터 처리, Amazon DynamoDB 테이블 업데이트 같은 이벤트를 통해 여러분이 미리 업로드한 코드를 자동으로 실행합니다.
이를 위해 AWS Lambda미리보기를 오늘 출시합니다. AWS Lambda는 클라우드에서 애플리케이션을 실행하는 새로운 플랫폼으로서 기존 프로그래밍 및 AWS 지식을 활용할 수 있습니다. Lambda를 이용하여 간단하게 Lambda function을 만들고 특정 AWS 리소스에 대한 권한을 주고 Lambda function을 AWS 리소스에 연결할 수 있습니다. Lambda는 Amazon Simple Storage Service (S3) 버킷에 업로드된 파일에 대한 변경이나 Amazon Kinesis 스트림에의 특정 데이터 처리, Amazon DynamoDB 테이블 업데이트 같은 이벤트를 통해 여러분이 미리 업로드한 코드를 자동으로 실행합니다.
Lambda는 전혀 관리가 필요 없는 컴퓨팅 플랫폼입니다. EC2 인스턴스를 만들고 설정할 필요가 없습니다. 운영 체제나 프로그래밍 개발 환경을 설치할 필요도 없습니다. 스케일과 탄력성을 고려할 필요도 없으며, 미리 용량을 요청하거나 확보할 필요도 없습니다. 새로 만들어진 Lambda function은 사용자 측에서 아무 것도 하지 않으면서도 높은 비용 효율에 따라 시간당 수백만 건의 요청을 처리 할 수 있습니다.
좀 더 Lambda를 자세히 살펴 보겠습니다. 프로그래밍 모델 및 런타임 환경을 살펴 보고 나서 프로그래밍 예제를 실행 해 보겠습니다. 이 글을 읽음으로서 Lambda 로드맵에 많은 항목이 있다는 것을 아실 수 있고, 앞으로 계속 이어질 기능 추가를 위한 여행의 작은 첫 걸음입니다.
Lambda의 개념
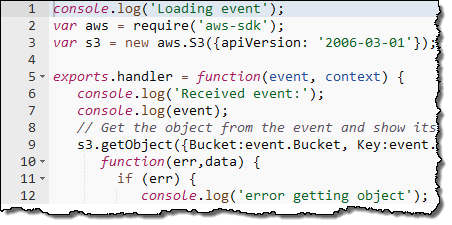 Lambda의 가장 중요한 개념은 Lambda function입니다. Node.js ( JavaScript로 개발된 이벤트 기반 서버 구현)에서 Lambda function을 실행 할 수 있습니다.
Lambda의 가장 중요한 개념은 Lambda function입니다. Node.js ( JavaScript로 개발된 이벤트 기반 서버 구현)에서 Lambda function을 실행 할 수 있습니다.
JS 코드를 업로드하기 위해 Lambda function을 만드는 Amazon Lambda에 대한 컨텍스트 정보를 설정합니다. 컨텍스트 정보는 실행 환경(언어, 필요한 메모리 제한 기간이나 IAM role)을 지정하고 코드에서 수행할 함수를 지정합니다. 코드와 메타 데이터는 AWS에서 영구적으로 저장하고 나중에 이름과 ARN(Amazon Resource Name)에서 볼 수 있습니다. 필요한 타사 라이브러리도 업로드에 포함할 수 있습니다 (Lambda function마다 하나의 ZIP 파일 형식입니다).
업로드 후 자신의 Lambda function과 특정 AWS 리소스 (특정 S3 버킷, DynamoDB 테이블 또는 Kinesis 스트림)을 연결합니다. Lambda는 Lambda function에 이벤트 (일반적으로 자원이 변경된 경우 실행)을 함께 연결하도록 합니다.
자원에 변경이 있는 경우, Lambda는 그 자원에 연결된 Lambda function을 실행합니다. 수신 요청을 처리하기 위해 필요한 컴퓨팅 리소스(EC2 인스턴스)를 시작 및 관리합니다. Lambda가 여러분 대신 자원을 관리 할 수 있으며, 더 이상 필요 없어지면 실행이 종료됩니다.
Lambda는 AWS Management Console, AWS SDK 및 AWS Command Line Interface (CLI)에서 접근할 수 있습니다. Lambda API는 모든 문서화되어 있으며 기존 코드 편집기 및 기타 개발 도구를 Lambda에 연결하는 데 사용할 수 있습니다.
Lambda 프로그래밍 모델
Lambda function 연결된 AWS 서비스의 자원이 변경될 때 활성화됩니다. 즉, 지정된 Node.js의 함수 실행이 시작되고 거기에서 작업 처리가 진행됩니다. 함수는 (POST와 함께 전달 된 매개 변수를 통해) JSON 형식의 데이터 구조에 접근합니다. 이 데이터 구조는 Lambda function이 활성화되는 계기가 되는 변경(또는 기타 이벤트)에 대한 자세한 정보를 포함합니다.
Lambda는 자원 변경 속도에 뒤쳐지지 않도록 필요에 따라 Lambda function의 추가 복사본을 활성화합니다. Lambda function은 컴퓨팅 인스턴스에 영구적인 상태를 저장할 수 없기 때문에, 대신 S3 또는 DynamoDB를 사용해야 합니다.
여러분의 코드는 Node.js 및 Linux 환경에서 내재된 기능을 사용할 수 있습니다. 다른 AWS 서비스를 호출하기 위해 AWS SDK for JavaScript in Node.js 를 이용할 수도 있습니다.
Lambda의 실행 환경
각 Lambda function에 지정된 컨텍스트 정보는 함수의 최대 실행 시간을 지정합니다. 일반적으로 짧게 설정되어 있지만 (몇 초 정도에 대부분 실행 가능) 필요에 따라 최대 60초까지 지정할 수 있습니다.
Lambda는 여러 IAM role을 사용하여 Lambda function에 대한 접근과 AWS 리소스를 관리합니다. Invocation role은 Lambda에서 특정 Lambda function을 수행할 권한을 부여합니다. Execution role은 Lambda function의 특정 AWS 리소스에 대한 접근 권한을 부여합니다. 세분화 되어 있는 권한의 조합을 이루기 위해 각각 기능에 대해 별도의 IAM role을 사용할 수 있습니다.
Lambda는 각 Lambda function의 실행을 감시하고 요청 수, 지연 시간, 가용성 및 오류 비율 통계를 Amazon CloudWatch 에 저장합니다. 30 일 동안 보관되며 콘솔에서도 볼 수 있습니다.
이제 Lambda를 사용하시려고 할 때 고려해야 할 몇 가지 사항을 알려드립니다.
- Lambda function 컨텍스트 정보는 실행에 필요한 메모리 양을 지정합니다. 128MB에서 1GB까지 원하는 값을 지정할 수 있습니다. 메모리 설정에 따라 Lambda function이 사용 가능한 인스턴스의 CPU 능력, 네트워크 대역폭, IO 대역폭이 결정됩니다.
- 각 Lambda function의 시작은 최대 256 프로세스 또는 스레드를 사용할 수 있습니다. 최대 512MB의 로컬 스토리지와 102개 이상의 파일 디스크립터도 사용할 수 있습니다. 또한, 최대 10개의 동시 아웃 바운드 연결을 생성합니다.
- Lambda는 각 AWS 계정에서 일련의 관리 상의 제한을 부과합니다. 미리보기 기간 동안 동시 실행 요청을 25개까지 처리 할 수 있습니다.
Lambda 소개
이제 관리 콘솔을 사용하여 간단한 Lambda function을 만드는 과정을 살펴 보겠습니다. 앞서 말한대로 SDK 및 CLI 에서 실행할 수 있습니다.
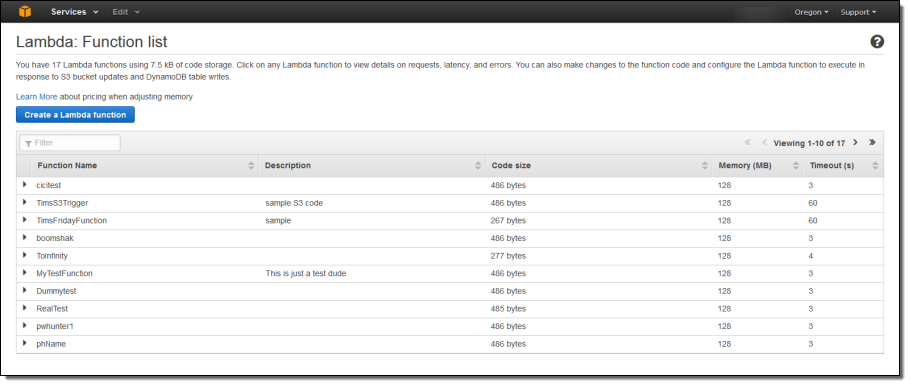
아래 화면은 콘솔에서 내 전체 Lambda function을 표시하고 있습니다.
이제 “Create a Lambda function”을 클릭합니다. 자세한 내용을 모두 입력합니다.
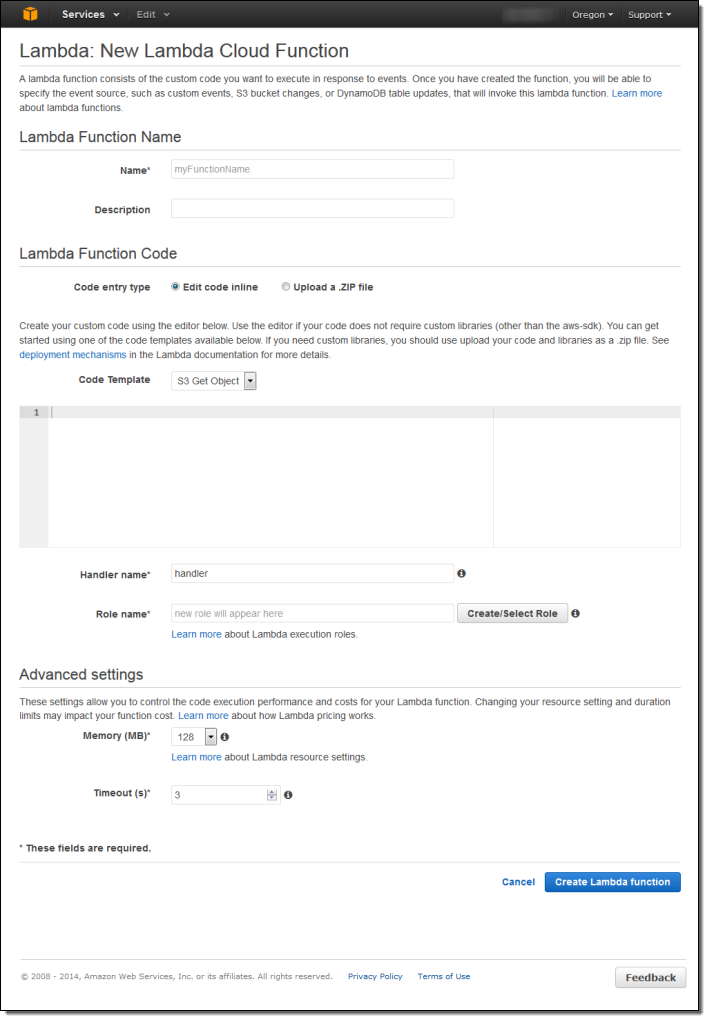
아래와 같이 자신의 Lambda function에 이름을 붙이고 설명 사항을 추가합니다.

JS 코드를 직접 입력하거나 ZIP 파일을 업로드합니다. 콘솔에서 시작할 수 있도록 샘플 코드를 선택할 수 있습니다.
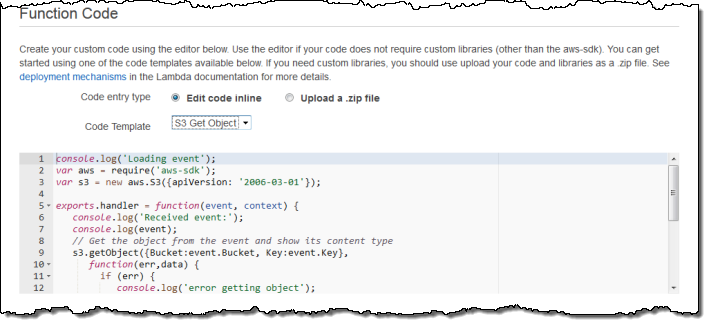
Lambda function을 실행하거나 실행시 어떤 IAM role을 사용할지 여부를 지정합니다.
메모리 요구 사항 조정과 실행 시간 제한도 설정할 수 있습니다.
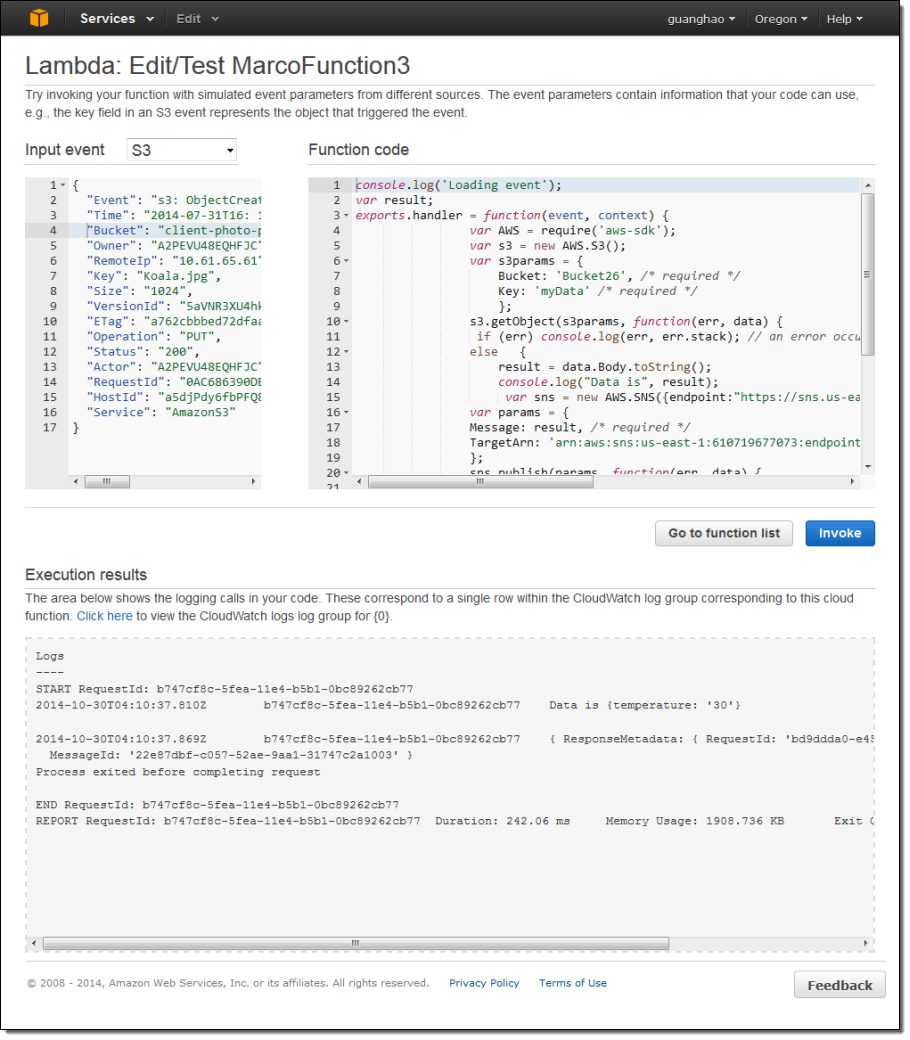
Lambda function을 만든 후 콘솔에서 반복 편집 테스트 할 수 있습니다. 왼쪽 창에는 Lambda function에 전달 된 JSON 데이터 샘플이 표시되어 있습니다.
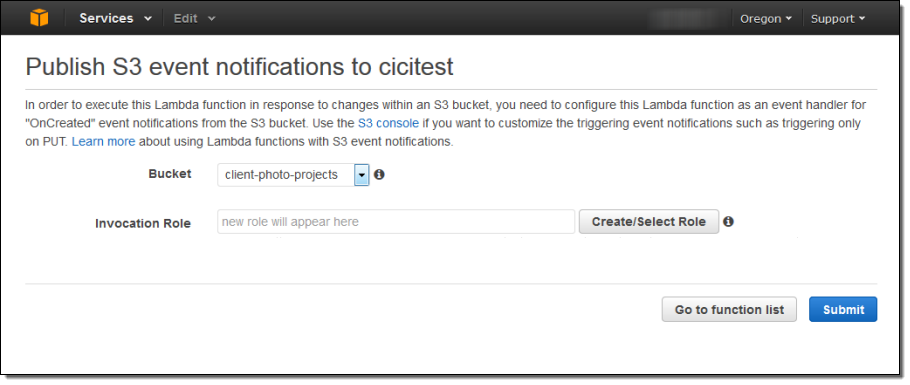
Lambda function이 예상대로 실행 되고 있다면, Amazon S3 event notification 같은 이벤트 소스를 연결할 수 있습니다. Lambda function의 시작을 위해 필요한 권한을 S3에 제공하기 때문에 Invocation role을 지정합니다.
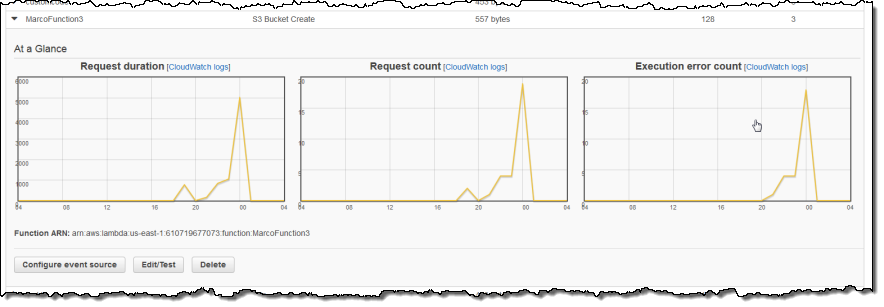
앞에서 이야기한 대로 Lambda는 각 Lambda function마다 통계 정보를 수집하고 이를 Amazon CloudWatch에 보냅니다. 콘솔에서 통계를 볼 수 있습니다.
로드맵
앞으로 Lambda에 대한 로드맵을 가지고 있으며, 오늘 그 모든 것을 말씀 드릴 수는 없지만 새로운 AWS 서비스 이벤트에 추가 지원 및 프로그래밍 언어 지원을 추가 할 예정임을 알려드립니다. 언제나 마찬가지로 우리는 고객의 의견을 매우 소중히 생각하고 있습니다. 꼭 Lambda Forum에 의견을 남겨주세요.
이용 가격 및 가능한 지역
마지막으로 요금에 대해 이야기 해보면, Lambda는 차별화 된 요금 체계로 되어 있습니다. 100밀리 초 단위의 컴퓨팅 시간과 개별 요청에 대해서만 지불이 됩니다. Lambda 무료 이용은 한달 100만 요청과 한달 최대 320만 초 컴퓨팅 처리 시간을 포함합니다. 컴퓨팅 처리 시간은 Lambda function마다 할당된 메모리의 총량에 따라 다릅니다. Lambda는 오늘부터 US East (Northern Virginia), US West (Oregon), 그리고 Europe (Ireland) 지역에 한정 미리보기가 가능합니다.
– Jeff;
이 글은 AWS Lambda – Run Code in the Cloud의 한국어 번역입니다.