AWS Database Blog
A Large-Scale Cross-Regional Migration of NoSQL DB Clusters
Andrey Zaychikov is solutions architect at Amazon Web Services
In this blog post, I will share experiences from a cross-regional migration of large-scale NoSQL database clusters (from Europe to the U.S.). The migration was a joint project implemented by the Ops team of our reference customer, FunCorp, and AWS Solutions Architects.
“Our flagship product, iFunny, is one of the most popular entertaining apps for American youth,” said Roman Skvazh, CTO of FunCorp. “For the last five years, the service has gained a considerable audience. Our mobile apps are utilized by more than 3.5 million active users per day and are operated in all time zones. A back end of the app is implemented on Amazon Web Services and its scope is impressive.”
What Should We Migrate?
The iFunny product uses the following database services running on AWS:
• Apache Cassandra cluster – 25 nodes, 18 TB of data
• Apache Cassandra cluster – 18 nodes, 16 TB of data
• MongoDB cluster – 5 TB of data, distributed across 8 shards, each shard – replica set includes the master and two slaves
• MongoDB cluster– 150 GB of data, distributed across 4 shards, each shard – replica set includes the master and two slaves
• Elasticsearch cluster – search index of 1 TB
• Redis – one master and two slaves, with 15 GB, 10 GB, and 1 GB of data and very high write speeds
“Through the efforts of our DevOps and Back End teams, and together with AWS SA, we were to move all of our infrastructure from one AWS region to another with no downtime and no major changes in the application.”
Why Should We Migrate?
If you’ve ever asked yourself the question, “Why migrate everything?” consider FunCorp’s reason: In the beginning, FunCorp selected an AWS region based on the Russian market, but the iFunny app quickly gained enormous popularity in the United States. Up to a certain point, it was convenient to have a backend located on a different continent. However, the high networking latency began to affect the user experience. For this reason, a migration became one of the integral parts of FunCorp’s global UX improvement program.
FunCorp had some constraints and conditions:
- Zero downtime
- No changes in the application and database structure
- Minimal use of third-party tools
How Should We Migrate?
At first, we planned to implement the migration project using own capabilities for geo-distributed replication for each mentioned database (Cassandra, MongoDB, Amazon ElasticSearch Service, and Redis), but we faced several significant problems unique to each database.
MongoDB
The first issue had to do with mongos for MongoDB Shard, a routing service for shard configurations. The replication between the European cluster and the USA cluster ran smoothly and was implemented by using the standard features of MongoDB, but after switching the users to a new back-end MongoDB, the performance of mongos in the U.S. decreased considerably. The problem was that a geo-distributed cluster of MongoDB supported only one set of configuration servers, which were located in Europe at the time. The following diagram illustrates the initial setup.
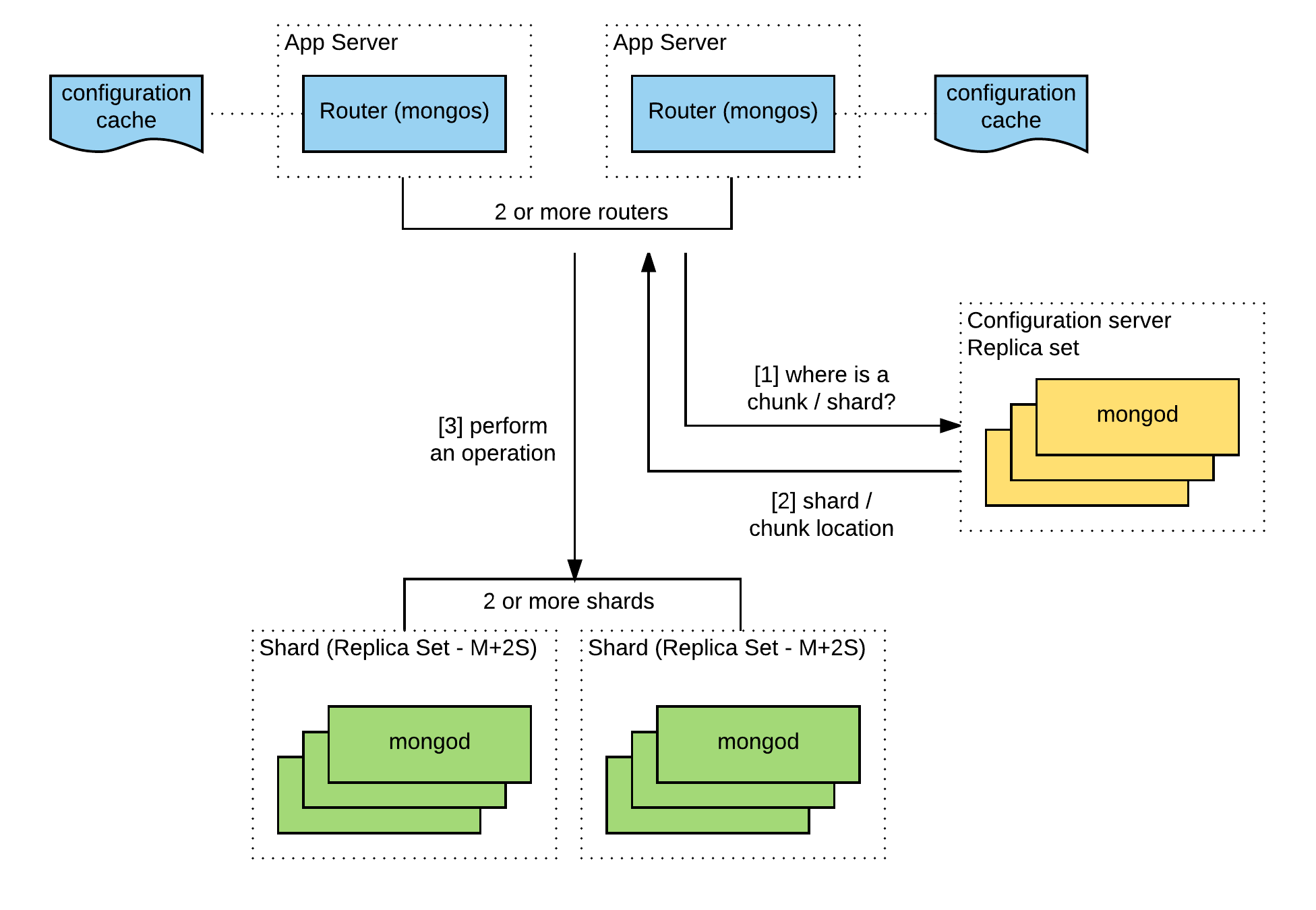
Mongos had to call the configuration servers, which were located overseas, for virtually every operation. The good news is that mongos keeps its configuration cached. However, it’s not possible to increase the number of chunks or to reorganize the data between them by relying only on caches and without connecting to the configuration servers. Therefore, the server migration should have been done quickly.
The final migration algorithm looked like this:
- We created some instances in the target region beforehand, with a configuration identical to the current one, and then we incorporated them into the existing replica set of the initial clusters. Then we waited until the end of the data replication.
- Just before the start of the migration process, we switched off mongos balancing. Thus, the mongos processes in the target region used a cached version of the configuration.
- During the migration, we moved away all of the instances with the data in the source region, one by one.
- In the replica set, there were only instances in the target region left, and new primary servers were elected from among these.
- Finally, we migrated the replica set configuration to the new region.
Cassandra
To migrate the Cassandra clusters, we created an additional Cassandra data center in a Cassandra geo-distributed cluster with a standard EC2Snitch in the target region and connected them to existing clusters through a software VPN tunnel. After that, we started the nodes and began the replication process. The VPN tunnel was essential, because it allowed us to enable interactions between geo-distributed clusters without having to change the snitch from EC2Snitch to EC2MultiRegionalSnitch. In our case, that meant not only a change of the snitch itself, but also manual cluster scaling, support for address lists in security groups, interaction between nodes on a public IP, and many other things. We thought most of the problems were solved.
Unfortunately, just after we started the replication process, the performance of the original Cassandra cluster dropped significantly.

The problem was that Cassandra started replicating data to the new DC simultaneously, from all of the nodes in the source region to all of the nodes in the destination region, with respect to our replication factor and level of consistency. To solve the problem of performance degradation, we stopped the clusters’ replication processes and started rebuilding the nodes of the target cluster, piece by piece, two to three nodes at a time.
By taking this approach, we replicated both clusters without interrupting the work process and with almost no significant performance degradation.
After the replication process was complete, we were able to repair all of the nodes in the target cluster. After that, we switched the applications from the source DC to the new DC. Finally, we excluded the source DC from the cluster, and then terminated that DC.
Redis
We took a similar approach for the Redis migration. We created some new clusters, connected them to the existing one in the source region, and then started replication. The volume of data to be migrated was not a factor, but the data was changing at a very high speed. As a result, the data failed to be replicated within the time defined by the cluster replication window, and all of the data in the target cluster was invalidated.
After several weeks of research, we found a very simple solution to this problem with Redis replication. We created an SSH tunnel with compression and with ports forwarded to localhost:
ssh -C -L 6280:localhost:6379 $MASTER_REDIS
Next, we told the slaves to synchronize with localhost instead of the master:
redis-cli slaveof localhost:6280
Done! Now the Redis replication was running successfully. Because of compression, the replication lag did not increase and never approached a critical threshold in the replication window.
ElasticSearch
Our initial plan was to avoid the migration of the ElasticSearch search index and to instead re-create it in the destination region. Unfortunately, the procedure of index creation was too complicated. It required engagement from our development teams, which was outside the constraints and conditions of the project.
Fortunately, we found a perfect ElasticSearch plugin that allowed us to do backups, including incremental backups. You can find a version of the plugin here. (To find the right version, see the README.md.)
The use of the plugin greatly simplified the migration by:
- Creating an ElasticSearch cluster in a destination region.
- Creating an Amazon S3 bucket, with versioning and cross-region replication enabled.
- Creating a snapshot of the main data set and writing it to S3. The snapshot was transferred to the new region automatically.
- Restoring data from the snapshot in the target region.
- Repeating the preceding steps for the incremental backups. (In our case, the process of applying the incremental backups took 12 minutes.)
The results of the project
The project was successfully implemented and the back-end migration reduced latency by at least 40% for end-users when accessing the iFunny mobile back-end API.
However, it took us more than two months of experimenting and a month and a half for an actual migration.
Conclusion
Any database migration is a complex process. Ambiguous situations, such as the non-standard behavior of a database engines or a process that places a significant impact on the network, can always occur.
The best and safest way to migrate, free of data loss or similar surprises, is to test with real data and real configurations – and only afterward, to proceed with transferring the production database to a new location. Even if your application is not cloud-native, the use of cloud services allows you to experiment and to reproduce the existing use case in a geographically distributed environment, at real scale of clusters and data.