AWS Partner Network (APN) Blog
Managing Machine Learning Workloads Using Kubeflow on AWS with D2iQ Kaptain
Editor’s Note: Since this blog post was written, much about Kubeflow has changed. While we are leaving the post up for historical reference, you can find more accurate information about Kubeflow on the AWS Machine Learning Blog.
By Kiran Anna, Sr. Product Manager – D2iQ
By Young Jeong, Partner Solutions Architect – AWS
 |
| D2iQ |
 |
While the global spend on artificial intelligence (AI) and machine learning (ML) was $50 billion in 2020 and is expected to increase to $110 billion by 2024 per an IDC report, AI/ML success has been hard to come by—and often slow to arrive when it does.
- 87% of AI/ML initiatives never make it to production (VentureBeat, July 2019).
- 55% of organizations have not deployed a single ML model to production (Algorithmia, December 2019).
- 50% of “successful” initiatives take up to 90 days to deploy, with 10% taking longer than that (Algorithmia, December 2019).
- In many enterprises, even just provisioning the software required can take weeks or months, further increasing delays.
There are four main impediments to successful adoption of AI/ML in the cloud-native enterprise:
- Novelty: Cloud-native ML technologies have only been developed in the last five years.
- Complexity: There are lots of cloud-native and ML/AI tools on the market.
- Integration: Only a small percentage of production ML systems are model code; the rest is glue code needed to make the overall process repeatable, reliable, and resilient.
- Security: Data privacy and security are often afterthoughts during the process of model creation but are critical in production.
Kubernetes would seem to be an ideal way to address some of the obstacles to getting AI/ML workloads into production. It is inherently scalable, which suits the varying capacity requirements of training, tuning, and deploying models.
Kubernetes is also hardware agnostic and can work across a wide range of infrastructure platforms, and Kubeflow—the self-described ML toolkit for Kubernetes—provides a Kubernetes-native platform for developing and deploying ML systems.
Unfortunately, Kubernetes can introduce complexities as well, particularly for data scientists and data engineers who may not have the bandwidth or desire to learn how to manage it. Kubeflow has its own challenges, too, including difficulties with installation and with integrating its loosely-coupled components, as well as poor documentation.
In this post, we’ll discuss how D2iQ Kaptain on Amazon Web Services (AWS) directly addresses the challenges of moving machine learning workloads into production, the steep learning curve for Kubernetes, and the particular difficulties Kubeflow can introduce.
Introducing D2iQ Kaptain
D2iQ is an AWS Containers Competency Partner, and D2iQ Kaptain enables organizations to develop and deploy machine learning workloads at scale. It satisfies the organization’s security and compliance requirements, thus minimizing operational friction and meeting the needs of all teams involved in a successful ML project.
Kaptain is an end-to-end ML platform built for security, scale, and speed. With some of its core functionalities leveraged from Kubeflow, Kaptain supports multi-tenancy with fine-grained role-based access control (RBAC), as well as authentication, authorization, and end-to-end encryption with Dex and Istio.
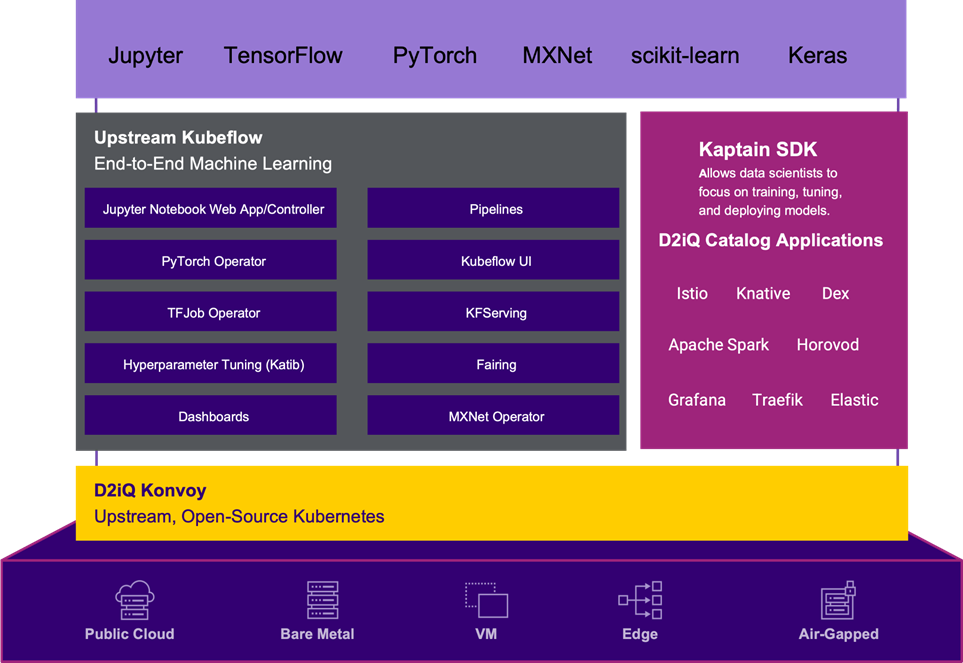
Figure 1 – Kaptain architecture.
Kaptain has many components that are geared towards development of ML models. The platform provides a Python-native user experience, although Spark support is available through Scala with Apache Toree.
The Jupyter Notebooks that many data scientists use for ML projects are pre-installed with the following:
- Libraries: Seaborn, statsmodels, SciPy, Keras, scikit-learn, PySpark (for ETL and ML), gensim, NLTK, and spaCy.
- ML workflow tools: Spark and Horovod for distributed training and building data pipelines, parameter tuning, deployment of models with auto scaling.
- Frameworks: Fully tested, pre-configured images for TensorFlow, PyTorch, and MXNet, with CPU or GPU support.
Challenges of ML Adoption in the Cloud-Native Enterprise
While setting up a Jupyter notebook on a single laptop is easy, it becomes tricky with custom libraries, drivers while provisioning hardware, or with demands for portability, security profiles, service accounts, credentials, and so on. In short, notebooks are not that simple to manage in an enterprise environment.
On top of providing a familiar notebook environment, Kaptain provides easy steps to create a full ML workload lifecycle. The Kaptain SDK enables data scientists to perform distributed training on a cluster’s resources, conduct experiments with parallel trials for hyperparameter tuning, and deploy the models as auto-scaling web services with load balancers, canary deployments, and monitoring.
The software development kit abstracts away the production tasks and allows data scientists to focus solely on model production.
Take, as an example, a data scientist who wants to tune the hyperparameters of a model by running four experiments in parallel, with each experiment running on two machines.
The steps to approach this on Kubernetes without the Kaptain SDK are:
- Write the model code inside a notebook, or the preferred development environment.
- Build a Docker image of the model and its dependencies outside of a notebook, locally or through CI/CD (necessitating a context switch).
- Define the manifest for Katib for model tuning, which consists of both a Katib-specific specification but also one for the job itself, based on the framework used (another context switch).
- Deploy the experiment from the command line with the Kubernetes cluster properly set up on the local machine (another context switch).
- Monitor the logs to see when the experiment is done.
- Extract the best trial’s model from the logs.
- Push that model to the registry.
With the Kaptain SDK, the process is far simpler and more data scientist friendly. The Kaptain SDK allows data scientists to do all of these steps from Python without having to do more than Step 1 above.
Here is how simple that process looks as Python code:
The open-source edition of Kubeflow has well over 50 components, integrations, and related initiatives, which can make life as a data scientist confusing. How do you choose from a set of tools you’re not that familiar with?
D2iQ ensures the best cloud-native tools are included in Kaptain, and only those that provide unique functionality that makes sense for enterprise data science use cases.
Through research and review, evaluation is done on a set of core criteria, including:
- Capabilities vs. requirements
- Codebase health
- Community activity and support
- Corporate or institutional backing
- Project maturity
- Roadmap and vision
- Overall popularity and adoption within the industry
D2iQ regularly runs tests with mixed workloads on large clusters to simulate realistic enterprise environments. This ensures the entire stack is guaranteed to work and scale. Each release of Kaptain is also “soaked,” or run with a heavy load for a certain duration, to validate the performance and stability of the system. Kaptain can be updated with zero downtime.
Do-it-yourself (DIY) machine learning platforms, with so many moving parts, can easily expose your business to unnecessary security risks. In June 2020, ZDNet reported a widespread attack against DIY Kubeflow clusters that failed to implement proper security protocols. Kaptain is protected from such vulnerabilities by design, and is deployed exclusively behind strict authentication and authorization mechanisms.
All of these factors combine to reduce the complexity and friction associated with running ML workloads on AWS. By simplifying the process of getting ML workloads into production, Kaptain enables organizations to make greater use of this game-changing technology.
Customer Success Story
One of D2iQ’s customers is a government scientific research organization that addresses a broad range of technical and policy questions. Many of the organization’s data scientists work on AWS, but much of the enormous volumes of data generated by the organization are on edge locations.
The costs of moving this data from the edge to the center of the network, or from one region to another, were quickly becoming prohibitive. Data scientists were frustrated by the long lag time between requesting IT resources and actually receiving them.
Data scientists also had to manage their own tech stack, resulting in a lack of repeatable standards. From the IT team’s perspective, lack of governance for deployed workloads led to concerns around security and inefficient use of resources.
The organization quickly adopted D2iQ Kaptain upon its introduction. Kaptain runs as a workload on the D2iQ Konvoy Kubernetes distribution, which was deployed on AWS and the customer’s data centers.
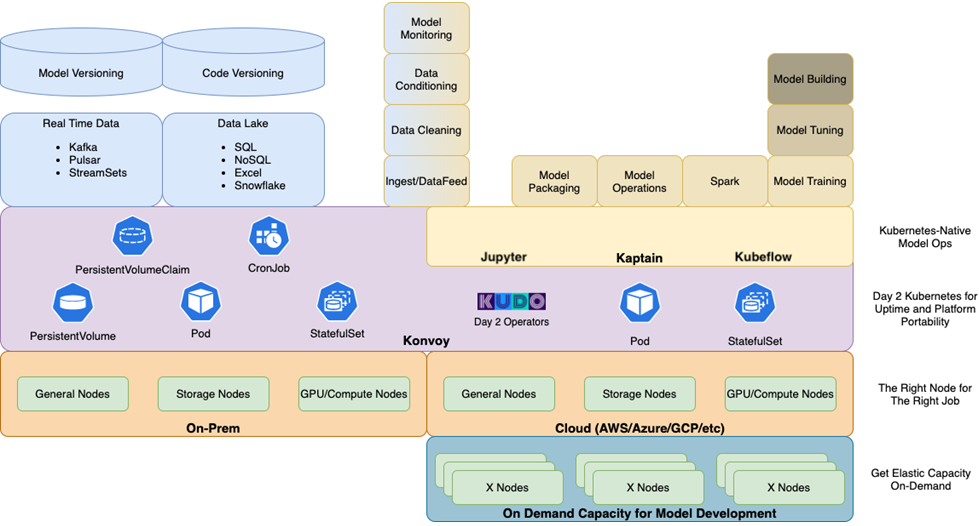
Figure 2 – Kaptain deployment reference architecture.
Kaptain solved three big problems for the organization:
- First, Kaptain provided data scientists with a notebooks-first approach to their work. This insulated them from the complexities of the underlying infrastructure, thus saving time and improving their productivity.
- Second, Kaptain allowed the customer’s IT team to provide internal data scientists with an ML platform as a service, cutting the time required to provision infrastructure from days to hours. The infrastructure-agnostic portability and scalability of Kubernetes enabled the IT team to place workloads where it made the most sense for them, on AWS or in their data centers.
- Finally, because Kaptain (and its Kubernetes underpinnings) works the same everywhere and provides a uniform user experience irrespective of the underlying platform, types of work affected by data gravity (for example, training models on huge data sets) could be done where they made the most sense.
Plus, D2iQ’s expert support and training services extend the reach of the organization’s IT team and help them maximize the satisfaction of their internal data scientist and data engineer customers.
Conclusion
D2iQ Kaptain enables data scientists and data engineers to harness the scalability and flexibility of Kubernetes without having to struggle with its complexity.
D2iQ Kaptain and the Kaptain SDK provide a notebooks-first approach to managing the entire machine learning lifecycle, from model development to training, deployment, tuning, and maintenance.
By reducing the complexity and friction of getting ML models from development to production, Kaptain helps organizations increase the share of models actually being implemented and providing positive returns on investment.
To learn more about D2iQ Kaptain, see a demo, or arrange a free trial, please visit the Kaptain website.
.

.
D2iQ – AWS Partner Spotlight
D2iQ is an AWS Containers Competency Partner that delivers a leading independent platform for enterprise-grade Kubernetes.
Contact D2iQ | Partner Overview
*Already worked with D2iQ? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.