AWS Partner Network (APN) Blog
Partitioning Pooled Multi-Tenant SaaS Data with Amazon DynamoDB
By Anubhav Sharma, Sr. Partner Solutions Architect, AWS SaaS Factory
By Tod Golding, Principal Partner Solutions Architect, AWS SaaS Factory
 As you design, develop, and build software-as-a-service (SaaS) solutions on Amazon Web Services (AWS), you must think about how you want to partition the data that belongs to each of your customers, which are commonly referred to as tenants in a SaaS environment.
As you design, develop, and build software-as-a-service (SaaS) solutions on Amazon Web Services (AWS), you must think about how you want to partition the data that belongs to each of your customers, which are commonly referred to as tenants in a SaaS environment.
There are several factors (noisy neighbor and data isolation, for example) that influence how you choose to store tenant data. You may choose to store your data in separate storage constructs using a “silo” model, or you may choose to comingle your data in a “pool” model.
We are both Partner Solutions Architect for AWS SaaS Factory, an AWS Partner Network (APN) program that helps organizations maximize innovation and agility by building on AWS.
In this post, we’ll focus on what it means to implement the pooled model with Amazon DynamoDB. Our goal is to find a way to effectively distribute tenant data within a single DynamoDB table and prevent cross tenant data access.
We’ll outline some basic strategies to partition and isolate data by tenant. We will also illustrate common techniques you can use to avoid the “hot” partition problem that’s often associated with partitioning tenant data in a pooled model.
Silo vs. Pool Model
A silo model often represents the simplest path forward if you have compliance or other isolation needs and want to avoid noisy neighbor conditions.
You can implement a silo model inside Amazon DynamoDB by having separate tables per tenant. By placing each tenant in their own DynamoDB table, you can better constrain the scope and impact of each tenant, and you can tune table settings per tenant needs.
However, the distributed nature of the silo model also introduces management and agility challenges, especially if you have many small size tenants. Updates, for example, must now be applied separately to each table. Onboarding also requires additional provisioning steps.
The pool model trades the simplicity of natural isolation for efficiency and agility. In a pool model, all your data can reside in a single DynamoDB table, segregated by tenant identifiers. This allows you to manage and update all tenants as part of a single construct. This also eliminates the need to map tenants to individual tables at run-time for each incoming read or write request.
Of course, there are some considerations associated with using the pool model. As you comingle tenant data in the same table, your chances increase for noisy neighbor conditions and security concerns.
The Partitioning Scheme
Before we dig into specific strategies, let’s start by talking about how data is generally partitioned in a pooled model. The basic idea of the pooled model is the data for all tenants is stored in a single Amazon DynamoDB table and identified using a tenant identifier, such as TenantID.
One obvious way to achieve this would be to add TenantID as the partition key. The following example shows how you might partition pooled data from an e-commerce solution that holds product catalogs for each tenant. We placed the TenantID in the partition key, and ProductID now becomes the sort key.

Figure 1 – Partitioning an Amazon DynamoDB table by TenantID.
While this is generally a reasonable approach to segregate the data, you must also think about how the footprint of tenant data in a pool model impacts the overall experience of your system.
It’s important to understand how the partition key design influences the underlying data distribution within physical partitions inside Amazon DynamoDB. In the preceding example, based upon the TenantID partition key, all the tenant data for any given tenant will be stored together inside a DynamoDB physical partition.
Now, imagine you have a tenant (or tenants) that have a large number of orders, and your system supports operations that read or write these orders at large scale. In these scenarios, you may find certain tenants could be processing requests at levels that exceed the DynamoDB throughput limits of 1,000 write capacity units (WCU) and 3,000 read capacity units (RCU) for any given partition.
This not only impacts the tenant in question, but also other tenants stored inside that partition, causing a noisy neighbor effect, and eventually degrading the overall experience of your SaaS application.
This is the challenge of the pool model. How do you support these use cases where the number of items you want to read for the larger tenants can be supported without somehow impacting the experience of other tenants?
The basic goal here is to avoid structuring data and operations in a pattern that might introduce a noisy neighbor condition.
Addressing the “Hot Partition” Challenge
The principle behind a hot partition is that the representation of your data causes a given partition to receive a higher volume of read or write traffic (compared to other partitions). This is especially significant in pooled multi-tenant environments where the use of a tenant identifier as a partition key could concentrate data in a given partition.
To remediate this problem, you need to alter your partition key scheme in a way that will better distribute tenant data across multiple partitions, and limit your chances of hitting the hot partition problem.
The idea here is to augment your partition key, by adding a suffix to the original tenant identifier. This approach strikes a good balance, distributing the data while still allowing you to easily reference of all the items that belong to a tenant.
The documentation for Amazon DynamoDB provides more details about this approach. The goal is to add a random or calculated suffix to your Tenant ID. Assuming you’ve taken this approach, your table partition key would now reflect this suffix. A simplified version is show below.
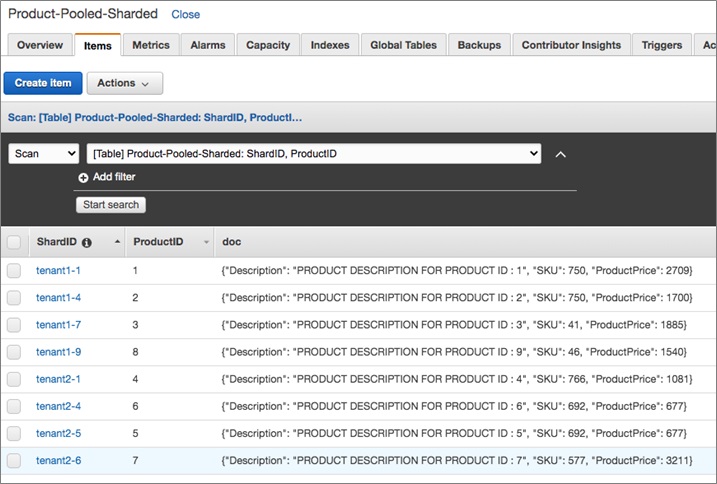
Figure 2 – Partition keys showing suffixes added to TenantID.
In this example, we created a “ShardID” that represents the combination of TenantID and the suffix. For example, tenant1 now has four partition keys—tenant1-1, tenant1-4, tenant1-7 and tenant1-9—instead of single tenant1 partition key.
In this scenario, the suffix is randomized based upon a predefined range of 1 to 10. You can assign a random suffix (within this range) while writing data to the Amazon DynamoDB table, inside your data access layer.
You could, instead, use a hash of ProductID as the suffix. In either case, the idea is to add a suffix to the TenantID as a way of evenly distributing the tenant data across partitions. It would also be a good idea to keep the suffix range, for a given tenant, in a separate mapping table. You could then use this mapping table to access data for that tenant.
The introduction of this suffix does change how you access the data. For example, to retrieve tenant1’s data, you would construct a query that represented the union of all suffix values for that tenant. This would ensure your results included all the items that were associated with that tenant.
You can do this by querying all the partitions for that tenant, in parallel, using separate worker processes, like this:
Limit Cross-Tenant Access by Applying Fine-Grained Access Control
Now that you have adopted a data partitioning strategy for your multi-tenant table, let’s focus on implementing an isolation strategy to prevent cross-tenant data access.
Let’s use an example to illustrate the problem. In the following scenario, your code is trying to write some data for tenant1 inside the Product-Pooled-Sharded table:
On the surface, this code seems well-behaved. It simply creates an Amazon DynamoDB client and inserts one item into the table. In this model, there is nothing that constrains your interactions with this table.
In fact, you could change the TenantID to another value in your code and it would still work. The following line of code illustrates this problem.
To avoid this problem, introduce fine-grained access control to scope your DynamoDB client. This scoping ensures that one tenant can’t access the DynamoDB items that belong to another tenant.
To begin, create an identity and access management (IAM) policy that helps scope access to our DynamoDB items. Since all our partition keys have a format of TenantID-SuffixID, it becomes easy to create an IAM policy that helps you do exactly what you want.
The following IAM policy shows how this could be implemented:
Notice this policy introduces a condition attribute. This condition includes a StringLike expression that requires all items to have a LeadingKey that matches the pattern (in this case, tenantID-*). This policy supports any range of suffixes for your tenant, and prevents your policy from being tightly coupled to the suffix scheme implemented in your application.
Now that the policy is in place, let’s look at how this influences the code that appears in your application. Here is an updated version of your application code:
This code uses AWS Security Token Service (AWS STS) to assume a AccessDynamoWithTenantContext role. This IAM role has been created with a policy that allows it to write data to Amazon DynamoDB. The preceding code now has an extra step to further restrict the scope of this role, by passing a more restrictive policy statement along with the tenant context.
Now the code that follows manages items in your DynamoDB table, and all interactions will be constrained to what is valid for the policy that was used. This prevents any attempt to access data for another tenant. With this approach of dynamically injecting tenant context, you also avoid creating a separate role for each tenant.
Conclusion
There are multiple factors you need to think about when picking a strategy for storing multi-tenant data with Amazon DynamoDB. This is often about finding the right balance of isolation, performance, compliance, and noisy neighbor considerations.
For this post, we focused on the “pool” model with the goal of highlighting the potential impacts of comingling data within the same table. The key here was to come up with an effective partitioning strategy to minimize the “hot partition” problem and provide tighter data isolation boundaries, without dramatically impacting the developer experience.
This approach is especially valuable in environments where some subset of tenant may be imposing a disproportionately large load on your pooled DynamoDB table. It can also help with managing tenant-level SLA requirements.
You may also find that, in some cases, your tenants could be better served by using separate tables per tenant in a silo model. In fact, one table per tenant, along with on-demand capacity mode could be a compelling case for SaaS providers. In this case, however, you’d need to think about how that would impact the manageability and operational efficiency of your SaaS environment.
It’s also worth noting that partitioning strategies often vary for each AWS service. You may want to read our SaaS Storage Strategies whitepaper to get more information on the various SaaS data partitioning models that are available on AWS.
Learn More About AWS SaaS Factory
APN Technology Partners are encouraged to reach out to their APN representative to inquire about working with the AWS SaaS Factory team. Additional technical and business best practices can be accessed via the AWS SaaS Factory website.
ISVs that are not APN Partners can subscribe to the SaaS on AWS email list to receive updates about upcoming events, content launches, and program offerings.

About AWS SaaS Factory
AWS SaaS Factory helps organizations at any stage of the SaaS journey. Whether looking to build new products, migrate existing applications, or optimize SaaS solutions on AWS, we can help. Visit the AWS SaaS Factory Insights Hub to discover more technical and business content and best practices.
SaaS builders are encouraged to reach out to their account representative to inquire about engagement models and to work with the AWS SaaS Factory team.
Sign up to stay informed about the latest SaaS on AWS news, resources, and events.