AWS Partner Network (APN) Blog
The Future of Search: Exploring Generative AI Chat-Based Solutions with AWS and Slalom
By Jack McCush, Sr. Principal Data Scientist – Slalom
Andre Boaventura, Principal Partner Solutions Architect, Global Generative AI Specialist – AWS
Gopal Krishna Bhatia, Sr. Partner Solutions Architect, Data & AI Specialist – AWS
 |
| Slalom |
 |
In a recent webinar, Slalom and Amazon Web Services (AWS) showcased the incredible potential of chat-based enterprise search powered by AWS generative artificial intelligence (AI) services like Amazon Bedrock. We are excited to share key takeaways and a more in-depth exploration of the transformative landscape that chat-based search creates.
Slalom is an AWS Premier Tier Services Partner with Competencies in Machine Learning, Data and Analytics, DevOps, Security, and more. From strategy to implementation, Slalom deeply understands its customers—and their customers—to deliver practical, end-to-end solutions that drive meaningful impact.
In the digital age, data is the backbone of decision making, as organizations are constantly seeking ways to efficiently access and extract insights from the massive amounts of data they accumulate. Traditional search methods have served us well, but chat-based solutions have ushered in a new era of search capabilities.
Imagine typing a question about your company’s financial performance and receiving accurate and contextually relevant results. What about finding a favorite pair of running shoes without having to go through dozens of filters on a website? Or even booking a cruise without browsing many pages and clicking on all the options?
That’s the power of chat-based search, and generative AI is at the heart of this innovation. Technologies like Amazon Bedrock empower businesses to build intelligent chat-based interfaces that allow employees to interact with company data conversationally.
Real-World Applications and Transformative Use Cases
During the webinar, Slalom experts presented real-world use cases highlighting the versatility and impact of chat-based search across industries.
- In travel and hospitality, for instance, organizations can employ chat-based interfaces to enhance customer experiences by quickly providing travel recommendations, booking information, and more.
- Retail businesses can leverage these solutions to create personalized shopping experiences, making it easier for customers to find products that align with their preferences.
- Financial services companies can harness the power of chat-based search to facilitate complex financial data analysis and reporting, streamlining decision-making processes.
- In healthcare, chatbots can be used to assist patients with scheduling, reduce wait time for critical patients, and even assess minor symptoms over the phone.
Implementing and Optimizing Chat-Based Search
Implementing chat-based search requires a strategic approach. As Slalom experts shared in the webinar, the following best practices ensure successful deployment:
- Understand user needs: Understand your users’ specific needs and preferences. What questions are they likely to ask? What pain points can chat-based search alleviate?
- Design natural conversations: Craft conversational interfaces that mimic natural human interactions. The goal is to create a seamless experience that feels intuitive and effortless.
- Data preparation: Ensure your data is structured and organized, as this directly impacts the accuracy of search results. Clean, well-organized data enhances the effectiveness of chat-based search models.
- Continuous learning: Chat-based search systems can learn and improve over time. Implement mechanisms to gather user feedback and iteratively refine the system based on user interactions.
AWS Options for Retrieval-Augmented Generation
What’s made this new era of search possible is a groundbreaking innovation known as retrieval-augmented generation (RAG), which seamlessly merges two components—retrieval and generation—to create a remarkably sophisticated and functional search experience.
At its core, RAG architecture leverages the strength of retrieval models to swiftly pinpoint relevant documents or pieces of information from a vast corpus. This initial retrieval stage ensures the system can quickly identify items the user seeks with natural-language inputs.
Here’s where the magic happens: the generation component of RAG architecture not only returns the items but, through prompt engineering and configuration, allows an organization to guide the user with responses that read and feel natural, akin to an authentic conversation between humans. This transformative process bridges the gap between raw data and user-friendly insights, elevating the conversational search experience.
In essence, RAG architecture enables users to engage with search systems conversationally. It empowers users to pose questions, seek clarification, and obtain valuable information effortlessly, mirroring the experience of interacting with an expert. Below, you will see an example of a RAG minimum viable product (MVP) solution architecture.
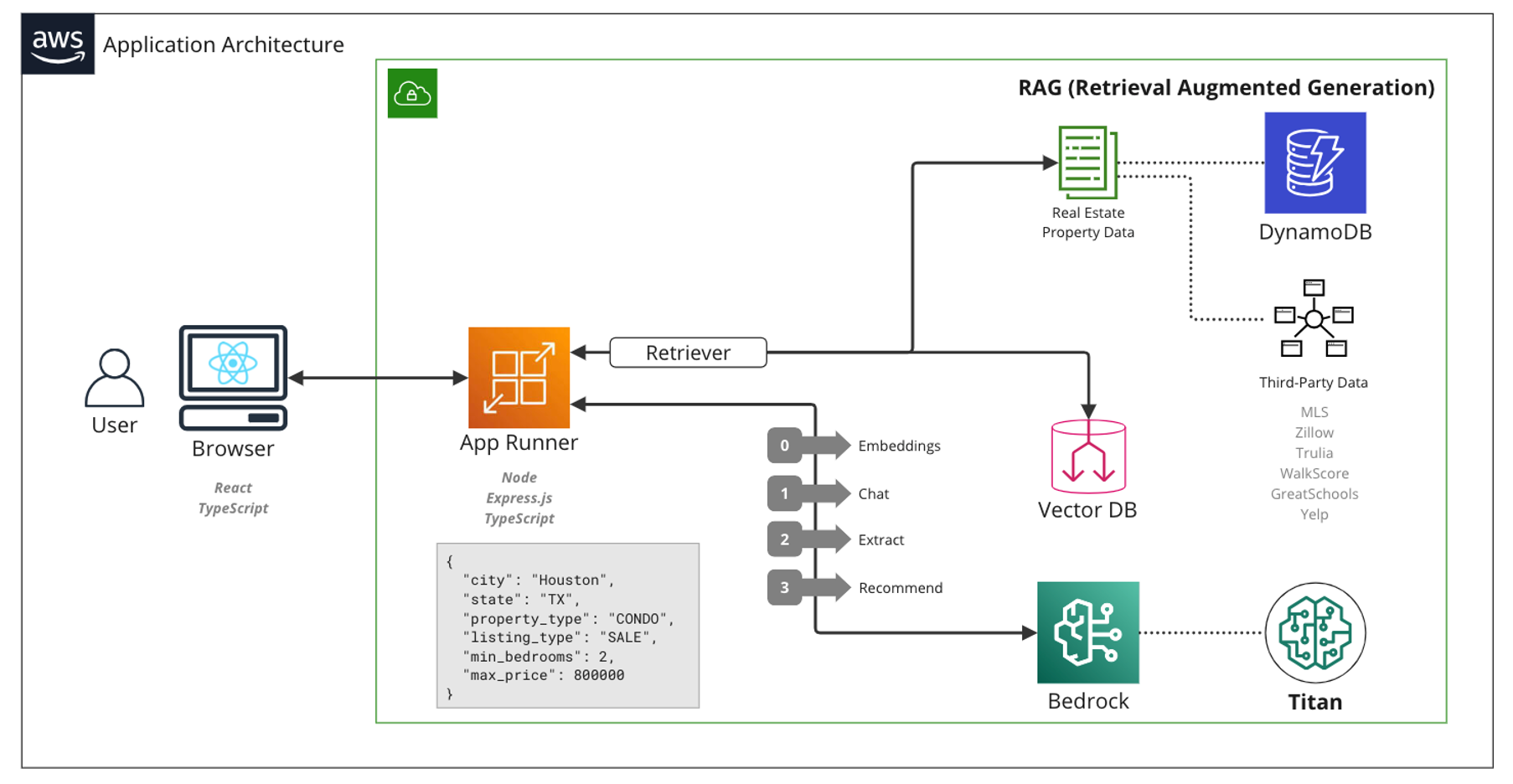
Figure 1 – RAG solution-based architecture.
Whether employed for ecommerce site search to enhance customer exploration or for enterprise search to streamline employee retrieval of information within complex datasets, RAG architecture is an avenue for more intuitive, informative, and engaging interactions. This approach is reshaping how we navigate and extract value from the information available to us.
When deploying a chat-based search application, several architectural decisions exist apart from the frontend design, embeddings, and data storage. Focusing on the foundation model (FM) and whether to use a fully managed API service or self-hosted model endpoint is a big part of the decision-making required to build RAG architecture.
With AWS, you have the option of Amazon Bedrock for a fully managed FM API service, or the self-hosted models available within Amazon SageMaker, specifically Amazon SageMaker Jumpstart. Each approach has its strengths and considerations.
The selection of the vector database is also of utmost importance when considering the RAG architecture, as it plays a critical role in efficiently storing and retrieving high-dimensional representations of textual data. At a high level, the RAG-based architecture consists of two key components: a retriever and a generator.
The retriever leverages vector databases to swiftly search and retrieve pertinent passages or documents from a vast corpus of text, based on user queries. These retrieved passages then serve to enhance the generator’s knowledge, providing valuable context and information for generating accurate and contextually relevant responses. Consequently, this improved retrieval process improves the quality of responses generated by the RAG model, thereby enhancing the overall effectiveness and user-friendliness of the chat-based application.
Let’s delve into a comparative analysis to help you make an informed choice that aligns with your project’s requirements.
Amazon Bedrock FM API Service: The Power of Managed Simplicity
Amazon Bedrock makes FMs available through an API, which presents a compelling proposition for those seeking streamlined accessibility to advanced AI capabilities. With a fully managed service, you’re relieved from the complexities of model deployment, infrastructure management, and scalability concerns.
Here’s a closer look at Amazon Bedrock’s benefits:
- Ease of use: The API-based approach abstracts the underlying infrastructure, allowing you to integrate AI functionalities into your applications with just a few lines of code. The managed nature of Amazon Bedrock ensures you can focus on your application’s logic rather than the intricacies of model hosting.
- Rapid deployment: Leveraging a fully managed model reduces the time required for deployment. Amazon Bedrock provides resources, load balancing, and other operational support, enabling you to get your AI-powered features to market faster.
- Scalability: As user demand grows, the scalability of Amazon Bedrock becomes a distinct advantage. The service can automatically handle increased traffic and adjust resources accordingly, ensuring consistent performance even during usage spikes.
- Managed updates: AI models require periodic updates to stay accurate and relevant. Amazon Bedrock handles these updates seamlessly, ensuring your AI capabilities remain current without disrupting your applications.
- Predictable costs: Managed services often provide predictable pricing models. With Amazon Bedrock, you pay for the resources you use, eliminating the need to overprovision to account for potential surges in usage.
- Data security: With the API-based access to third-party providers, security is always key to ensure the data is not being shared. With Amazon Bedrock, your data is encrypted at rest and in transit and developers can establish private connectivity between virtual private clouds (VPCs) and the Amazon Bedrock service using VPC endpoints
Leveraging Amazon Bedrock Knowledge Base
With the new knowledge bases capability in Amazon Bedrock, developers have an end-to-end managed service to easily enable RAG workflows for their generative AI applications on AWS, unlocking new possibilities for creating intelligent chat-based solutions.
Knowledge bases simplify the process of making company data accessible to Amazon Bedrock agents to efficiently retrieve and incorporate relevant contextual information from company data sources into the input prompts for foundation models, which prevents the need to continuously retrain models each time new data is added. This augmented data provides more focused context that improves the relevance, accuracy, and specificity of model completions.
Developers only need to specify the location of their data (for example, company documents stored in Amazon S3), select an embedding model such as Amazon Titan embeddings, and provide details of their vector database. Amazon Bedrock then handles ingesting the data, generating vector embeddings, populating the vector database, and keeping embeddings updated as new data is added.
For vector databases, developers can leverage fully managed options like vector engines for Amazon OpenSearch Serverless, Redis Enterprise Cloud, and Pinecone, which removes overhead of deploying and managing that infrastructure. Thus, pairing knowledge bases with Amazon Bedrock’s managed agents streamlines prompt engineering by automatically retrieving and integrating relevant data into the input based on user queries, as depicted below.
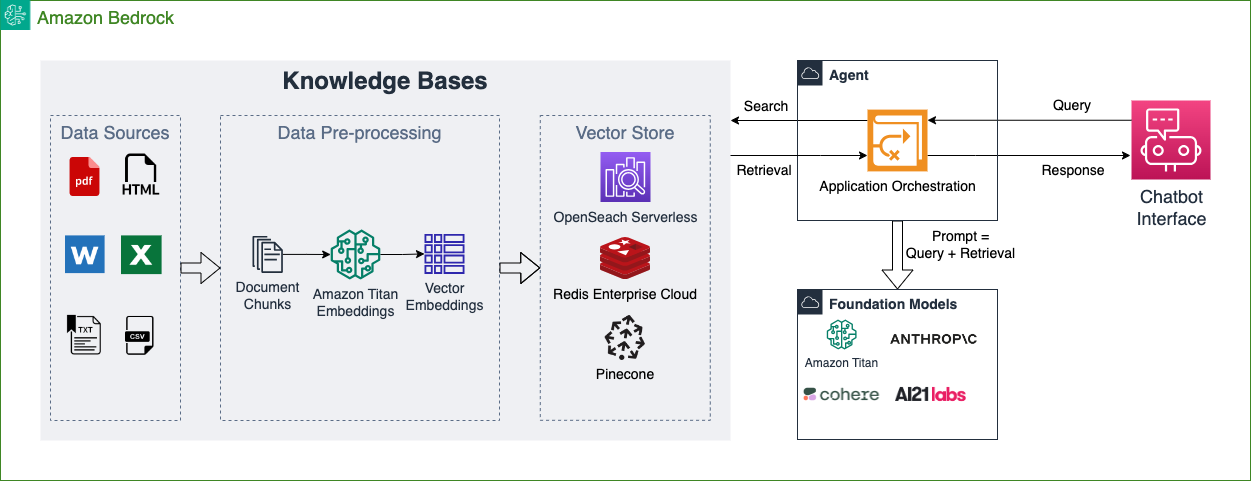
Figure 2 – Knowledge bases and agents for Amazon Bedrock.
As a result, Amazon Bedrock knowledge bases eliminate many complex components of enabling RAG. Companies no longer have to build custom pipelines for data ingestion, embedding generation, and database population. The automation and abstraction provided by the knowledge base lets developers focus on the application logic and prompt engineering while leveraging RAG’s benefits. This streamlines deploying generative AI that dynamically taps into up-to-date company data to boost relevance.
Self-Hosted Models in Amazon SageMaker JumpStart
For those seeking higher customization and control, self-hosted models within Amazon SageMaker JumpStart offer a tailored solution. While they require more hands-on management, they also provide benefits that cater to specific needs:
- Customization: Self-hosted models allow you to fine-tune the infrastructure and configurations to match your application’s unique requirements. This level of control is ideal for projects with specialized needs or proprietary algorithms.
- Data privacy and security: Some applications demand strict data privacy and security measures. Hosting models within your Amazon SageMaker environment can provide greater control over data access and handling.
- Cost optimization: While self-hosted models require more management effort, they can also lead to cost optimization if you have the expertise to fine-tune resource allocation based on your application’s requirements.
- Experimentation: Self-hosted models provide an environment conducive to experimentation and research. You can easily swap out model components, evaluate different frameworks, and optimize performance based on your needs.
Choosing the Right Fit
The choice between Amazon Bedrock and self-hosted models in Amazon SageMaker JumpStart depends on your project’s priorities. If simplicity, rapid deployment, and automatic scaling are paramount, Amazon Bedrock is a strong contender. On the other hand, if your project requires deep customization, control over infrastructure, or specialized security measures, self-hosted models in SageMaker JumpStart offer the flexibility you need.
Ultimately, the decision comes down to your project’s unique needs, your team’s expertise, and the balance between ease of use and fine-tuned control. Whichever path you choose, AWS provides the tools and services to empower you in harnessing the power of AI for your applications.
The benefits of adopting chat-based enterprise search solutions are undeniable. Businesses can experience improved user engagement and higher conversion and retention rates. The natural language inputs often glean more customer details that companies can mine and add relevant information to a customer’s profile for future targeting purposes.
That said, it’s essential to be aware of potential challenges such as fine-tuning the chat models to ensure accurate responses, addressing privacy concerns, and providing clear guidance for users needing to become more familiar with chat-based interfaces.
Getting Started
This joint effort, centered around generative AI, aims to expedite the time-to-value for Slalom and AWS’s shared customers. It builds upon the long-standing strategic collaboration between the two companies and harnesses the proven mechanisms and accelerators developed by Slalom.
Slalom has developed a workshop on chat-based enterprise search with AWS generative AI services like Amazon Bedrock and Amazon SageMaker, which provides customers with the knowledge to understand large language models and how the AWS generative AI technologies work. It also delves into the intricacies of chat-based enterprise search and its transformative potential for organizations, helping unlock real business value.
Embracing the Future of Search
As we wrap up this exploration into the future of search, it’s evident that chat-based solutions, fueled by retrieval-augmented generation and powerful generative AI services like Amazon Bedrock and Amazon SageMaker JumpStart are poised to redefine how organizations harness their data. The ability to interact with data conversationally empowers users across industries to glean insights, make informed decisions, and enhance customer experiences like never before.
Slalom and AWS are leading the way in this exciting evolution of search. The journey to leveraging chat-based search starts with understanding its potential, discovering its applications, and implementing best practices.
.

.
Slalom – AWS Partner Spotlight
Slalom is an AWS Premier Tier Services Partner with Competencies in Machine Learning, Data and Analytics, DevOps, Security, and more. From strategy to implementation, Slalom deeply understands its customers—and their customers—to deliver practical, end-to-end solutions that drive meaningful impact.
Contact Slalom | Partner Overview | AWS Marketplace | Case Studies