AWS Architecture Blog
AWS Storage Update: Amazon S3 & Amazon S3 Glacier Launch Announcements for Archival Workloads
By Matt Sidley, Senior Product Manager for S3
Customers have built archival workloads for several years using a combination of S3 storage classes, including S3 Standard, S3 Standard-Infrequent Access, and S3 Glacier. For example, many media companies are using the S3 Glacier storage class to store their core media archives. Most of this data is rarely accessed, but when they need data back (for example, because of breaking news), they need it within minutes. These customers have found S3 Glacier to be a great fit because they can retrieve data in 1-5 minutes and save up to 82% on their storage costs. Other customers in the financial services industry use S3 Standard to store recently generated data, and lifecycle older data to S3 Glacier.
We launched Glacier in 2012 as a secure, durable, and low-cost service to archive data. Customers can use Glacier either as an S3 storage class or through its direct API. Using the S3 Glacier storage class is popular because many applications are built to use the S3 API and with a simple lifecycle policy, older data can be easily shifted to S3 Glacier. S3 Glacier continues to be the lowest-cost storage from any major cloud provider that durably stores data across three Availability Zones or more and allows customers to retrieve their data in minutes.
We’re constantly listening to customer feedback and looking for ways to make it easier to build applications in the cloud. Today we’re announcing six new features across Amazon S3 and S3 Glacier.
Amazon S3 Object Lock
S3 Object Lock is a new feature that prevents data from being deleted during a customer-defined retention period. You can use Object Lock with any S3 storage class, including S3 Glacier. There are many use cases for S3 Object Lock, including customers who want additional safeguards for data that must be retained, and for customers migrating from existing write-once-read-many (WORM) systems to AWS. You can also use S3 Lifecycle policies to transition data and S3 Object Lock will maintain WORM protection as your data is tiered.
S3 Object Lock can be configured in one of two modes: Governance or Compliance. When deployed in Governance mode, only AWS accounts with specific IAM permissions are able to remove the lock. If you require stronger immutability to comply with regulations, you can use Compliance mode. In Compliance mode, the lock cannot be removed by any user, including the root account. Take a look here:
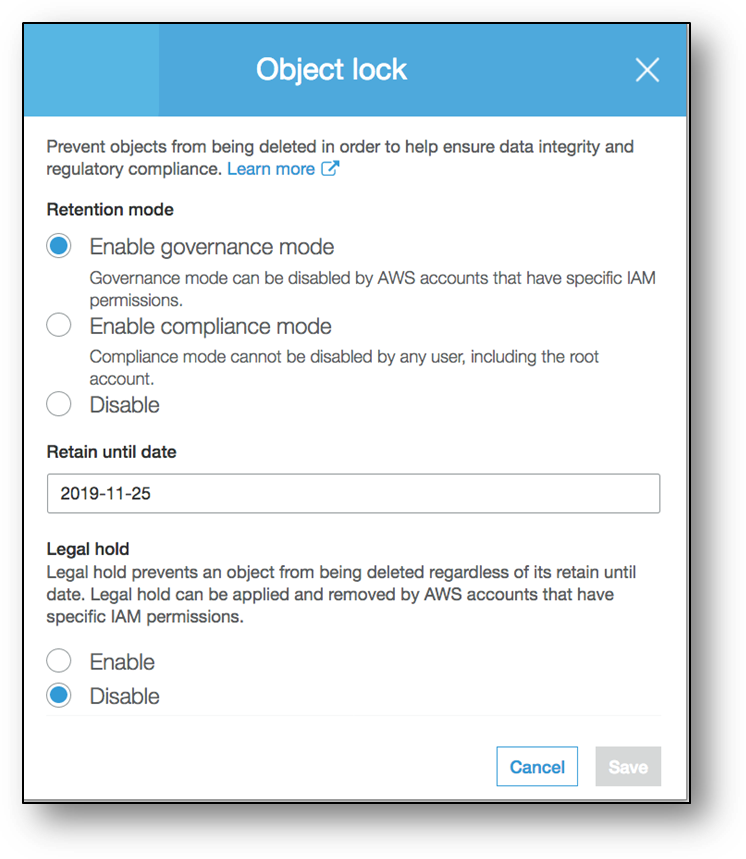
S3 Object Lock is helpful in industries where long-term records retention is mandated by regulations or compliance rules. S3 Object Lock has been assessed for SEC Rule 17a-4(f), FINRA Rule 4511, and CFTC Regulation 1.31 by Cohasset Associates. Cohasset Associates is a management consulting firm specializing in records management and information governance. Read more and find a copy of the Cohasset Associates Assessment report in our documentation here.
New S3 Glacier Features
One of the things we hear from customers about using S3 Glacier is that they prefer to use the most common S3 APIs to operate directly on S3 Glacier objects. Today we’re announcing the availability of S3 PUT to Glacier, which enables you to use the standard S3 “PUT” API and select any storage class, including S3 Glacier, to store the data. Data can be stored directly in S3 Glacier, eliminating the need to upload to S3 Standard and immediately transition to S3 Glacier with a zero-day lifecycle policy. You can “PUT” to S3 Glacier like any other S3 storage class:

Many customers also want to keep a low-cost durable copy of their data in a second region for disaster recovery. We’re also announcing the launch of S3 Cross-Region Replication to S3 Glacier. You can now directly replicate data into the S3 Glacier storage class in a different AWS region.
Restoring Data from S3 Glacier
S3 Glacier provides three restore speeds for you to access your data: expedited (to retrieve data in 1-5 minutes), standard (3-5 hours), or bulk (5-12 hours). With S3 Restore Speed Upgrade, you can now issue a second restore request at a faster restore speed and get your data back sooner. This is useful if you originally requested standard or bulk speed, but later determine that you need a faster restore speed.
After a restore from S3 Glacier has been requested, you likely want to know when the restore completes. Now, with S3 Restore Notifications, you’ll receive a notification when the restoration has completed and the data is available. Many applications today are being built using AWS Lambda and event-driven actions, and you can now use the restore notification to automatically trigger the next step in your application as soon as S3 Glacier data is restored. For example, you can use notifications and Lambda functions to package and fulfill digital orders using archives restored from S3 Glacier.
Here, I’ve set up notifications to fire when my restores complete so I can use Lambda to kick off a piece of analysis I need to run:

You might need to restore many objects from S3 Glacier; for example, to pull all of your log files within a given time range. Using the new feature in Preview, you can provide a manifest of those log files to restore and, with one request, initiate a restore on millions or even trillions of objects just as easily as you can on just a few. S3 Batch Operations automatically manages retries, tracks progress, sends notifications, generates completion reports, and delivers events to AWS CloudTrail for all changes made and tasks executed.
To get started with the new features on Amazon S3, visit https://aws.amazon.com/s3/. We’re excited about these improvements and think they’ll make it even easier to build archival applications using Amazon S3 and S3 Glacier. And we’re not yet done. Stay tuned, as we have even more coming!