AWS Architecture Blog
Category: Kinesis Data Firehose

Building a healthcare data pipeline on AWS with IBM Cloud Pak for Data
Healthcare data is being generated at an increased rate with the proliferation of connected medical devices and clinical systems. Some examples of these data are time-sensitive patient information, including results of laboratory tests, pathology reports, X-rays, digital imaging, and medical devices to monitor a patient’s vital signs, such as blood pressure, heart rate, and temperature. […]

Maintain visibility over the use of cloud architecture patterns
Cloud platform and enterprise architecture teams use architecture patterns to provide guidance for different use cases. Cloud architecture patterns are typically aggregates of multiple Amazon Web Services (AWS) resources, such as Elastic Load Balancing with Amazon Elastic Compute Cloud, or Amazon Relational Database Service with Amazon ElastiCache. In a large organization, cloud platform teams often […]

Automating Anomaly Detection in Ecommerce Traffic Patterns
Many organizations with large ecommerce presences have procedures to detect major anomalies in their user traffic. Often, these processes use static alerts or manual monitoring. However, the ability to detect minor anomalies in traffic patterns near real-time can be challenging. Early detection of these minor anomalies in ecommerce traffic (such as website page visits and […]

Automate Amazon Connect Data Streaming using AWS CDK
Many customers want to provision Amazon Web Services (AWS) cloud resources quickly and consistently with lifecycle management, by treating infrastructure as code (IaC). Commonly used services are AWS CloudFormation and HashiCorp Terraform. Currently, customers set up Amazon Connect data streaming manually, as the service is not available under CloudFormation resource types. Customers may want to […]

Connecting an Industrial Universal Namespace to AWS IoT SiteWise using HighByte Intelligence Hub
This post was co-authored with Michael Brown, Sr. Manufacturing Specialist Architect, AWS; Dr. Rajesh Gomatam, Sr. Partner Solutions Architect, Industrial Software Specialist, AWS; Scott Robertson, Sr. Partner Solutions Architect, Manufacturing, AWS; John Harrington, Chief Business Officer, HighByte; and Aron Semie, Chief Technology Officer, HighByte Merging industrial and enterprise data across multiple on-premises deployments and industrial […]

Ingesting PI Historian data to AWS Cloud using AWS IoT Greengrass and PI Web Services
In process manufacturing, it’s important to fetch real-time data from data historians to support decisions-based analytics. Most manufacturing use cases require real-time data for early identification and mitigation of manufacturing issues. A limited set of commercial off-the-shelf (COTS) tools integrate with OSIsoft’s PI Historian for real-time data. However, each integration requires months of development effort, […]

How Cimpress Built a Self-service, API-driven Data Platform Ingestion Service
Cimpress is a global company that specializes in mass customization, empowering individuals and businesses to design, personalize and customize their own products – such as packaging, signage, masks, and clothing – and to buy those products affordably. Cimpress is composed of multiple businesses that have the option to use the Cimpress data platform. To provide […]

Amazon MSK Backup for Archival, Replay, or Analytics
Amazon MSK is a fully managed service that helps you build and run applications that use Apache Kafka to process streaming data. Apache Kafka is an open-source platform for building real-time streaming data pipelines and applications. With Amazon MSK, you can use native Apache Kafka APIs to populate data lakes. You can also stream changes to […]
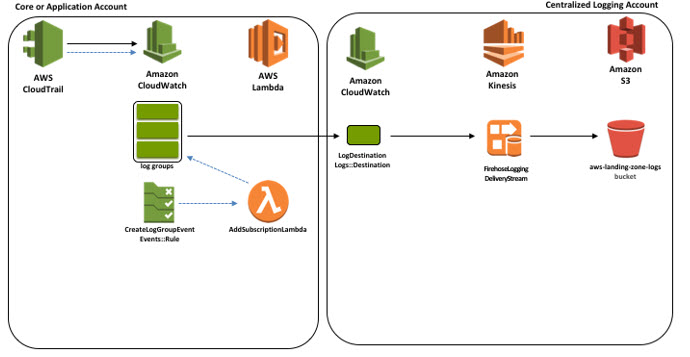
Stream Amazon CloudWatch Logs to a Centralized Account for Audit and Analysis
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. Note: This blog post was updated June 6, 2019. A key component of enterprise multi-account environments is logging. Centralized logging provides a single point of access to all salient logs generated across accounts and regions, and is critical for auditing, […]